Increasing Fairness in Classification of Out of Distribution Data for Facial Recognition
2404.03876
0
0
🏷️
Abstract
Standard classification theory assumes that the distribution of images in the test and training sets are identical. Unfortunately, real-life scenarios typically feature unseen data (out-of-distribution data) which is different from data in the training distribution(in-distribution). This issue is most prevalent in social justice problems where data from under-represented groups may appear in the test data without representing an equal proportion of the training data. This may result in a model returning confidently wrong decisions and predictions. We are interested in the following question: Can the performance of a neural network improve on facial images of out-of-distribution data when it is trained simultaneously on multiple datasets of in-distribution data? We approach this problem by incorporating the Outlier Exposure model and investigate how the model's performance changes when other datasets of facial images were implemented. We observe that the accuracy and other metrics of the model can be increased by applying Outlier Exposure, incorporating a trainable weight parameter to increase the machine's emphasis on outlier images, and by re-weighting the importance of different class labels. We also experimented with whether sorting the images and determining outliers via image features would have more of an effect on the metrics than sorting by average pixel value. Our goal was to make models not only more accurate but also more fair by scanning a more expanded range of images. We also tested the datasets in reverse order to see whether a more fair dataset with balanced features has an effect on the model's accuracy.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper addresses the problem of improving fairness in facial recognition systems when classifying data that is outside the original training distribution.
- The researchers propose a novel approach to make facial recognition models more robust and unbiased when encountering data that differs from the training set.
- They evaluate their method on standard facial recognition benchmarks and demonstrate improved performance, particularly for underrepresented groups.
Plain English Explanation
Facial recognition technology has become increasingly widespread, with applications ranging from security and law enforcement to consumer services. However, these systems can often exhibit biases, leading to disparities in accuracy and performance for certain demographic groups. This is especially problematic when the models are deployed in the real world and encounter data that differs from their original training distribution.
The researchers in this paper aimed to address this challenge by developing a new technique to increase the fairness of facial recognition models when classifying out-of-distribution data. Their approach involves modifying the training process to make the models more robust and equitable, reducing biases and improving performance for underrepresented groups.
By evaluating their method on standard facial recognition benchmarks, the researchers demonstrate that their technique can significantly improve the fairness and overall accuracy of these systems, even when dealing with data that is quite different from the original training set. This is an important step towards developing more reliable and inclusive facial recognition technology that works well for all users, regardless of their individual characteristics.
Technical Explanation
The researchers propose a novel approach called "Fairness-Aware Training" (FAT) to address the problem of fairness in facial recognition systems when classifying out-of-distribution data. The key idea behind FAT is to modify the training process of the model to explicitly consider fairness criteria, in addition to standard classification accuracy.
The FAT method works by introducing a fairness-aware regularization term into the model's objective function during training. This term encourages the model to learn representations that are more equitable across different demographic groups, as defined by attributes like gender, age, or ethnicity. The researchers also incorporate a data augmentation strategy to expose the model to a more diverse range of facial images during training, further enhancing its robustness to out-of-distribution data.
To evaluate the effectiveness of their approach, the researchers conducted experiments on standard facial recognition benchmarks, including Noisy Elephant Room and Can Biases. They compared the performance of FAT-trained models to traditional facial recognition models, measuring both overall accuracy and fairness metrics that capture disparities in performance across different demographic groups.
The results demonstrate that the FAT-trained models consistently outperform the baseline models in terms of fairness, while maintaining competitive classification accuracy. The researchers also analyze the learned representations and find that the FAT approach encourages the model to learn more geographically agnostic features, leading to improved generalization to out-of-distribution data.
Critical Analysis
The researchers have made a compelling case for the importance of addressing fairness in facial recognition systems, particularly when dealing with data that deviates from the original training distribution. Their proposed FAT approach represents a promising step towards developing more inclusive and equitable facial recognition technologies.
One potential limitation of the study is the reliance on standard facial recognition benchmarks, which may not fully capture the diversity and complexity of real-world deployments. It would be valuable to see the FAT method evaluated on a broader range of datasets and application scenarios to better understand its real-world performance and limitations.
Additionally, the paper does not delve deeply into the potential societal implications and ethical considerations of facial recognition technology, which is an area that deserves further scrutiny. Concerns around privacy, surveillance, and the potential for amplifying existing biases and discrimination should be carefully considered as this technology continues to evolve.
Overall, the researchers have made a valuable contribution to the field of fair and robust machine learning, and their work serves as a useful starting point for further research and development in this important area.
