IMWA: Iterative Model Weight Averaging Benefits Class-Imbalanced Learning Tasks
2404.16331
0
0
Abstract
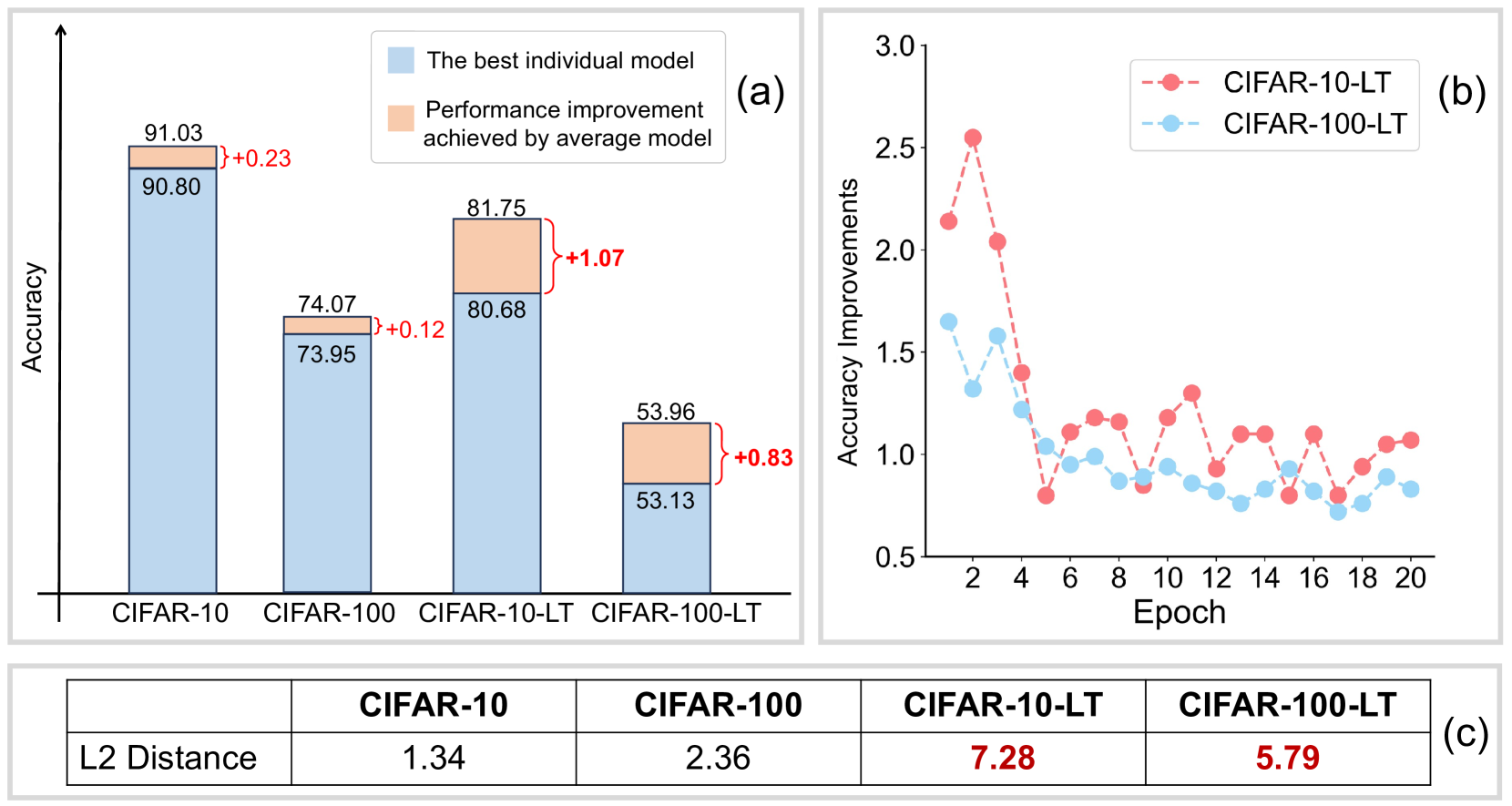
Model Weight Averaging (MWA) is a technique that seeks to enhance model's performance by averaging the weights of multiple trained models. This paper first empirically finds that 1) the vanilla MWA can benefit the class-imbalanced learning, and 2) performing model averaging in the early epochs of training yields a greater performance improvement than doing that in later epochs. Inspired by these two observations, in this paper we propose a novel MWA technique for class-imbalanced learning tasks named Iterative Model Weight Averaging (IMWA). Specifically, IMWA divides the entire training stage into multiple episodes. Within each episode, multiple models are concurrently trained from the same initialized model weight, and subsequently averaged into a singular model. Then, the weight of this average model serves as a fresh initialization for the ensuing episode, thus establishing an iterative learning paradigm. Compared to vanilla MWA, IMWA achieves higher performance improvements with the same computational cost. Moreover, IMWA can further enhance the performance of those methods employing EMA strategy, demonstrating that IMWA and EMA can complement each other. Extensive experiments on various class-imbalanced learning tasks, i.e., class-imbalanced image classification, semi-supervised class-imbalanced image classification and semi-supervised object detection tasks showcase the effectiveness of our IMWA.
