IncogniText: Privacy-enhancing Conditional Text Anonymization via LLM-based Private Attribute Randomization

0

Sign in to get full access
Overview
- This paper introduces IncogniText, a privacy-enhancing system that performs conditional text anonymization using large language models (LLMs) to randomize private attributes while preserving the semantic and stylistic content of the text.
- The key idea is to leverage the powerful language modeling capabilities of LLMs to generate anonymized text that retains the original meaning and tone, while obscuring personally identifiable information.
- IncogniText addresses the challenge of balancing privacy protection and utility preservation in text anonymization, a critical requirement for many real-world applications.
Plain English Explanation
IncogniText is a system that helps protect the privacy of text by making changes to it without dramatically altering the overall meaning or style. It uses powerful language models to identify and modify parts of the text that could reveal personal information, like names or locations, while keeping the rest of the text intact.
The main goal is to strike a balance between protecting someone's privacy and still maintaining the usefulness of the text. This is important for many applications, like publishing personal stories or analyzing online discussions, where you want to share information without compromising individual privacy.
By leveraging the advanced language understanding capabilities of large language models, IncogniText can identify sensitive parts of the text and replace them with similar-sounding but anonymous alternatives. This allows the core content and tone of the text to be preserved while obfuscating any personally identifiable details.
The key innovation of IncogniText is its ability to perform this conditional anonymization, where only the necessary parts of the text are altered to protect privacy, rather than making broad, indiscriminate changes that could diminish the overall meaning and value of the information.
Technical Explanation
IncogniText uses a two-step process to perform privacy-enhancing text anonymization. First, it identifies sensitive personal attributes in the input text using a state-of-the-art named entity recognition (NER) model. Then, it leverages the powerful language modeling capabilities of large language models (LLMs) to generate plausible replacements for these private attributes, preserving the semantic and stylistic content of the original text.
The authors evaluate IncogniText on a range of benchmark datasets and compare its performance to existing text anonymization techniques. Their results demonstrate that IncogniText can achieve strong privacy protection while maintaining high utility, as measured by various metrics that assess the preservation of textual meaning and style.
One key aspect of IncogniText is its "conditional" nature, where only the necessary parts of the text are anonymized, rather than applying a one-size-fits-all approach. This allows IncogniText to strike a balance between privacy and utility, which is crucial for many real-world applications of text anonymization.
The paper also discusses the potential limitations of IncogniText, such as its reliance on the accuracy of the underlying NER model and the potential for LLM-generated text to introduce subtle biases or inaccuracies. The authors suggest avenues for future research to address these challenges and further improve the performance and robustness of privacy-enhancing text anonymization systems.
Critical Analysis
The IncogniText paper presents a novel and promising approach to text anonymization that addresses the important tradeoff between privacy protection and utility preservation. By leveraging the capabilities of large language models, the system can selectively anonymize sensitive personal attributes while preserving the overall meaning and style of the text.
One potential limitation discussed in the paper is the reliance on the accuracy of the named entity recognition (NER) model used to identify private attributes. If the NER model fails to detect certain sensitive information, it could lead to incomplete anonymization and potential privacy breaches. The authors suggest exploring ways to improve the robustness of the NER component, such as incorporating additional contextual cues or employing ensemble methods.
Another area of concern is the potential for LLM-generated text to introduce subtle biases or inaccuracies. While the authors demonstrate that IncogniText can maintain high utility, it would be valuable to further investigate the extent to which the anonymized text preserves the nuances and subtleties of the original content. Careful evaluation of the semantic and stylistic fidelity of the anonymized text could help identify any potential issues.
Additionally, the paper does not address the scalability of IncogniText or its computational efficiency, which could be important considerations for real-world deployment, especially in scenarios involving large volumes of text. Exploring ways to optimize the performance of the system could enhance its practical applicability.
Overall, the IncogniText paper presents an interesting and technically sound approach to privacy-enhancing text anonymization. As the authors note, further research is needed to address the limitations and explore ways to improve the system's robustness and performance. Nonetheless, the paper contributes valuable insights to the ongoing efforts in balancing privacy and utility in text-based applications.
Conclusion
The IncogniText paper introduces a novel privacy-enhancing text anonymization system that leverages the power of large language models to selectively modify sensitive personal attributes while preserving the overall meaning and style of the text. By addressing the critical tradeoff between privacy protection and utility preservation, IncogniText represents a significant advancement in the field of text anonymization, with potential applications in a wide range of domains where the responsible handling of personal information is of paramount importance.
The key innovation of IncogniText is its conditional approach, where only the necessary parts of the text are anonymized, rather than applying a one-size-fits-all solution. This allows the system to strike a balance between privacy and utility, a crucial requirement for many real-world applications, such as publishing personal narratives or analyzing online discussions.
While the paper highlights the promising performance of IncogniText, it also acknowledges several areas for further research, including improving the robustness of the underlying named entity recognition model, exploring ways to mitigate potential biases or inaccuracies introduced by the language model-based anonymization, and addressing scalability and computational efficiency concerns.
As the use of language models continues to expand in various applications, the IncogniText paper serves as a valuable contribution to the ongoing efforts in developing privacy-preserving text processing techniques. By addressing the fundamental challenge of balancing privacy and utility, this research paves the way for more responsible and ethical use of textual data in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
IncogniText: Privacy-enhancing Conditional Text Anonymization via LLM-based Private Attribute Randomization
Ahmed Frikha, Nassim Walha, Krishna Kanth Nakka, Ricardo Mendes, Xue Jiang, Xuebing Zhou
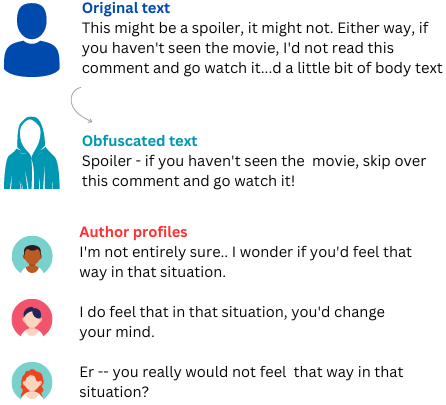
In this work, we address the problem of text anonymization where the goal is to prevent adversaries from correctly inferring private attributes of the author, while keeping the text utility, i.e., meaning and semantics. We propose IncogniText, a technique that anonymizes the text to mislead a potential adversary into predicting a wrong private attribute value. Our empirical evaluation shows a reduction of private attribute leakage by more than 90%. Finally, we demonstrate the maturity of IncogniText for real-world applications by distilling its anonymization capability into a set of LoRA parameters associated with an on-device model.
Read more7/4/2024
0
Keep It Private: Unsupervised Privatization of Online Text
Calvin Bao, Marine Carpuat
Authorship obfuscation techniques hold the promise of helping people protect their privacy in online communications by automatically rewriting text to hide the identity of the original author. However, obfuscation has been evaluated in narrow settings in the NLP literature and has primarily been addressed with superficial edit operations that can lead to unnatural outputs. In this work, we introduce an automatic text privatization framework that fine-tunes a large language model via reinforcement learning to produce rewrites that balance soundness, sense, and privacy. We evaluate it extensively on a large-scale test set of English Reddit posts by 68k authors composed of short-medium length texts. We study how the performance changes among evaluative conditions including authorial profile length and authorship detection strategy. Our method maintains high text quality according to both automated metrics and human evaluation, and successfully evades several automated authorship attacks.
Read more5/17/2024

