Making Better Use of Unlabelled Data in Bayesian Active Learning
2404.17249
0
0
📊
Abstract
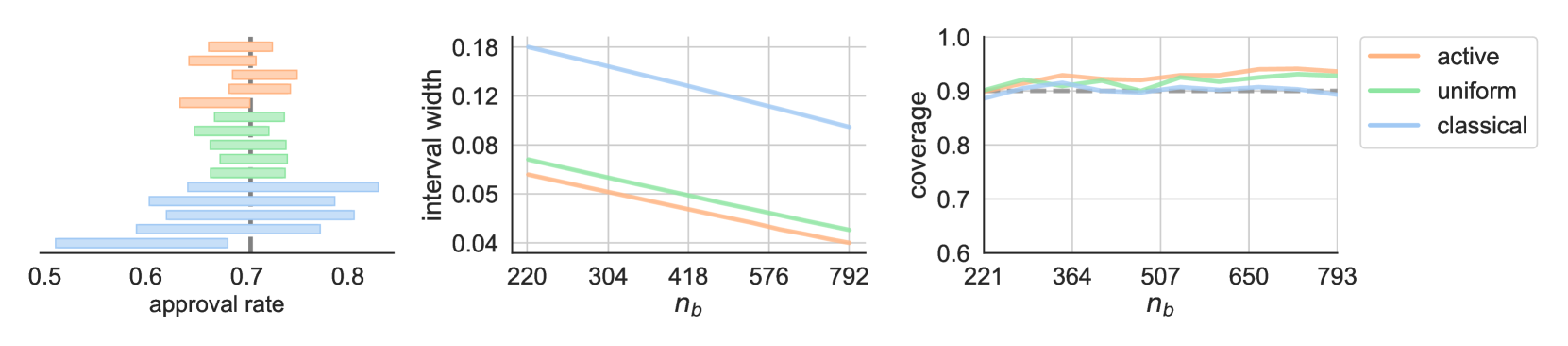
Fully supervised models are predominant in Bayesian active learning. We argue that their neglect of the information present in unlabelled data harms not just predictive performance but also decisions about what data to acquire. Our proposed solution is a simple framework for semi-supervised Bayesian active learning. We find it produces better-performing models than either conventional Bayesian active learning or semi-supervised learning with randomly acquired data. It is also easier to scale up than the conventional approach. As well as supporting a shift towards semi-supervised models, our findings highlight the importance of studying models and acquisition methods in conjunction.
Create account to get full access
Overview
- Fully supervised models are the predominant approach in Bayesian active learning
- The authors argue that neglecting the information present in unlabelled data harms both predictive performance and the decisions about what data to acquire
- The proposed solution is a simple framework for semi-supervised Bayesian active learning
Plain English Explanation
The paper discusses a problem with how Bayesian active learning models are typically trained. Bayesian active learning is a technique where a model is trained in an "active" way, meaning it can request specific data points to be labeled in order to learn more effectively.
However, the authors point out that most Bayesian active learning models are "fully supervised," meaning they only use labeled data during training. The authors argue this is a problem because it means the models are neglecting valuable information that could be present in unlabeled data. This not only hurts the model's predictive performance, but also its ability to make good decisions about what data it should request to be labeled next.
To address this, the authors propose a new "semi-supervised" framework for Bayesian active learning. This allows the model to take advantage of both labeled and unlabeled data during training. The authors find that this semi-supervised approach produces models that perform better than either conventional Bayesian active learning or semi-supervised learning with randomly acquired data. It also scales up more easily than the conventional fully-supervised approach.
Overall, the key takeaway is that considering both labeled and unlabeled data is important for building effective Bayesian active learning models, as highlighted in papers like Integration of Self-Supervised BYOL and Semi-Supervised Learning for Medical Image Classification and Semi-Supervised Active Learning for Video Action Detection.
Technical Explanation
The authors argue that the predominant use of fully supervised models in Bayesian active learning is problematic, as it neglects the information present in unlabelled data. This not only harms predictive performance, but also the decisions about what data to acquire, as highlighted in research on Active Learning for Efficient Annotation in Precision Agriculture and the Fragility of Active Learners.
To address this, the authors propose a simple framework for semi-supervised Bayesian active learning. Their experiments show this approach produces better-performing models than either conventional Bayesian active learning or semi-supervised learning with randomly acquired data. It also scales up more easily than the conventional fully-supervised approach.
The key insight is that studying models and acquisition methods in conjunction, as done in Classification Tree-Based Active Learning Wrapper Approach, is crucial for developing effective Bayesian active learning systems.
Critical Analysis
The authors acknowledge that their proposed semi-supervised framework is a simple approach, and there may be more sophisticated semi-supervised Bayesian active learning methods that could further improve performance. They also note that their experiments were conducted on relatively small-scale datasets, and scaling up to larger, more complex datasets may present additional challenges.
