An Incomplete Loop: Deductive, Inductive, and Abductive Learning in Large Language Models
2404.03028
0
0
Abstract
Modern language models (LMs) can learn to perform new tasks in different ways: in instruction following, the target task is described explicitly in natural language; in few-shot prompting, the task is specified implicitly with a small number of examples; in instruction inference, LMs are presented with in-context examples and are then prompted to generate a natural language task description before making predictions. Each of these procedures may be thought of as invoking a different form of reasoning: instruction following involves deductive reasoning, few-shot prompting involves inductive reasoning, and instruction inference involves abductive reasoning. How do these different capabilities relate? Across four LMs (from the gpt and llama families) and two learning problems (involving arithmetic functions and machine translation) we find a strong dissociation between the different types of reasoning: LMs can sometimes learn effectively from few-shot prompts even when they are unable to explain their own prediction rules; conversely, they sometimes infer useful task descriptions while completely failing to learn from human-generated descriptions of the same task. Our results highlight the non-systematic nature of reasoning even in some of today's largest LMs, and underscore the fact that very different learning mechanisms may be invoked by seemingly similar prompting procedures.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how large language models (LLMs) can engage in different types of reasoning, including deductive, inductive, and abductive learning.
- The authors investigate how well LLMs can follow instructions, make generalizations, and come up with new hypotheses to explain observations.
- The findings suggest that while LLMs excel at following instructions, they struggle to consistently generalize beyond their training data or come up with novel explanations for observations.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. These models are trained on vast amounts of online data, allowing them to engage in a wide variety of language-related tasks.
This paper examines three different types of reasoning that LLMs can potentially perform: deductive, inductive, and abductive. Deductive reasoning involves following a set of rules or instructions to arrive at a conclusion. Inductive reasoning involves making generalizations based on observations. Abductive reasoning involves coming up with the best explanation for a set of observations.
The researchers found that LLMs are very good at following instructions and executing deductive reasoning tasks. They can reliably follow step-by-step procedures to complete complex tasks. However, the models struggle more with inductive and abductive reasoning. They often fail to generalize beyond their training data or come up with novel explanations for new observations.
This suggests that while LLMs are powerful language tools, they still have limitations in their higher-level reasoning capabilities. The authors argue that addressing these limitations will be important for developing LLMs that can truly understand and reason about the world like humans do.
Technical Explanation
The paper examines the capabilities of large language models (LLMs) to engage in three types of reasoning: deductive, inductive, and abductive. Deductive reasoning involves applying general rules or principles to arrive at specific conclusions. Inductive reasoning involves making generalizations based on observations. Abductive reasoning involves inferring the most likely explanation for a set of observations.
The researchers conducted a series of experiments to assess how well different LLM architectures, including GPT-3, InstructGPT, and GPT-NeoX, perform on tasks that require these three forms of reasoning. For deductive reasoning, they tested the models' ability to follow multi-step instructions to complete complex tasks. For inductive reasoning, they evaluated the models' ability to make generalizations about patterns in data. For abductive reasoning, they tested the models' ability to come up with plausible hypotheses to explain given observations.
The results showed that LLMs excel at deductive reasoning, consistently following instructions to complete tasks with high accuracy. However, the models struggled more with inductive and abductive reasoning. While they could sometimes make correct generalizations or infer likely explanations, their performance was less reliable and often depended on the specifics of the task.
The authors argue that this suggests LLMs have significant limitations in their higher-level reasoning capabilities compared to humans. They propose that addressing these limitations will be crucial for developing models that can truly understand and reason about the world in a human-like way.
Critical Analysis
The paper provides valuable insights into the current limitations of large language models in terms of their reasoning abilities. The authors' experimental approach of directly testing LLMs' performance on deductive, inductive, and abductive reasoning tasks is a strength, as it allows for a concrete assessment of these capabilities.
However, the paper also acknowledges several caveats and areas for further research. For example, the authors note that the specific prompts and tasks used in the experiments may have influenced the models' performance, and that more work is needed to fully understand the factors that enable robust reasoning in LLMs.