Create account to get full access
Overview
- The paper explores the benefits of Iterative Model Weight Averaging (IMWA) for class-imbalanced learning tasks.
- IMWA is a technique that involves averaging the model weights during training to improve generalization.
- The authors demonstrate that IMWA can significantly boost the performance of deep learning models on datasets with skewed class distributions.
Plain English Explanation
Machine learning models often struggle when the dataset they are trained on has an unequal number of examples for each class, a common issue known as class imbalance. This paper investigates a technique called Iterative Model Weight Averaging (IMWA) that can help address this problem.
IMWA works by continuously averaging the model's weights during the training process. This helps the model learn a more balanced representation of the classes, even when the dataset is skewed. Imagine you're trying to train a model to recognize different types of flowers. If there are many more photos of roses than dandelions, the model may struggle to learn the features of the less common dandelion. By averaging the model's weights over time, IMWA can help the model pay more attention to the underrepresented dandelion class.
The authors of this paper show that IMWA can significantly improve the performance of deep learning models on a variety of class-imbalanced datasets. This is an important finding, as class imbalance is a common challenge in many real-world machine learning applications, such as detecting rare diseases or identifying unusual financial transactions. By using IMWA, machine learning practitioners can build more robust and accurate models, even when their data is skewed.
Technical Explanation
The paper introduces Iterative Model Weight Averaging (IMWA), a technique that can improve the performance of deep learning models on class-imbalanced datasets. IMWA works by continuously averaging the model weights during training, which helps the model learn a more balanced representation of the classes.
The authors conduct experiments on several benchmark datasets with varying degrees of class imbalance, including CIFAR-10, Camelyon16, and iNaturalist 2018. They compare the performance of standard training with IMWA and other weight averaging techniques, such as Exponentially Weighted Moving Models (EWMM) and Continual Learning via Weight Interpolation (CLWI).
The results show that IMWA consistently outperforms the other methods, leading to significant improvements in accuracy, F1-score, and other key metrics on the class-imbalanced datasets. The authors attribute this to IMWA's ability to learn a more balanced representation of the classes, preventing the model from becoming overly biased towards the majority class.
Critical Analysis
The paper provides a compelling demonstration of the benefits of IMWA for addressing class imbalance in deep learning. However, the authors acknowledge several limitations and areas for future research:
- The experiments are limited to image classification tasks, and it's unclear how well IMWA would generalize to other types of class-imbalanced problems, such as text classification or time series forecasting.
- The paper does not explore the computational overhead or training time implications of IMWA, which could be an important consideration for some real-world applications.
- The authors mention that the optimal hyperparameters for IMWA may vary depending on the dataset and model architecture, and further research is needed to develop systematic tuning strategies.
Despite these limitations, the paper makes a valuable contribution to the field of class-imbalanced learning and highlights the potential of IMWA as a powerful technique for improving the robustness and accuracy of deep learning models.
Conclusion
This paper demonstrates that Iterative Model Weight Averaging (IMWA) can significantly boost the performance of deep learning models on class-imbalanced learning tasks. By continuously averaging the model weights during training, IMWA helps the model learn a more balanced representation of the classes, even when the dataset is skewed.
The authors' experiments on several benchmark datasets show that IMWA outperforms other weight averaging techniques, leading to substantial improvements in accuracy, F1-score, and other key metrics. This is an important finding, as class imbalance is a common challenge in many real-world machine learning applications, from detecting rare diseases to identifying unusual financial transactions.
