Improving Multi-lingual Alignment Through Soft Contrastive Learning
2405.16155
0
0
Abstract
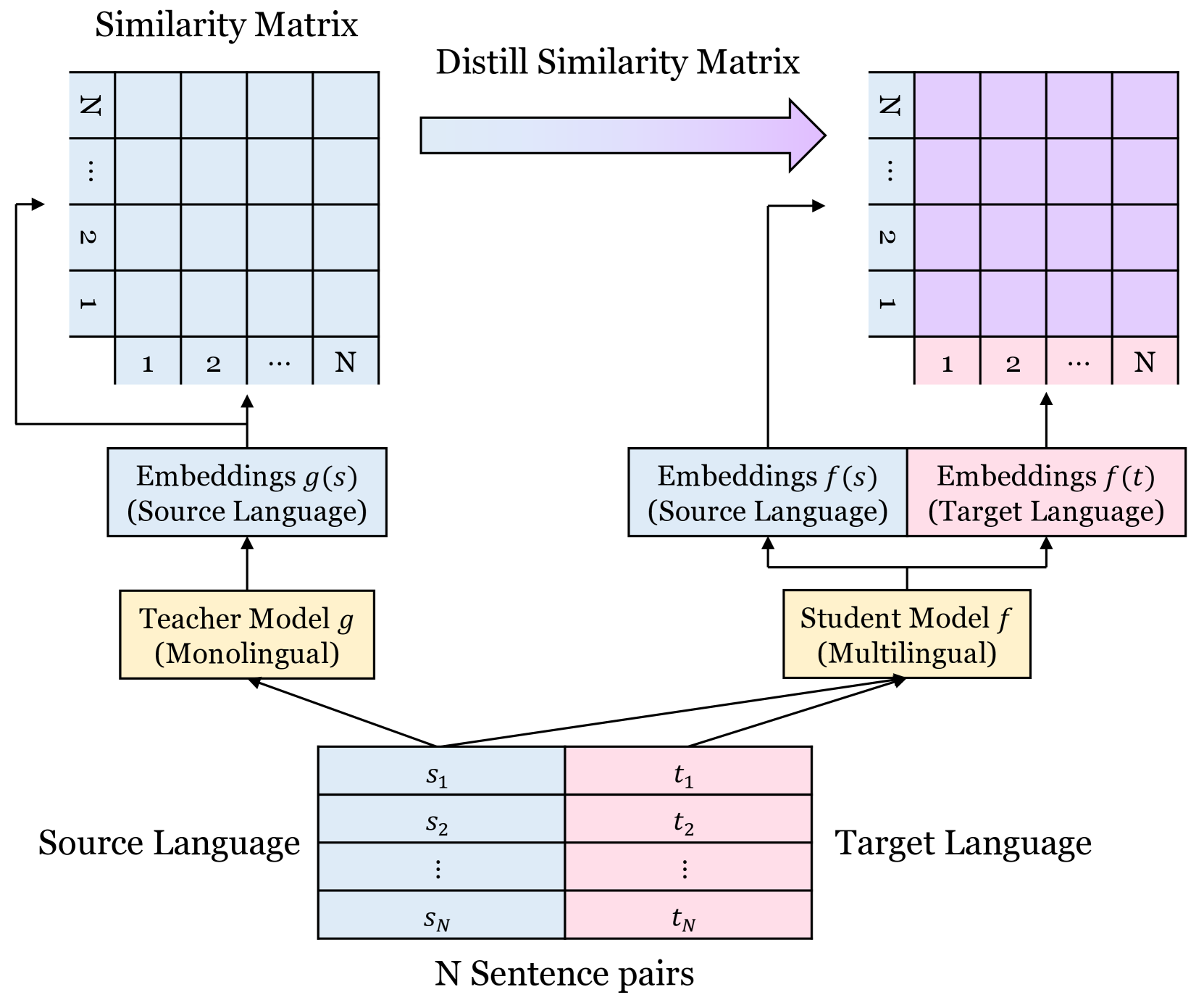
Making decent multi-lingual sentence representations is critical to achieve high performances in cross-lingual downstream tasks. In this work, we propose a novel method to align multi-lingual embeddings based on the similarity of sentences measured by a pre-trained mono-lingual embedding model. Given translation sentence pairs, we train a multi-lingual model in a way that the similarity between cross-lingual embeddings follows the similarity of sentences measured at the mono-lingual teacher model. Our method can be considered as contrastive learning with soft labels defined as the similarity between sentences. Our experimental results on five languages show that our contrastive loss with soft labels far outperforms conventional contrastive loss with hard labels in various benchmarks for bitext mining tasks and STS tasks. In addition, our method outperforms existing multi-lingual embeddings including LaBSE, for Tatoeba dataset. The code is available at https://github.com/YAI12xLinq-B/IMASCL
Create account to get full access
Overview
- This paper focuses on improving the alignment of multilingual language models by using a soft contrastive learning approach.