Additionally, the paper does not delve deeply into the potential reasons why LLMs struggle more with inductive and abductive reasoning compared to deductive reasoning. Further investigation into the underlying cognitive and architectural limitations of these models could shed more light on how to address these challenges.
It is also worth considering the potential implications of these findings for the real-world deployment of LLMs. If these models have significant limitations in their higher-level reasoning abilities, it may raise concerns about their suitability for applications that require robust, human-like understanding and decision-making.
Overall, this paper makes an important contribution to our understanding of the current state of large language models and highlights the need for continued research and development to address their reasoning limitations.
Conclusion
This paper provides a detailed examination of the reasoning capabilities of large language models, exploring how well they can engage in deductive, inductive, and abductive reasoning. The findings suggest that while LLMs excel at following instructions and executing deductive reasoning tasks, they struggle more consistently with making generalizations and coming up with novel explanations.
These limitations in the higher-level reasoning abilities of LLMs point to the need for further advancements in the field of AI to develop models that can truly understand and reason about the world like humans do. Addressing these challenges will be crucial for unlocking the full potential of large language models and enabling their safe and effective deployment in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating the Deductive Competence of Large Language Models
Spencer M. Seals, Valerie L. Shalin
0
0
The development of highly fluent large language models (LLMs) has prompted increased interest in assessing their reasoning and problem-solving capabilities. We investigate whether several LLMs can solve a classic type of deductive reasoning problem from the cognitive science literature. The tested LLMs have limited abilities to solve these problems