Conclusion
This paper presents a novel approach, called Fairness-Aware Training (FAT), to improve the fairness and performance of facial recognition models when dealing with out-of-distribution data. The researchers demonstrate that their method can significantly enhance the equitable performance of these systems, addressing a critical challenge in the deployment of facial recognition technology.
By incorporating fairness-aware regularization and data augmentation techniques into the training process, the FAT approach encourages the models to learn more geographically agnostic and inclusive representations, leading to improved performance for underrepresented groups. This work represents an important step towards developing facial recognition systems that are fair and accurate for all users, regardless of their individual characteristics.
As facial recognition technology becomes increasingly ubiquitous, addressing issues of fairness and bias will be crucial to ensure that these systems are deployed in an ethical and inclusive manner. The researchers' contributions in this paper provide a valuable foundation for future work in this critical area of machine learning and artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Distribution-aware Fairness Test Generation
Sai Sathiesh Rajan, Ezekiel Soremekun, Yves Le Traon, Sudipta Chattopadhyay
0
0
Ensuring that all classes of objects are detected with equal accuracy is essential in AI systems. For instance, being unable to identify any one class of objects could have fatal consequences in autonomous driving systems. Hence, ensuring the reliability of image recognition systems is crucial. This work addresses how to validate group fairness in image recognition software. We propose a distribution-aware fairness testing approach (called DistroFair) that systematically exposes class-level fairness violations in image classifiers via a synergistic combination of out-of-distribution (OOD) testing and semantic-preserving image mutation. DistroFair automatically learns the distribution (e.g., number/orientation) of objects in a set of images. Then it systematically mutates objects in the images to become OOD using three semantic-preserving image mutations - object deletion, object insertion and object rotation. We evaluate DistroFair using two well-known datasets (CityScapes and MS-COCO) and three major, commercial image recognition software (namely, Amazon Rekognition, Google Cloud Vision and Azure Computer Vision). Results show that about 21% of images generated by DistroFair reveal class-level fairness violations using either ground truth or metamorphic oracles. DistroFair is up to 2.3x more effective than two main baselines, i.e., (a) an approach which focuses on generating images only within the distribution (ID) and (b) fairness analysis using only the original image dataset. We further observed that DistroFair is efficient, it generates 460 images per hour, on average. Finally, we evaluate the semantic validity of our approach via a user study with 81 participants, using 30 real images and 30 corresponding mutated images generated by DistroFair. We found that images generated by DistroFair are 80% as realistic as real-world images.