- The authors propose a novel training method called Soft Momentum Contrastive Learning (SoftMCL) that aims to enhance the cross-lingual understanding capabilities of large language models.
- SoftMCL builds on previous work on contrastive learning and multi-task learning to create a more effective cross-lingual alignment.
- The paper also explores the impact of different alignment strategies and the challenges of learning shared cross-lingual representations, as discussed in related research.
Plain English Explanation
The paper focuses on improving the ability of multilingual language models to understand and translate between different languages. The researchers propose a new training method called Soft Momentum Contrastive Learning (SoftMCL) that builds on previous work in contrastive learning and multi-task learning.
The key idea behind SoftMCL is to encourage the language model to learn representations that are aligned across languages, so that the same concept is represented similarly regardless of the language it's expressed in. This is done by adding a "soft" contrastive loss function that gently pushes the model to align related words and sentences in different languages, rather than forcing a hard alignment.
The paper explores how this soft contrastive approach compares to other cross-lingual alignment strategies, and discusses the challenges of getting large language models to effectively share representations across multiple languages. By addressing these challenges, the researchers aim to create language models that can better understand and translate between a wide range of languages.
Technical Explanation
The paper introduces a novel training method called Soft Momentum Contrastive Learning (SoftMCL) to improve the cross-lingual alignment of multilingual language models. SoftMCL builds on previous work in contrastive learning and multi-task learning to create a more effective approach to learning shared cross-lingual representations.
The key innovation of SoftMCL is the use of a "soft" contrastive loss function, rather than a hard alignment objective. This soft loss function encourages the model to align related words and sentences across languages, without forcing a strict one-to-one mapping. The authors hypothesize that this softer approach can lead to more robust and flexible cross-lingual representations.
To evaluate SoftMCL, the researchers conduct experiments on several cross-lingual benchmarks, including XNLI and PAWS-X. They compare SoftMCL to other cross-lingual alignment strategies, such as SOFTMCL and find that SoftMCL outperforms these baselines on a range of cross-lingual tasks.
The paper also provides insights into the impact of different alignment strategies and the challenges of learning shared cross-lingual representations, as discussed in related research. The authors note that further work is needed to fully understand the limitations and potential of their approach.
Critical Analysis
The paper presents a promising approach to improving the cross-lingual alignment of multilingual language models, but it also acknowledges several limitations and areas for further research.
One potential concern is the computational complexity of the SoftMCL training process, which may limit its scalability to larger models and datasets. The authors note that the soft contrastive loss function can be computationally expensive, and they suggest exploring ways to make the training more efficient.
Additionally, the paper focuses primarily on evaluating SoftMCL on cross-lingual benchmarks, but it does not provide a detailed analysis of how the resulting representations differ from those learned by other alignment approaches. A more in-depth exploration of the qualitative properties of the learned representations could help researchers better understand the strengths and weaknesses of the SoftMCL approach.
Further research is also needed to understand the broader implications of the SoftMCL method and how it might be applied to real-world multilingual NLP tasks, such as machine translation or cross-lingual information retrieval. The paper's findings are promising, but more work is needed to fully validate the practical impact of the proposed technique.
Conclusion
This paper presents a novel approach to improving the cross-lingual alignment of multilingual language models called Soft Momentum Contrastive Learning (SoftMCL). By using a soft contrastive loss function, SoftMCL aims to create more robust and flexible cross-lingual representations, outperforming other alignment strategies on a range of benchmarks.
The findings suggest that the SoftMCL approach has the potential to significantly enhance the cross-lingual understanding capabilities of large language models, with implications for a wide range of multilingual NLP applications. However, the paper also highlights the need for further research to address the computational complexity of the training process and to fully understand the qualitative properties of the learned representations.
