Keep It Private: Unsupervised Privatization of Online Text

0
Sign in to get full access
Overview
- Examines the problem of unsupervised privatization of online text to prevent authorship identification
- Proposes a method called "Keep It Private" (KIP) that generates privatized versions of text while preserving its utility
- Evaluates KIP's effectiveness at preventing authorship identification and maintaining text quality through experiments
Plain English Explanation
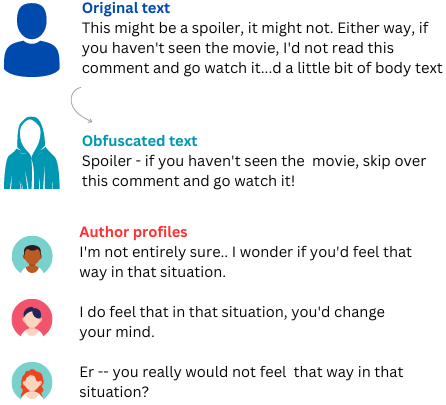
The paper discusses a method called "Keep It Private" (KIP) that can automatically modify online text to protect the writer's privacy. When people post text online, such as on social media or in forums, it's often possible for others to analyze the writing style and guess who the author is. This can be a privacy concern, especially if the text contains sensitive or personal information.
Humanizing Machine-Generated Content: Evading AI Text Detectors and Evaluating the Efficacy of AI Techniques for Textual Anonymization: A Comparative Study have explored related techniques to anonymize online text.
KIP works by making subtle changes to the text, like rewording sentences or replacing words, without dramatically altering the meaning or purpose of the text. This helps protect the author's privacy by making it harder for others to identify them, while still keeping the text useful for its intended purpose. The researchers tested KIP and found it was effective at preventing authorship identification while maintaining the quality and utility of the text.
Technical Explanation
The paper proposes a method called "Keep It Private" (KIP) that can automatically modify online text to protect the writer's privacy without drastically changing the text's meaning or purpose. KIP works by making subtle changes to the text, such as rewording sentences or substituting words, in order to obscure the author's writing style and make it harder for others to identify them.
Silencing the Risk, Not the Whistle: Semi-Automated Text Anonymization and Benchmarking Advanced Text Anonymisation Methods: A Comparative Study have explored related text anonymization techniques.
The researchers evaluated KIP's effectiveness through a series of experiments. They tested KIP's ability to prevent authorship identification by having it modify text samples and then seeing if machine learning models could still correctly identify the original author. They also assessed whether the privatized text maintained its quality and utility by having human raters evaluate the modified text.
The results showed that KIP was effective at preventing authorship identification while preserving the text's quality and usefulness. This suggests KIP could be a valuable tool for protecting online privacy without compromising the ability to communicate and share information.
Critical Analysis
The paper provides a thorough and well-designed evaluation of the KIP method, addressing important considerations around both privacy protection and text utility preservation. However, a few potential limitations or areas for further research are worth noting:
The experiments were conducted on a relatively small dataset of text samples, so it would be important to validate the findings on a larger and more diverse corpus of online text. Additionally, the human evaluation of text quality was subjective, so more objective metrics could strengthen the analysis.
Benchmarking Advanced Text Anonymisation Methods: A Comparative Study and Online Personalization with White-Box LLMs: Generation and Neural Extraction have explored related challenges in text anonymization and personalization.
It would also be valuable to investigate how KIP's performance might vary across different types of online text (e.g., social media posts, blog articles, forum discussions) and to explore potential trade-offs between the degree of privacy protection and the level of text alteration.
Overall, the paper presents a promising approach to the important problem of protecting online privacy while maintaining the utility of user-generated content. Further research and refinement of the KIP method could lead to valuable privacy-preserving tools for the digital age.
Conclusion
The "Keep It Private" (KIP) method proposed in this paper offers a novel approach to unsupervised privatization of online text. Through rigorous experiments, the researchers demonstrated that KIP can effectively prevent authorship identification while preserving the quality and utility of the modified text.
This work addresses an important privacy concern in the digital age, where the proliferation of user-generated content online has made it increasingly easy to analyze writing styles and infer the identities of authors. By developing techniques like KIP to automatically privatize text, we can empower online users to share information and express themselves freely without compromising their personal privacy.
Further research building on this foundation could lead to even more robust and versatile text privatization tools, with broad applications across social media, forums, blogs, and other online platforms. As the digital landscape continues to evolve, solutions that balance privacy and utility will be crucial for fostering open and inclusive online communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Keep It Private: Unsupervised Privatization of Online Text
Calvin Bao, Marine Carpuat
Authorship obfuscation techniques hold the promise of helping people protect their privacy in online communications by automatically rewriting text to hide the identity of the original author. However, obfuscation has been evaluated in narrow settings in the NLP literature and has primarily been addressed with superficial edit operations that can lead to unnatural outputs. In this work, we introduce an automatic text privatization framework that fine-tunes a large language model via reinforcement learning to produce rewrites that balance soundness, sense, and privacy. We evaluate it extensively on a large-scale test set of English Reddit posts by 68k authors composed of short-medium length texts. We study how the performance changes among evaluative conditions including authorial profile length and authorship detection strategy. Our method maintains high text quality according to both automated metrics and human evaluation, and successfully evades several automated authorship attacks.
Read more5/17/2024

