Inclusive ASR for Disfluent Speech: Cascaded Large-Scale Self-Supervised Learning with Targeted Fine-Tuning and Data Augmentation

0

Sign in to get full access
Overview
- This paper presents a novel approach to improving automatic speech recognition (ASR) for disfluent speech, which is speech that contains hesitations, repetitions, and other irregularities.
- The researchers used a cascaded system of large-scale self-supervised learning, targeted fine-tuning, and data augmentation to create an ASR model that can better handle disfluent speech.
- The model was evaluated on several datasets, including those focused on disfluent speech, dysarthric speech, and low-resource languages, demonstrating its effectiveness in a variety of challenging scenarios.
Plain English Explanation
The paper focuses on improving automatic speech recognition (ASR) for speech that is not perfectly clear or fluent. This type of speech, known as "disfluent speech," can contain things like hesitations, repeated words, and other irregularities that make it harder for ASR systems to accurately transcribe.
To address this challenge, the researchers used a multi-step approach. First, they used a technique called "self-supervised learning" to pre-train the ASR model on a large amount of general speech data. This helps the model learn patterns and features that are useful for speech recognition, even if the data doesn't contain the specific types of disfluencies they are interested in.
Next, they "fine-tuned" the model on smaller datasets that were specifically focused on disfluent speech, dysarthric speech (speech affected by motor disorders), and low-resource languages. This targeted fine-tuning helps the model learn to better recognize and handle these challenging speech patterns.
Finally, the researchers used data augmentation techniques to synthetically generate additional disfluent speech samples, which they used to further fine-tune the model. This helps the model become even more robust and accurate when dealing with disfluent speech.
The end result is an ASR system that performs significantly better on disfluent speech compared to traditional approaches, as demonstrated by the evaluation results and other benchmarks. This could have important implications for making speech-based technologies more accessible and inclusive for people with diverse speech patterns.
Technical Explanation
The paper presents a cascaded approach to improving automatic speech recognition (ASR) for disfluent speech, which includes hesitations, repetitions, and other irregularities. The researchers leveraged large-scale self-supervised learning, targeted fine-tuning, and data augmentation to create a robust ASR model.
First, they used self-supervised learning to pre-train the ASR model on a large corpus of general speech data. This helped the model learn useful patterns and features for speech recognition, even if the data did not contain the specific types of disfluencies they were interested in.
Next, the researchers fine-tuned the pre-trained model on smaller datasets focused on disfluent speech, dysarthric speech, and low-resource languages. This targeted fine-tuning allowed the model to learn how to better recognize and handle these challenging speech patterns.
Finally, the team employed data augmentation techniques to synthetically generate additional disfluent speech samples, which they used to further fine-tune the model. This helped the ASR system become more robust and accurate when dealing with disfluent speech.
The effectiveness of this cascaded approach was demonstrated through extensive evaluations on several benchmark datasets, including those focused on disfluent speech and automated speaking assessment. The results show significant improvements in ASR performance compared to traditional methods, particularly for disfluent and irregular speech patterns.
Critical Analysis
The paper presents a well-designed and thorough approach to improving ASR for disfluent speech, and the results are promising. However, the researchers acknowledge several limitations and areas for further research.
One potential concern is the reliance on synthetic data generated through augmentation techniques. While this approach proved effective, it may not fully capture the nuances and complexities of real-world disfluent speech. The researchers suggest exploring approaches that can effectively infuse self-supervised representations into the ASR model as an alternative.
Additionally, the paper focuses on a limited set of disfluency types, such as hesitations and repetitions. It would be valuable to investigate the model's performance on a broader range of disfluencies, including more complex patterns and irregularities that may occur in naturalistic speech.
Furthermore, the evaluation was conducted primarily on English-language datasets. It would be beneficial to assess the model's ability to handle disfluent speech in other languages and cultural contexts, as speech patterns can vary significantly across different linguistic and social environments.
Overall, the paper presents a compelling and innovative approach to improving the inclusivity and accessibility of ASR systems, which is an important area of research with significant real-world implications. The findings and insights provided in this work could pave the way for further advancements in this field.
Conclusion
This paper introduces a novel cascaded approach to improving automatic speech recognition (ASR) for disfluent speech, which includes irregularities such as hesitations and repetitions. The researchers leveraged large-scale self-supervised learning, targeted fine-tuning, and data augmentation to create a robust ASR model that can better handle challenging speech patterns.
The results demonstrate significant improvements in ASR performance, particularly on datasets focused on disfluent speech, dysarthric speech, and low-resource languages. This work has important implications for making speech-based technologies more accessible and inclusive for individuals with diverse speech patterns, which could have a profound impact on a wide range of applications, from automated speaking assessment to voice-controlled assistants.