Overall, this work represents an important step forward in the ongoing effort to develop more effective and versatile multilingual language models, with the ultimate goal of bridging the gap between human languages and enabling seamless cross-lingual communication and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Improving In-context Learning of Multilingual Generative Language Models with Cross-lingual Alignment
Chong Li, Shaonan Wang, Jiajun Zhang, Chengqing Zong
0
0
Multilingual generative models obtain remarkable cross-lingual in-context learning capabilities through pre-training on large-scale corpora. However, they still exhibit a performance bias toward high-resource languages and learn isolated distributions of multilingual sentence representations, which may hinder knowledge transfer across languages. To bridge this gap, we propose a simple yet effective cross-lingual alignment framework exploiting pairs of translation sentences. It aligns the internal sentence representations across different languages via multilingual contrastive learning and aligns outputs by following cross-lingual instructions in the target language. Experimental results show that even with less than 0.1 {textperthousand} of pre-training tokens, our alignment framework significantly boosts the cross-lingual abilities of generative language models and mitigates the performance gap. Further analyses reveal that it results in a better internal multilingual representation distribution of multilingual models.
6/13/2024
💬
Large Language Models can Contrastively Refine their Generation for Better Sentence Representation Learning
Huiming Wang, Zhaodonghui Li, Liying Cheng, Soh De Wen, Lidong Bing
0
0
Recently, large language models (LLMs) have emerged as a groundbreaking technology and their unparalleled text generation capabilities have sparked interest in their application to the fundamental sentence representation learning task. Existing methods have explored utilizing LLMs as data annotators to generate synthesized data for training contrastive learning based sentence embedding models such as SimCSE. However, since contrastive learning models are sensitive to the quality of sentence pairs, the effectiveness of these methods is largely influenced by the content generated from LLMs, highlighting the need for more refined generation in the context of sentence representation learning. Building upon this premise, we propose MultiCSR, a multi-level contrastive sentence representation learning framework that decomposes the process of prompting LLMs to generate a corpus for training base sentence embedding models into three stages (i.e., sentence generation, sentence pair construction, in-batch training) and refines the generated content at these three distinct stages, ensuring only high-quality sentence pairs are utilized to train a base contrastive learning model. Our extensive experiments reveal that MultiCSR enables a less advanced LLM to surpass the performance of ChatGPT, while applying it to ChatGPT achieves better state-of-the-art results. Comprehensive analyses further underscore the potential of our framework in various application scenarios and achieving better sentence representation learning with LLMs.
5/20/2024
✨
Linear Cross-Lingual Mapping of Sentence Embeddings
Oleg Vasilyev, Fumika Isono, John Bohannon
0
0
Semantics of a sentence is defined with much less ambiguity than semantics of a single word, and we assume that it should be better preserved by translation to another language. If multilingual sentence embeddings intend to represent sentence semantics, then the similarity between embeddings of any two sentences must be invariant with respect to translation. Based on this suggestion, we consider a simple linear cross-lingual mapping as a possible improvement of the multilingual embeddings. We also consider deviation from orthogonality conditions as a measure of deficiency of the embeddings.
6/28/2024
🤔
Improved Content Understanding With Effective Use of Multi-task Contrastive Learning
Akanksha Bindal, Sudarshan Ramanujam, Dave Golland, TJ Hazen, Tina Jiang, Fengyu Zhang, Peng Yan
0
0
In enhancing LinkedIn core content recommendation models, a significant challenge lies in improving their semantic understanding capabilities. This paper addresses the problem by leveraging multi-task learning, a method that has shown promise in various domains. We fine-tune a pre-trained, transformer-based LLM using multi-task contrastive learning with data from a diverse set of semantic labeling tasks. We observe positive transfer, leading to superior performance across all tasks when compared to training independently on each. Our model outperforms the baseline on zero shot learning and offers improved multilingual support, highlighting its potential for broader application. The specialized content embeddings produced by our model outperform generalized embeddings offered by OpenAI on Linkedin dataset and tasks. This work provides a robust foundation for vertical teams across LinkedIn to customize and fine-tune the LLM to their specific applications. Our work offers insights and best practices for the field to build on.
5/22/2024