By using IMWA, machine learning practitioners can build more robust and accurate models, even when their data is skewed. While the paper has some limitations, it represents a significant step forward in addressing the class imbalance problem and opens up promising avenues for further research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
Adaptive Stochastic Weight Averaging
Caglar Demir, Arnab Sharma, Axel-Cyrille Ngonga Ngomo
0
0
Ensemble models often improve generalization performances in challenging tasks. Yet, traditional techniques based on prediction averaging incur three well-known disadvantages: the computational overhead of training multiple models, increased latency, and memory requirements at test time. To address these issues, the Stochastic Weight Averaging (SWA) technique maintains a running average of model parameters from a specific epoch onward. Despite its potential benefits, maintaining a running average of parameters can hinder generalization, as an underlying running model begins to overfit. Conversely, an inadequately chosen starting point can render SWA more susceptible to underfitting compared to an underlying running model. In this work, we propose Adaptive Stochastic Weight Averaging (ASWA) technique that updates a running average of model parameters, only when generalization performance is improved on the validation dataset. Hence, ASWA can be seen as a combination of SWA with the early stopping technique, where the former accepts all updates on a parameter ensemble model and the latter rejects any update on an underlying running model. We conducted extensive experiments ranging from image classification to multi-hop reasoning over knowledge graphs. Our experiments over 11 benchmark datasets with 7 baseline models suggest that ASWA leads to a statistically better generalization across models and datasets
6/28/2024
🌿
WASH: Train your Ensemble with Communication-Efficient Weight Shuffling, then Average
Louis Fournier (MLIA), Adel Nabli (MLIA, Mila), Masih Aminbeidokhti (ETS), Marco Pedersoli (ETS), Eugene Belilovsky (Mila), Edouard Oyallon
0
0
The performance of deep neural networks is enhanced by ensemble methods, which average the output of several models. However, this comes at an increased cost at inference. Weight averaging methods aim at balancing the generalization of ensembling and the inference speed of a single model by averaging the parameters of an ensemble of models. Yet, naive averaging results in poor performance as models converge to different loss basins, and aligning the models to improve the performance of the average is challenging. Alternatively, inspired by distributed training, methods like DART and PAPA have been proposed to train several models in parallel such that they will end up in the same basin, resulting in good averaging accuracy. However, these methods either compromise ensembling accuracy or demand significant communication between models during training. In this paper, we introduce WASH, a novel distributed method for training model ensembles for weight averaging that achieves state-of-the-art image classification accuracy. WASH maintains models within the same basin by randomly shuffling a small percentage of weights during training, resulting in diverse models and lower communication costs compared to standard parameter averaging methods.
5/29/2024
🖼️
MOWA: Multiple-in-One Image Warping Model
Kang Liao, Zongsheng Yue, Zhonghua Wu, Chen Change Loy
0
0
While recent image warping approaches achieved remarkable success on existing benchmarks, they still require training separate models for each specific task and cannot generalize well to different camera models or customized manipulations. To address diverse types of warping in practice, we propose a Multiple-in-One image WArping model (named MOWA) in this work. Specifically, we mitigate the difficulty of multi-task learning by disentangling the motion estimation at both the region level and pixel level. To further enable dynamic task-aware image warping, we introduce a lightweight point-based classifier that predicts the task type, serving as prompts to modulate the feature maps for more accurate estimation. To our knowledge, this is the first work that solves multiple practical warping tasks in one single model. Extensive experiments demonstrate that our MOWA, which is trained on six tasks for multiple-in-one image warping, outperforms state-of-the-art task-specific models across most tasks. Moreover, MOWA also exhibits promising potential to generalize into unseen scenes, as evidenced by cross-domain and zero-shot evaluations. The code and more visual results can be found on the project page: https://kangliao929.github.io/projects/mowa/.
6/18/2024
🏷️
Optimizing the Optimal Weighted Average: Efficient Distributed Sparse Classification
Fred Lu, Ryan R. Curtin, Edward Raff, Francis Ferraro, James Holt
0
0
While distributed training is often viewed as a solution to optimizing linear models on increasingly large datasets, inter-machine communication costs of popular distributed approaches can dominate as data dimensionality increases. Recent work on non-interactive algorithms shows that approximate solutions for linear models can be obtained efficiently with only a single round of communication among machines. However, this approximation often degenerates as the number of machines increases. In this paper, building on the recent optimal weighted average method, we introduce a new technique, ACOWA, that allows an extra round of communication to achieve noticeably better approximation quality with minor runtime increases. Results show that for sparse distributed logistic regression, ACOWA obtains solutions that are more faithful to the empirical risk minimizer and attain substantially higher accuracy than other distributed algorithms.
6/5/2024