0
TAROT: Task-Oriented Authorship Obfuscation Using Policy Optimization Methods
Gabriel Loiseau, Damien Sileo, Damien Riquet, Maxime Meyer, Marc Tommasi
Authorship obfuscation aims to disguise the identity of an author within a text by altering the writing style, vocabulary, syntax, and other linguistic features associated with the text author. This alteration needs to balance privacy and utility. While strong obfuscation techniques can effectively hide the author's identity, they often degrade the quality and usefulness of the text for its intended purpose. Conversely, maintaining high utility tends to provide insufficient privacy, making it easier for an adversary to de-anonymize the author. Thus, achieving an optimal trade-off between these two conflicting objectives is crucial. In this paper, we propose TAROT: Task-Oriented Authorship Obfuscation Using Policy Optimization, a new unsupervised authorship obfuscation method whose goal is to optimize the privacy-utility trade-off by regenerating the entire text considering its downstream utility. Our approach leverages policy optimization as a fine-tuning paradigm over small language models in order to rewrite texts by preserving author identity and downstream task utility. We show that our approach largely reduce the accuracy of attackers while preserving utility. We make our code and models publicly available.
Read more8/1/2024

0
IncogniText: Privacy-enhancing Conditional Text Anonymization via LLM-based Private Attribute Randomization
Ahmed Frikha, Nassim Walha, Krishna Kanth Nakka, Ricardo Mendes, Xue Jiang, Xuebing Zhou
In this work, we address the problem of text anonymization where the goal is to prevent adversaries from correctly inferring private attributes of the author, while keeping the text utility, i.e., meaning and semantics. We propose IncogniText, a technique that anonymizes the text to mislead a potential adversary into predicting a wrong private attribute value. Our empirical evaluation shows a reduction of private attribute leakage by more than 90%. Finally, we demonstrate the maturity of IncogniText for real-world applications by distilling its anonymization capability into a set of LoRA parameters associated with an on-device model.
Read more7/4/2024

0
Robust Utility-Preserving Text Anonymization Based on Large Language Models
Tianyu Yang, Xiaodan Zhu, Iryna Gurevych
Text anonymization is crucial for sharing sensitive data while maintaining privacy. Existing techniques face the emerging challenges of re-identification attack ability of Large Language Models (LLMs), which have shown advanced capability in memorizing detailed information and patterns as well as connecting disparate pieces of information. In defending against LLM-based re-identification attacks, anonymization could jeopardize the utility of the resulting anonymized data in downstream tasks -- the trade-off between privacy and data utility requires deeper understanding within the context of LLMs. This paper proposes a framework composed of three LLM-based components -- a privacy evaluator, a utility evaluator, and an optimization component, which work collaboratively to perform anonymization. To provide a practical model for large-scale and real-time environments, we distill the anonymization capabilities into a lightweight model using Direct Preference Optimization (DPO). Extensive experiments demonstrate that the proposed models outperform baseline models, showing robustness in reducing the risk of re-identification while preserving greater data utility in downstream tasks. Our code and dataset are available at https://github.com/UKPLab/arxiv2024-rupta.
Read more7/17/2024