Incorporating Unlabelled Data into Bayesian Neural Networks

0
📊
Sign in to get full access
Overview
- Conventional Bayesian Neural Networks (BNNs) cannot leverage unlabelled data to improve their predictions.
- To address this limitation, the researchers introduce Self-Supervised Bayesian Neural Networks.
- These models use unlabelled data to learn models with suitable prior predictive distributions.
- This is achieved by leveraging contrastive pretraining techniques and optimizing a variational lower bound.
- The prior predictive distributions of self-supervised BNNs capture problem semantics better than conventional BNN priors.
- This approach offers improved predictive performance over conventional BNNs, especially in low-budget regimes.
Plain English Explanation
Conventional Bayesian Neural Networks (BNNs) are machine learning models that incorporate uncertainty into their predictions. However, they have a limitation - they cannot use unlabelled data (data without any assigned labels or targets) to improve their performance.
The researchers introduce a new type of BNN called Self-Supervised Bayesian Neural Networks. These models can leverage unlabelled data to learn better models, with
The key idea is to use
As a result, the self-supervised BNNs are able to make more accurate predictions, especially when there is limited labelled data available for training. This can be very useful in real-world scenarios where obtaining labelled data can be expensive or time-consuming.
Technical Explanation
The researchers propose a novel approach called Self-Supervised Bayesian Neural Networks (SS-BNNs) that can leverage unlabelled data to improve the prior predictive distributions of BNNs.
Conventional BNNs are limited in their ability to use unlabelled data to enhance their predictions. To address this, the researchers leverage contrastive pretraining techniques to learn meaningful representations from the unlabelled data. This allows the model to build a better
Specifically, the researchers optimize a variational lower bound that encourages the model's
The researchers demonstrate that the prior predictive distributions learned by SS-BNNs are better aligned with the problem semantics compared to those of conventional BNNs. As a result, SS-BNNs offer improved predictive performance, especially in low-budget regimes where there is limited labelled data available for training.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their work:
-
Computational Complexity: The optimization of the variational lower bound used to train SS-BNNs can be computationally expensive, especially for large-scale problems. The researchers suggest exploring more efficient optimization techniques to address this.
-
Generalization to Different Domains: The experiments in the paper focus on image classification tasks. The researchers encourage further investigation to see if the benefits of SS-BNNs extend to other problem domains, such as natural language processing or reinforcement learning.
-
Interpretability: While the paper demonstrates that SS-BNNs learn better prior predictive distributions, it does not provide a detailed analysis of the learned representations or their interpretability. Exploring the interpretability of the learned priors could be a valuable direction for future research.
-
Comparison to Other Semi-Supervised Approaches: The paper compares SS-BNNs to conventional BNNs but does not evaluate them against other semi-supervised learning techniques, such as positive-unlabeled contrastive learning or unsupervised end-to-end training. Comparing the performance of SS-BNNs to these methods could provide a more comprehensive understanding of their strengths and weaknesses.
Overall, the researchers have presented a promising approach to leveraging unlabelled data to improve the performance of Bayesian Neural Networks. The critical analysis highlights areas for further research and development to enhance the practicality and generalizability of this method.
Conclusion
The paper introduces Self-Supervised Bayesian Neural Networks, a novel approach that can leverage unlabelled data to learn better prior predictive distributions for Bayesian Neural Networks. This leads to improved predictive performance, especially in low-budget regimes where labelled data is scarce.
The key innovation is the use of contrastive pretraining techniques to learn meaningful representations from the unlabelled data, which are then used to optimize the model's prior. This allows the prior predictive distributions to better capture the underlying problem semantics, resulting in more accurate predictions.