The researchers acknowledge several limitations and areas for further research, such as exploring alternative approaches to data augmentation and expanding the evaluation to a broader range of disfluency types and linguistic contexts. Continued advancements in this field could lead to even more inclusive and accessible speech recognition systems that better serve the needs of all users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Inclusive ASR for Disfluent Speech: Cascaded Large-Scale Self-Supervised Learning with Targeted Fine-Tuning and Data Augmentation
Dena Mujtaba, Nihar R. Mahapatra, Megan Arney, J. Scott Yaruss, Caryn Herring, Jia Bin
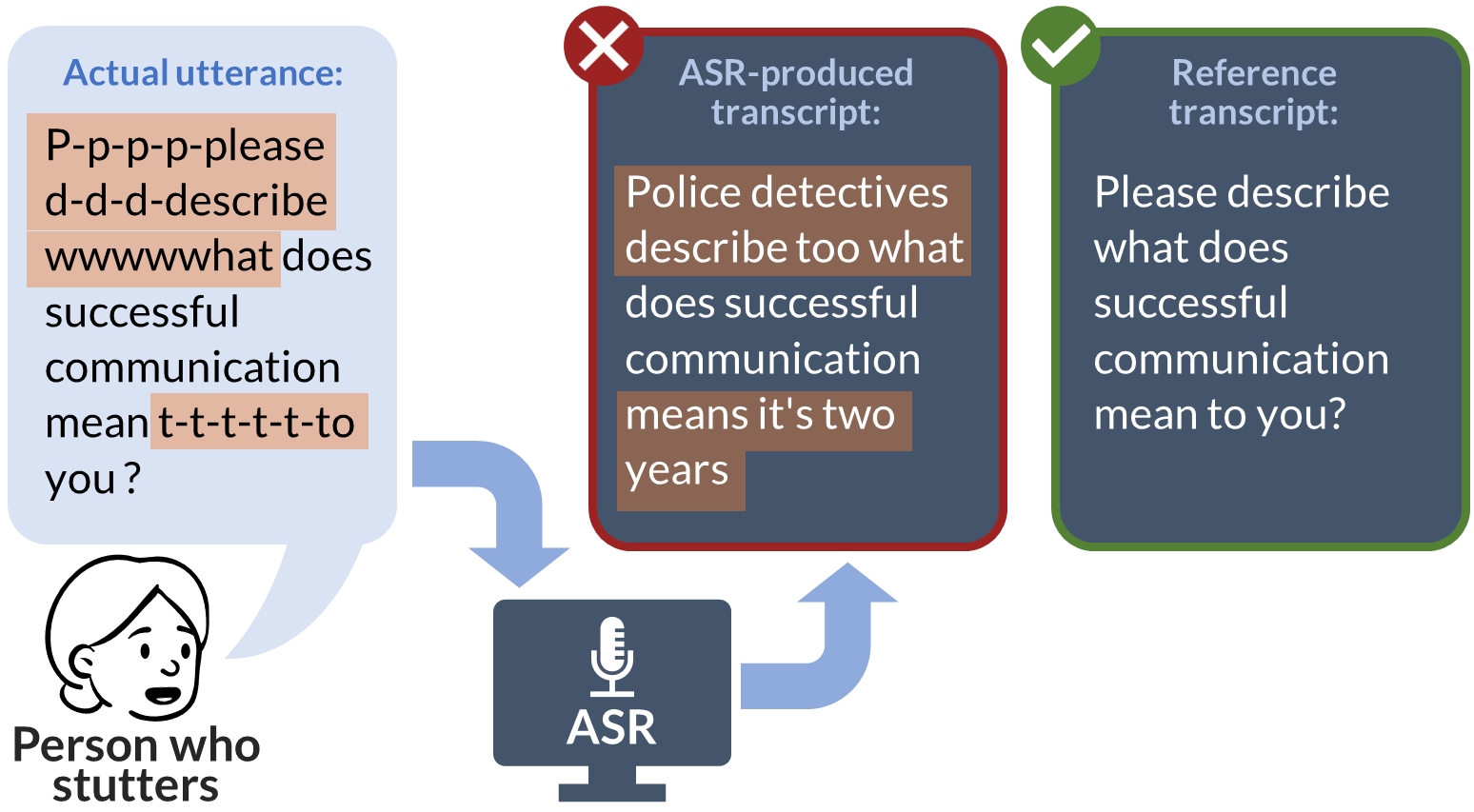
Automatic speech recognition (ASR) systems often falter while processing stuttering-related disfluencies -- such as involuntary blocks and word repetitions -- yielding inaccurate transcripts. A critical barrier to progress is the scarcity of large, annotated disfluent speech datasets. Therefore, we present an inclusive ASR design approach, leveraging large-scale self-supervised learning on standard speech followed by targeted fine-tuning and data augmentation on a smaller, curated dataset of disfluent speech. Our data augmentation technique enriches training datasets with various disfluencies, enhancing ASR processing of these speech patterns. Results show that fine-tuning wav2vec 2.0 with even a relatively small, labeled dataset, alongside data augmentation, can significantly reduce word error rates for disfluent speech. Our approach not only advances ASR inclusivity for people who stutter, but also paves the way for ASRs that can accommodate wider speech variations.