5/15/2024
Toward a Realistic Benchmark for Out-of-Distribution Detection
Pietro Recalcati, Fabio Garcea, Luca Piano, Fabrizio Lamberti, Lia Morra
0
0
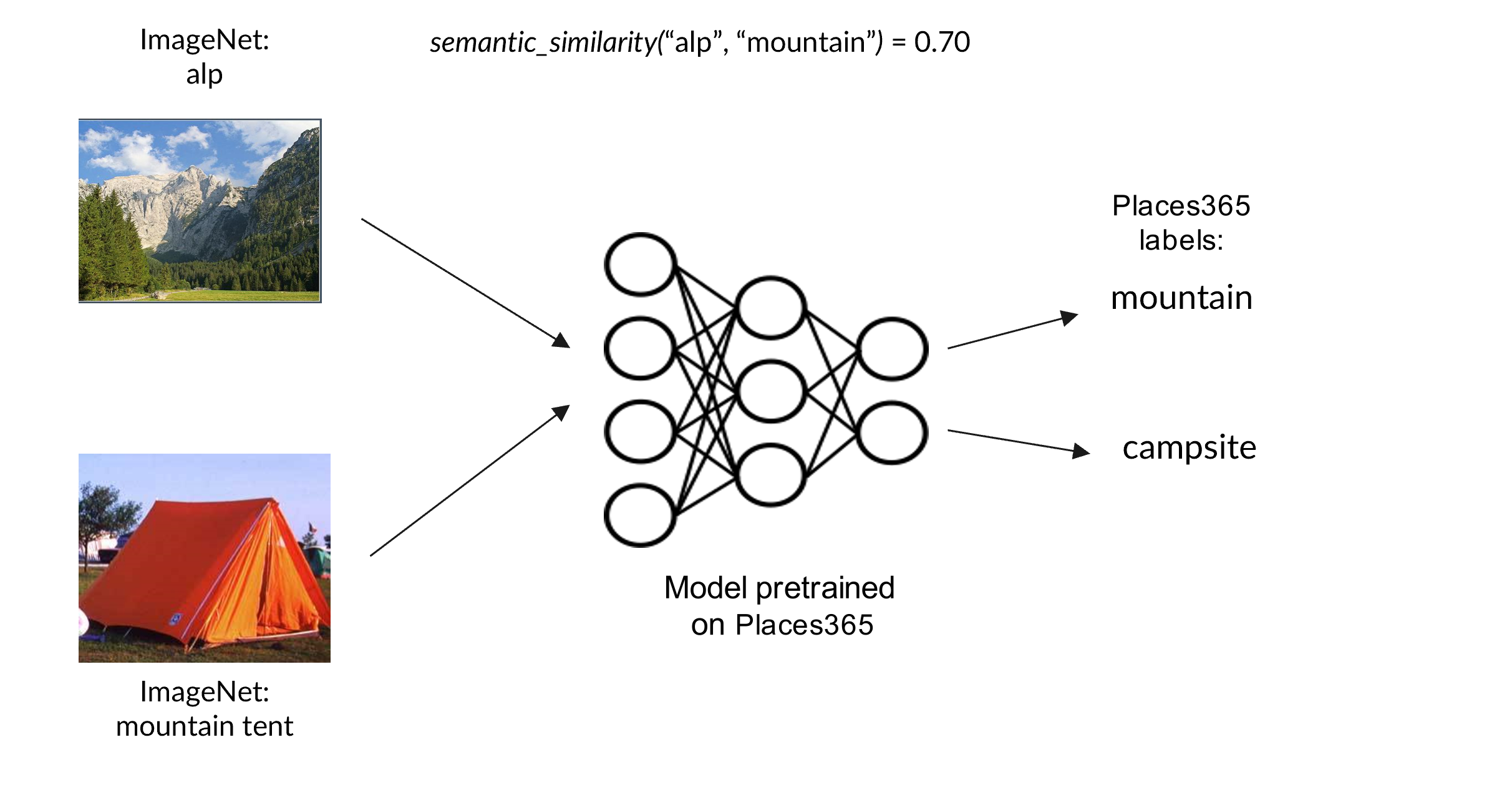
Deep neural networks are increasingly used in a wide range of technologies and services, but remain highly susceptible to out-of-distribution (OOD) samples, that is, drawn from a different distribution than the original training set. A common approach to address this issue is to endow deep neural networks with the ability to detect OOD samples. Several benchmarks have been proposed to design and validate OOD detection techniques. However, many of them are based on far-OOD samples drawn from very different distributions, and thus lack the complexity needed to capture the nuances of real-world scenarios. In this work, we introduce a comprehensive benchmark for OOD detection, based on ImageNet and Places365, that assigns individual classes as in-distribution or out-of-distribution depending on the semantic similarity with the training set. Several techniques can be used to determine which classes should be considered in-distribution, yielding benchmarks with varying properties. Experimental results on different OOD detection techniques show how their measured efficacy depends on the selected benchmark and how confidence-based techniques may outperform classifier-based ones on near-OOD samples.
4/17/2024
Out-of-distribution Detection in Medical Image Analysis: A survey
Zesheng Hong, Yubiao Yue, Yubin Chen, Huanjie Lin, Yuanmei Luo, Mini Han Wang, Weidong Wang, Jialong Xu, Xiaoqi Yang, Zhenzhang Li, Sihong Xie
0
0
Computer-aided diagnostics has benefited from the development of deep learning-based computer vision techniques in these years. Traditional supervised deep learning methods assume that the test sample is drawn from the identical distribution as the training data. However, it is possible to encounter out-of-distribution samples in real-world clinical scenarios, which may cause silent failure in deep learning-based medical image analysis tasks. Recently, research has explored various out-of-distribution (OOD) detection situations and techniques to enable a trustworthy medical AI system. In this survey, we systematically review the recent advances in OOD detection in medical image analysis. We first explore several factors that may cause a distributional shift when using a deep-learning-based model in clinic scenarios, with three different types of distributional shift well defined on top of these factors. Then a framework is suggested to categorize and feature existing solutions, while the previous studies are reviewed based on the methodology taxonomy. Our discussion also includes evaluation protocols and metrics, as well as the challenge and a research direction lack of exploration.