While the paper highlights some limitations, such as computational complexity and the need for further exploration in different domains, the proposed SS-BNNs represent a significant step forward in the field of Bayesian deep learning. By effectively utilizing unlabelled data, this approach has the potential to expand the applicability of Bayesian Neural Networks and improve their performance in a wide range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Incorporating Unlabelled Data into Bayesian Neural Networks
Mrinank Sharma, Tom Rainforth, Yee Whye Teh, Vincent Fortuin
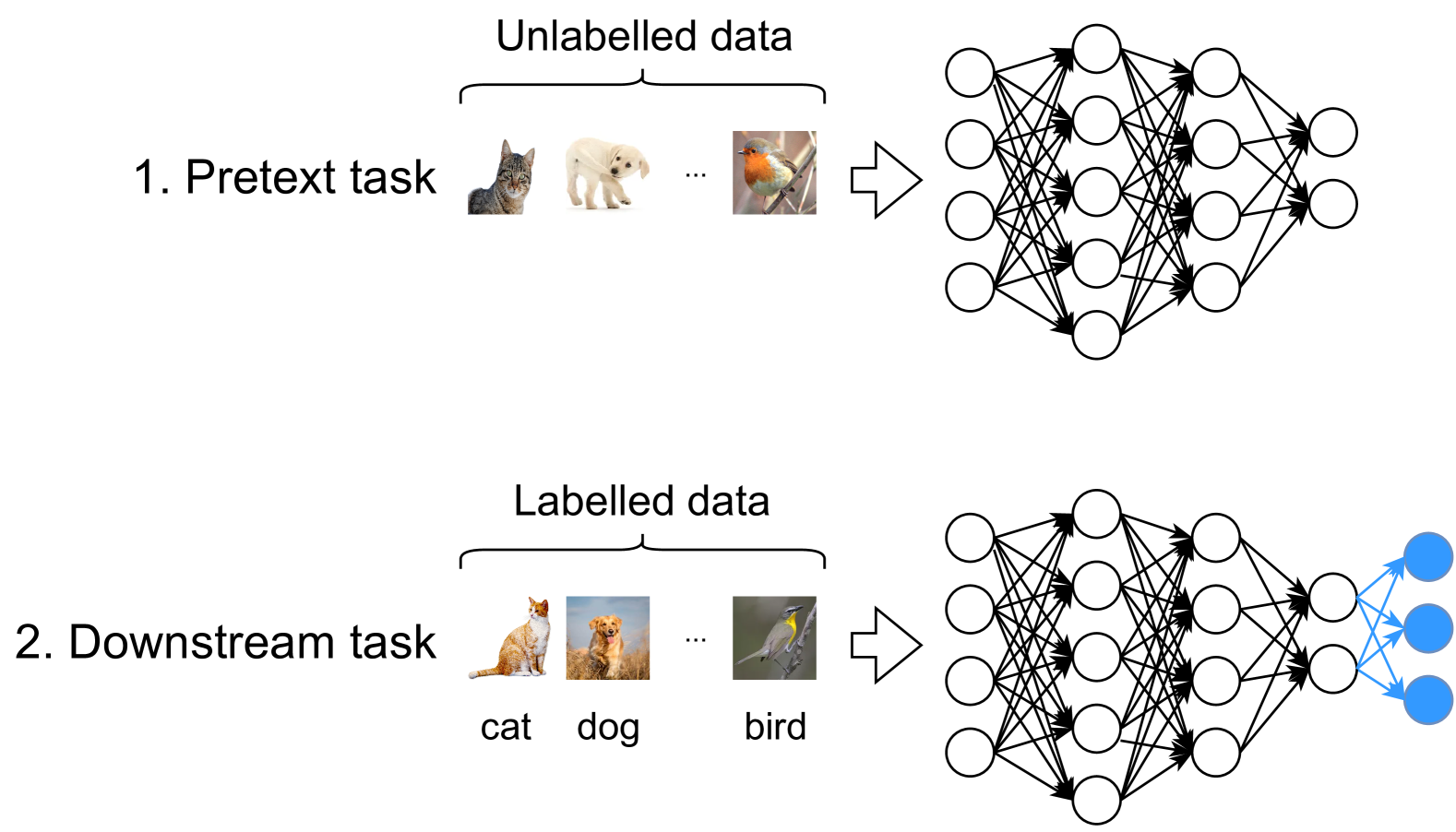
Conventional Bayesian Neural Networks (BNNs) are unable to leverage unlabelled data to improve their predictions. To overcome this limitation, we introduce Self-Supervised Bayesian Neural Networks, which use unlabelled data to learn models with suitable prior predictive distributions. This is achieved by leveraging contrastive pretraining techniques and optimising a variational lower bound. We then show that the prior predictive distributions of self-supervised BNNs capture problem semantics better than conventional BNN priors. In turn, our approach offers improved predictive performance over conventional BNNs, especially in low-budget regimes.