in their conventional form. We performed follow up experiments to investigate if changes to the presentation format and content improve model performance. We do find performance differences between conditions; however, they do not improve overall performance. Moreover, we find that performance interacts with presentation format and content in unexpected ways that differ from human performance. Overall, our results suggest that LLMs have unique reasoning biases that are only partially predicted from human reasoning performance and the human-generated language corpora that informs them.
4/16/2024

Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
Philipp Mondorf, Barbara Plank
0
0
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on genuine reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
4/3/2024
Large Language Models can Learn Rules
Zhaocheng Zhu, Yuan Xue, Xinyun Chen, Denny Zhou, Jian Tang, Dale Schuurmans, Hanjun Dai
0
0
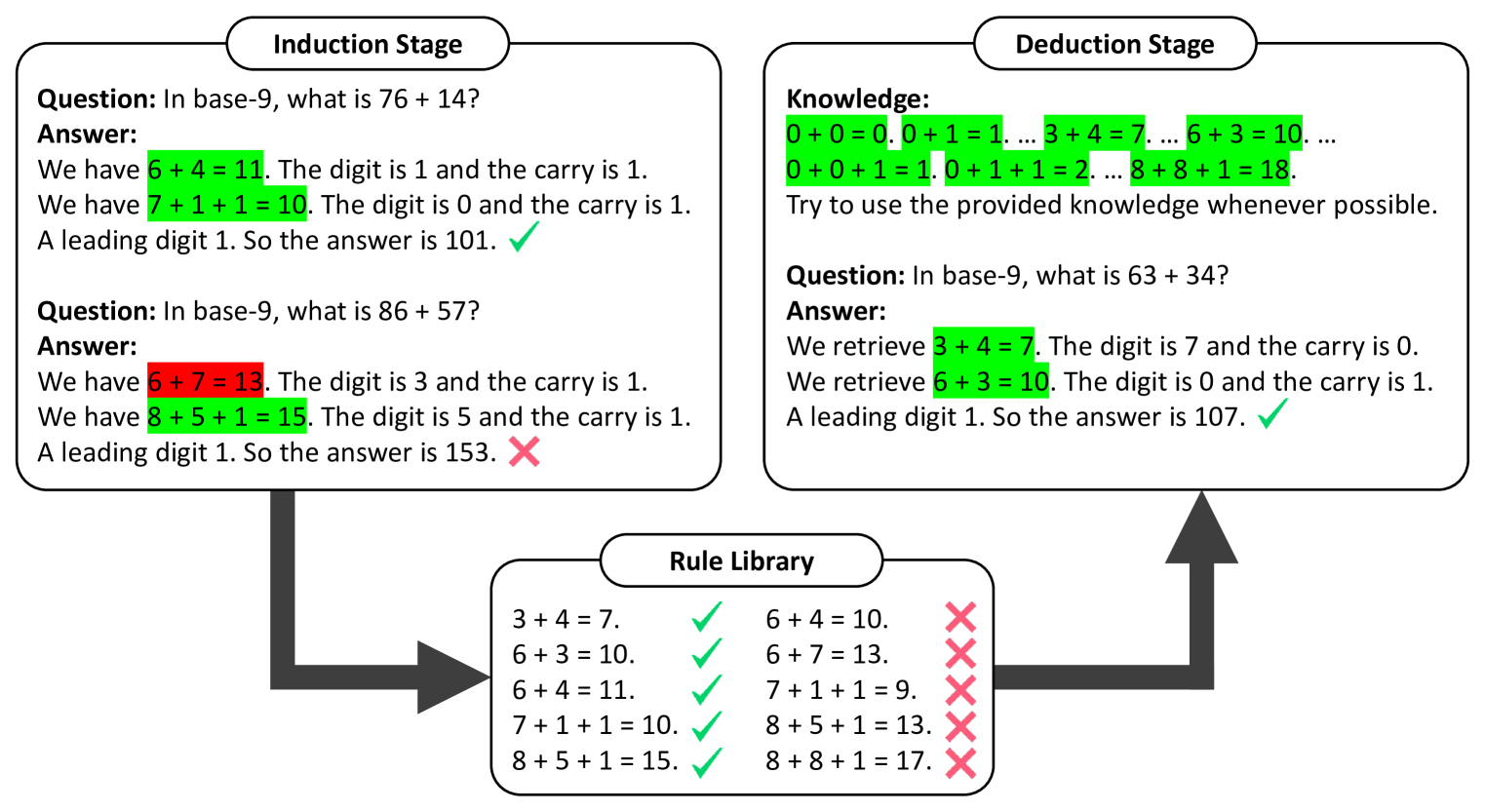
When prompted with a few examples and intermediate steps, large language models (LLMs) have demonstrated impressive performance in various reasoning tasks. However, prompting methods that rely on implicit knowledge in an LLM often generate incorrect answers when the implicit knowledge is wrong or inconsistent with the task. To tackle this problem, we present Hypotheses-to-Theories (HtT), a framework that learns a rule library for reasoning with LLMs. HtT contains two stages, an induction stage and a deduction stage. In the induction stage, an LLM is first asked to generate and verify rules over a set of training examples. Rules that appear and lead to correct answers sufficiently often are collected to form a rule library. In the deduction stage, the LLM is then prompted to employ the learned rule library to perform reasoning to answer test questions. Experiments on relational reasoning, numerical reasoning and concept learning problems show that HtT improves existing prompting methods, with an absolute gain of 10-30% in accuracy. The learned rules are also transferable to different models and to different forms of the same problem.