Additionally, the authors do not delve into the potential downsides or limitations of their approach. For example, it would be valuable to understand how the semi-supervised framework performs in scenarios with noisy or unreliable unlabeled data, or how it compares to other semi-supervised active learning techniques beyond random data acquisition.
Overall, the research presents a compelling case for the importance of incorporating unlabeled data into Bayesian active learning models. However, further exploration of the nuances and potential drawbacks of the semi-supervised approach would help provide a more well-rounded understanding of its merits and applicability.
Conclusion
This paper makes a strong argument for the value of semi-supervised approaches in Bayesian active learning. By leveraging both labeled and unlabeled data, the authors demonstrate that it is possible to build more effective models that also make better decisions about what data to acquire.
The findings highlighted in this research, along with related work in areas like Semi-Supervised Active Learning for Video Action Detection, underscore the importance of considering the interplay between model architecture and data acquisition strategies when developing Bayesian active learning systems. As the field continues to evolve, further exploration of semi-supervised techniques could lead to significant advancements in the practical application of active learning across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Active Statistical Inference
Tijana Zrnic, Emmanuel J. Cand`es
0
0
Inspired by the concept of active learning, we propose active inference$unicode{x2013}$a methodology for statistical inference with machine-learning-assisted data collection. Assuming a budget on the number of labels that can be collected, the methodology uses a machine learning model to identify which data points would be most beneficial to label, thus effectively utilizing the budget. It operates on a simple yet powerful intuition: prioritize the collection of labels for data points where the model exhibits uncertainty, and rely on the model's predictions where it is confident. Active inference constructs provably valid confidence intervals and hypothesis tests while leveraging any black-box machine learning model and handling any data distribution. The key point is that it achieves the same level of accuracy with far fewer samples than existing baselines relying on non-adaptively-collected data. This means that for the same number of collected samples, active inference enables smaller confidence intervals and more powerful p-values. We evaluate active inference on datasets from public opinion research, census analysis, and proteomics.
5/30/2024

Deep Bayesian Active Learning for Preference Modeling in Large Language Models
Luckeciano C. Melo, Panagiotis Tigas, Alessandro Abate, Yarin Gal
0
0
Leveraging human preferences for steering the behavior of Large Language Models (LLMs) has demonstrated notable success in recent years. Nonetheless, data selection and labeling are still a bottleneck for these systems, particularly at large scale. Hence, selecting the most informative points for acquiring human feedback may considerably reduce the cost of preference labeling and unleash the further development of LLMs. Bayesian Active Learning provides a principled framework for addressing this challenge and has demonstrated remarkable success in diverse settings. However, previous attempts to employ it for Preference Modeling did not meet such expectations. In this work, we identify that naive epistemic uncertainty estimation leads to the acquisition of redundant samples. We address this by proposing the Bayesian Active Learner for Preference Modeling (BAL-PM), a novel stochastic acquisition policy that not only targets points of high epistemic uncertainty according to the preference model but also seeks to maximize the entropy of the acquired prompt distribution in the feature space spanned by the employed LLM. Notably, our experiments demonstrate that BAL-PM requires 33% to 68% fewer preference labels in two popular human preference datasets and exceeds previous stochastic Bayesian acquisition policies.
6/17/2024

Self-Training for Sample-Efficient Active Learning for Text Classification with Pre-Trained Language Models
Christopher Schroder, Gerhard Heyer
0
0
Active learning is an iterative labeling process that is used to obtain a small labeled subset, despite the absence of labeled data, thereby enabling to train a model for supervised tasks such as text classification. While active learning has made considerable progress in recent years due to improvements provided by pre-trained language models, there is untapped potential in the often neglected unlabeled portion of the data, although it is available in considerably larger quantities than the usually small set of labeled data. Here we investigate how self-training, a semi-supervised approach where a model is used to obtain pseudo-labels from the unlabeled data, can be used to improve the efficiency of active learning for text classification. Starting with an extensive reproduction of four previous self-training approaches, some of which are evaluated for the first time in the context of active learning or natural language processing, we devise HAST, a new and effective self-training strategy, which is evaluated on four text classification benchmarks, on which it outperforms the reproduced self-training approaches and reaches classification results comparable to previous experiments for three out of four datasets, using only 25% of the data.
6/14/2024
📊
Bayesian Data Selection
Julian Rodemann
0
0
A wide range of machine learning algorithms iteratively add data to the training sample. Examples include semi-supervised learning, active learning, multi-armed bandits, and Bayesian optimization. We embed this kind of data addition into decision theory by framing data selection as a decision problem. This paves the way for finding Bayes-optimal selections of data. For the illustrative case of self-training in semi-supervised learning, we derive the respective Bayes criterion. We further show that deploying this criterion mitigates the issue of confirmation bias by empirically assessing our method for generalized linear models, semi-parametric generalized additive models, and Bayesian neural networks on simulated and real-world data.
6/26/2024