Read more9/2/2024
📊
0
Making Better Use of Unlabelled Data in Bayesian Active Learning
Freddie Bickford Smith, Adam Foster, Tom Rainforth
Fully supervised models are predominant in Bayesian active learning. We argue that their neglect of the information present in unlabelled data harms not just predictive performance but also decisions about what data to acquire. Our proposed solution is a simple framework for semi-supervised Bayesian active learning. We find it produces better-performing models than either conventional Bayesian active learning or semi-supervised learning with randomly acquired data. It is also easier to scale up than the conventional approach. As well as supporting a shift towards semi-supervised models, our findings highlight the importance of studying models and acquisition methods in conjunction.
Read more4/29/2024
0
Towards evolution of Deep Neural Networks through contrastive Self-Supervised learning
Adriano Vinhas, Jo~ao Correia, Penousal Machado
Deep Neural Networks (DNNs) have been successfully applied to a wide range of problems. However, two main limitations are commonly pointed out. The first one is that they require long time to design. The other is that they heavily rely on labelled data, which can sometimes be costly and hard to obtain. In order to address the first problem, neuroevolution has been proved to be a plausible option to automate the design of DNNs. As for the second problem, self-supervised learning has been used to leverage unlabelled data to learn representations. Our goal is to study how neuroevolution can help self-supervised learning to bridge the gap to supervised learning in terms of performance. In this work, we propose a framework that is able to evolve deep neural networks using self-supervised learning. Our results on the CIFAR-10 dataset show that it is possible to evolve adequate neural networks while reducing the reliance on labelled data. Moreover, an analysis to the structure of the evolved networks suggests that the amount of labelled data fed to them has less effect on the structure of networks that learned via self-supervised learning, when compared to individuals that relied on supervised learning.
Read more6/21/2024

0
Unsupervised End-to-End Training with a Self-Defined Target
Dongshu Liu, J'er'emie Laydevant, Adrien Pontlevy, Xing Chen, Damien Querlioz, Julie Grollier
Designing algorithms for versatile AI hardware that can learn on the edge using both labeled and unlabeled data is challenging. Deep end-to-end training methods incorporating phases of self-supervised and supervised learning are accurate and adaptable to input data but self-supervised learning requires even more computational and memory resources than supervised learning, too high for current embedded hardware. Conversely, unsupervised layer-by-layer training, such as Hebbian learning, is more compatible with existing hardware but does not integrate well with supervised learning. To address this, we propose a method enabling networks or hardware designed for end-to-end supervised learning to also perform high-performance unsupervised learning by adding two simple elements to the output layer: Winner-Take-All (WTA) selectivity and homeostasis regularization. These mechanisms introduce a self-defined target for unlabeled data, allowing purely unsupervised training for both fully-connected and convolutional layers using backpropagation or equilibrium propagation on datasets like MNIST (up to 99.2%), Fashion-MNIST (up to 90.3%), and SVHN (up to 81.5%). We extend this method to semi-supervised learning, adjusting targets based on data type, achieving 96.6% accuracy with only 600 labeled MNIST samples in a multi-layer perceptron. Our results show that this approach can effectively enable networks and hardware initially dedicated to supervised learning to also perform unsupervised learning, adapting to varying availability of labeled data.
Read more9/18/2024