4/26/2024
Reason from Fallacy: Enhancing Large Language Models' Logical Reasoning through Logical Fallacy Understanding
Yanda Li, Dixuan Wang, Jiaqing Liang, Guochao Jiang, Qianyu He, Yanghua Xiao, Deqing Yang
0
0
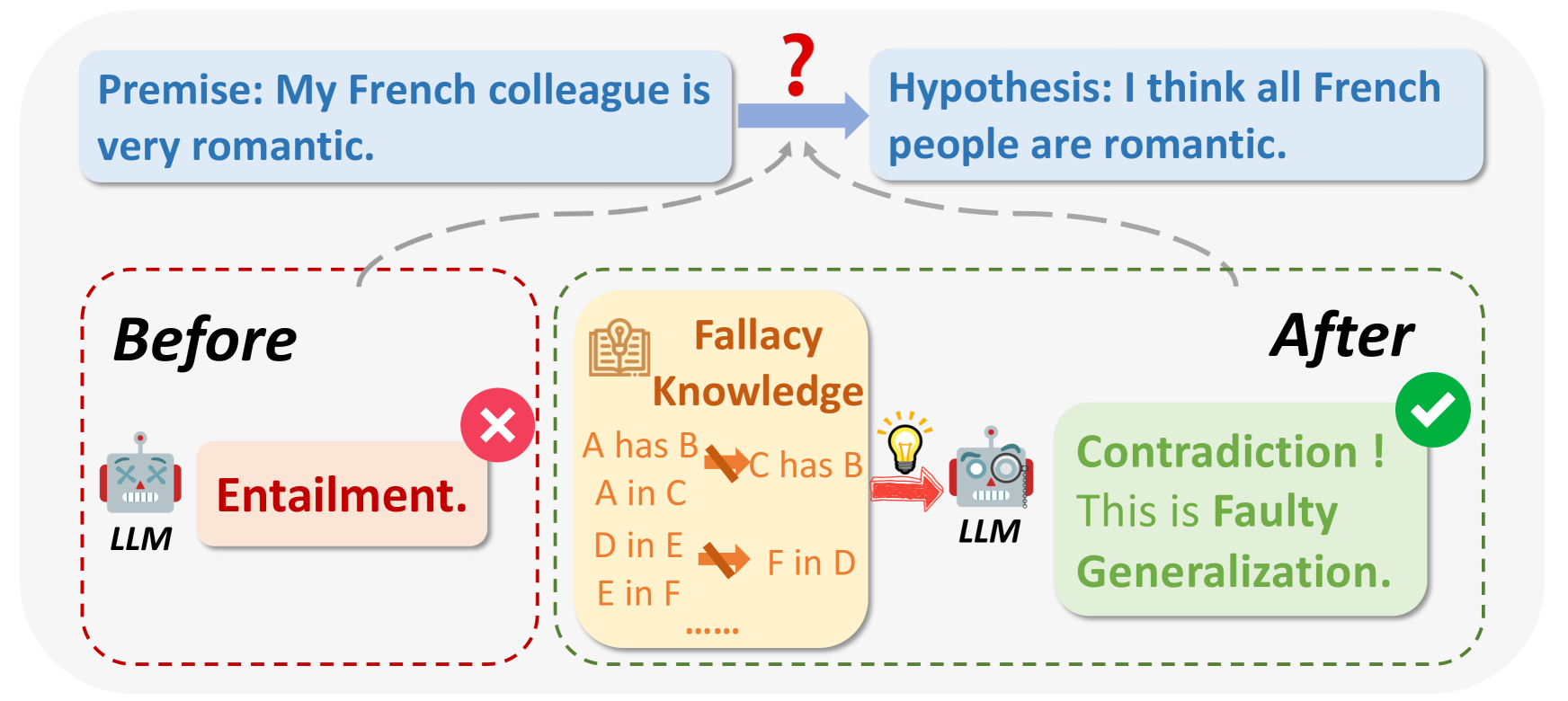
Large Language Models (LLMs) have demonstrated good performance in many reasoning tasks, but they still struggle with some complicated reasoning tasks including logical reasoning. One non-negligible reason for LLMs' suboptimal performance on logical reasoning is their overlooking of understanding logical fallacies correctly. To evaluate LLMs' capability of logical fallacy understanding (LFU), we propose five concrete tasks from three cognitive dimensions of WHAT, WHY, and HOW in this paper. Towards these LFU tasks, we have successfully constructed a new dataset LFUD based on GPT-4 accompanied by a little human effort. Our extensive experiments justify that our LFUD can be used not only to evaluate LLMs' LFU capability, but also to fine-tune LLMs to obtain significantly enhanced performance on logical reasoning.
4/9/2024