Read more6/17/2024
0
Lost in Transcription: Identifying and Quantifying the Accuracy Biases of Automatic Speech Recognition Systems Against Disfluent Speech
Dena Mujtaba, Nihar R. Mahapatra, Megan Arney, J. Scott Yaruss, Hope Gerlach-Houck, Caryn Herring, Jia Bin
Automatic speech recognition (ASR) systems, increasingly prevalent in education, healthcare, employment, and mobile technology, face significant challenges in inclusivity, particularly for the 80 million-strong global community of people who stutter. These systems often fail to accurately interpret speech patterns deviating from typical fluency, leading to critical usability issues and misinterpretations. This study evaluates six leading ASRs, analyzing their performance on both a real-world dataset of speech samples from individuals who stutter and a synthetic dataset derived from the widely-used LibriSpeech benchmark. The synthetic dataset, uniquely designed to incorporate various stuttering events, enables an in-depth analysis of each ASR's handling of disfluent speech. Our comprehensive assessment includes metrics such as word error rate (WER), character error rate (CER), and semantic accuracy of the transcripts. The results reveal a consistent and statistically significant accuracy bias across all ASRs against disfluent speech, manifesting in significant syntactical and semantic inaccuracies in transcriptions. These findings highlight a critical gap in current ASR technologies, underscoring the need for effective bias mitigation strategies. Addressing this bias is imperative not only to improve the technology's usability for people who stutter but also to ensure their equitable and inclusive participation in the rapidly evolving digital landscape.
Read more5/13/2024
🏋️
0
Training Data Augmentation for Dysarthric Automatic Speech Recognition by Text-to-Dysarthric-Speech Synthesis
Wing-Zin Leung, Mattias Cross, Anton Ragni, Stefan Goetze
Automatic speech recognition (ASR) research has achieved impressive performance in recent years and has significant potential for enabling access for people with dysarthria (PwD) in augmentative and alternative communication (AAC) and home environment systems. However, progress in dysarthric ASR (DASR) has been limited by high variability in dysarthric speech and limited public availability of dysarthric training data. This paper demonstrates that data augmentation using text-to-dysarthic-speech (TTDS) synthesis for finetuning large ASR models is effective for DASR. Specifically, diffusion-based text-to-speech (TTS) models can produce speech samples similar to dysarthric speech that can be used as additional training data for fine-tuning ASR foundation models, in this case Whisper. Results show improved synthesis metrics and ASR performance for the proposed multi-speaker diffusion-based TTDS data augmentation for ASR fine-tuning compared to current DASR baselines.
Read more6/14/2024

0
Improving Accented Speech Recognition using Data Augmentation based on Unsupervised Text-to-Speech Synthesis
Cong-Thanh Do, Shuhei Imai, Rama Doddipatla, Thomas Hain
This paper investigates the use of unsupervised text-to-speech synthesis (TTS) as a data augmentation method to improve accented speech recognition. TTS systems are trained with a small amount of accented speech training data and their pseudo-labels rather than manual transcriptions, and hence unsupervised. This approach enables the use of accented speech data without manual transcriptions to perform data augmentation for accented speech recognition. Synthetic accented speech data, generated from text prompts by using the TTS systems, are then combined with available non-accented speech data to train automatic speech recognition (ASR) systems. ASR experiments are performed in a self-supervised learning framework using a Wav2vec2.0 model which was pre-trained on large amount of unsupervised accented speech data. The accented speech data for training the unsupervised TTS are read speech, selected from L2-ARCTIC and British Isles corpora, while spontaneous conversational speech from the Edinburgh international accents of English corpus are used as the evaluation data. Experimental results show that Wav2vec2.0 models which are fine-tuned to downstream ASR task with synthetic accented speech data, generated by the unsupervised TTS, yield up to 6.1% relative word error rate reductions compared to a Wav2vec2.0 baseline which is fine-tuned with the non-accented speech data from Librispeech corpus.
Read more7/8/2024