0
Evaluating the Efficacy of AI Techniques in Textual Anonymization: A Comparative Study
Dimitris Asimopoulos, Ilias Siniosoglou, Vasileios Argyriou, Sotirios K. Goudos, Konstantinos E. Psannis, Nikoleta Karditsioti, Theocharis Saoulidis, Panagiotis Sarigiannidis
In the digital era, with escalating privacy concerns, it's imperative to devise robust strategies that protect private data while maintaining the intrinsic value of textual information. This research embarks on a comprehensive examination of text anonymisation methods, focusing on Conditional Random Fields (CRF), Long Short-Term Memory (LSTM), Embeddings from Language Models (ELMo), and the transformative capabilities of the Transformers architecture. Each model presents unique strengths since LSTM is modeling long-term dependencies, CRF captures dependencies among word sequences, ELMo delivers contextual word representations using deep bidirectional language models and Transformers introduce self-attention mechanisms that provide enhanced scalability. Our study is positioned as a comparative analysis of these models, emphasising their synergistic potential in addressing text anonymisation challenges. Preliminary results indicate that CRF, LSTM, and ELMo individually outperform traditional methods. The inclusion of Transformers, when compared alongside with the other models, offers a broader perspective on achieving optimal text anonymisation in contemporary settings.
Read more5/14/2024

0
Robust Utility-Preserving Text Anonymization Based on Large Language Models
Tianyu Yang, Xiaodan Zhu, Iryna Gurevych
Text anonymization is crucial for sharing sensitive data while maintaining privacy. Existing techniques face the emerging challenges of re-identification attack ability of Large Language Models (LLMs), which have shown advanced capability in memorizing detailed information and patterns as well as connecting disparate pieces of information. In defending against LLM-based re-identification attacks, anonymization could jeopardize the utility of the resulting anonymized data in downstream tasks -- the trade-off between privacy and data utility requires deeper understanding within the context of LLMs. This paper proposes a framework composed of three LLM-based components -- a privacy evaluator, a utility evaluator, and an optimization component, which work collaboratively to perform anonymization. To provide a practical model for large-scale and real-time environments, we distill the anonymization capabilities into a lightweight model using Direct Preference Optimization (DPO). Extensive experiments demonstrate that the proposed models outperform baseline models, showing robustness in reducing the risk of re-identification while preserving greater data utility in downstream tasks. Our code and dataset are available at https://github.com/UKPLab/arxiv2024-rupta.
Read more7/17/2024