4/30/2024
Understanding normalization in contrastive representation learning and out-of-distribution detection
Tai Le-Gia, Jaehyun Ahn
0
0
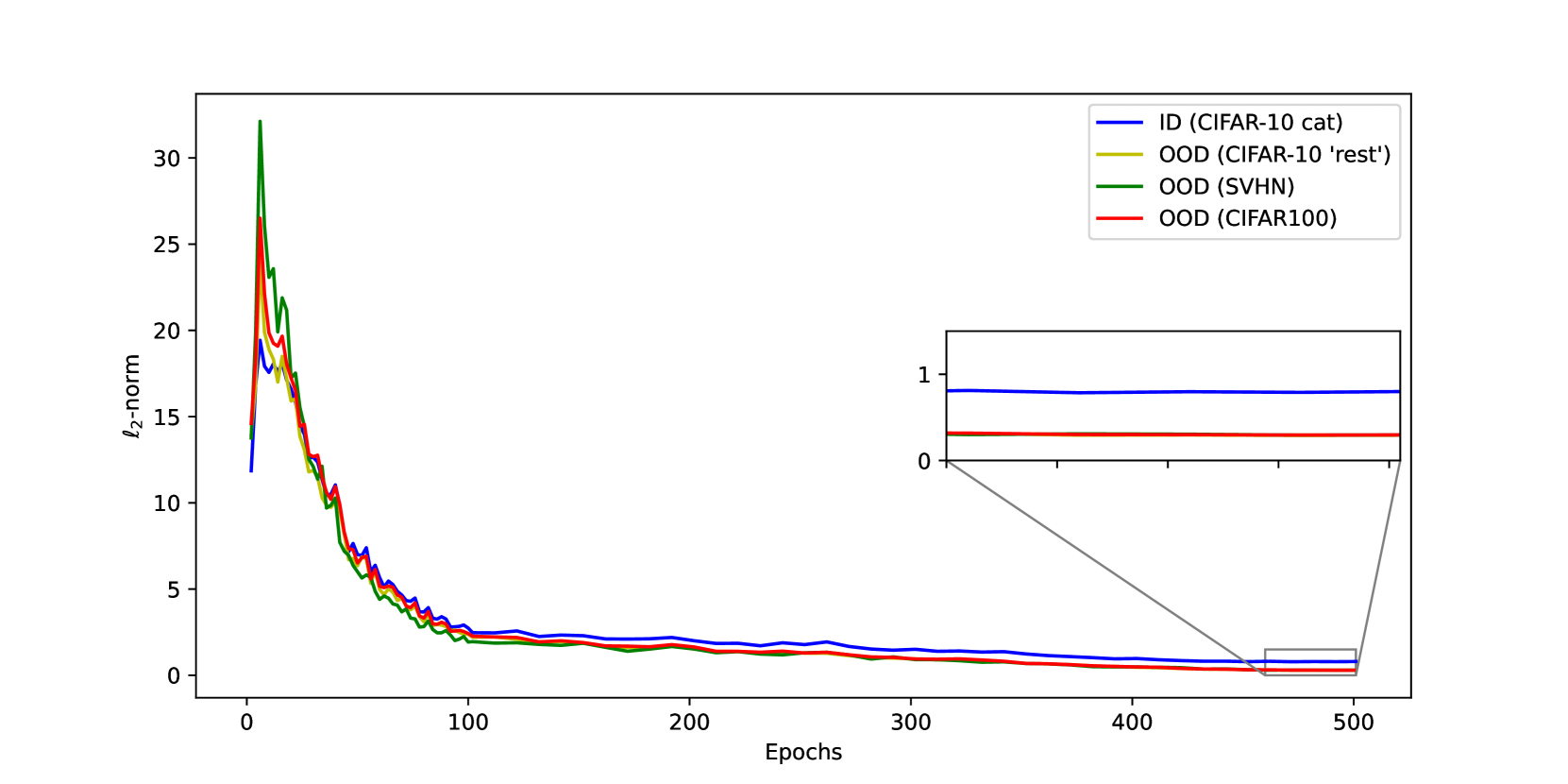
Contrastive representation learning has emerged as an outstanding approach for anomaly detection. In this work, we explore the $ell_2$-norm of contrastive features and its applications in out-of-distribution detection. We propose a simple method based on contrastive learning, which incorporates out-of-distribution data by discriminating against normal samples in the contrastive layer space. Our approach can be applied flexibly as an outlier exposure (OE) approach, where the out-of-distribution data is a huge collective of random images, or as a fully self-supervised learning approach, where the out-of-distribution data is self-generated by applying distribution-shifting transformations. The ability to incorporate additional out-of-distribution samples enables a feasible solution for datasets where AD methods based on contrastive learning generally underperform, such as aerial images or microscopy images. Furthermore, the high-quality features learned through contrastive learning consistently enhance performance in OE scenarios, even when the available out-of-distribution dataset is not diverse enough. Our extensive experiments demonstrate the superiority of our proposed method under various scenarios, including unimodal and multimodal settings, with various image datasets.
4/9/2024