Can Biases in ImageNet Models Explain Generalization?
2404.01509
0
0
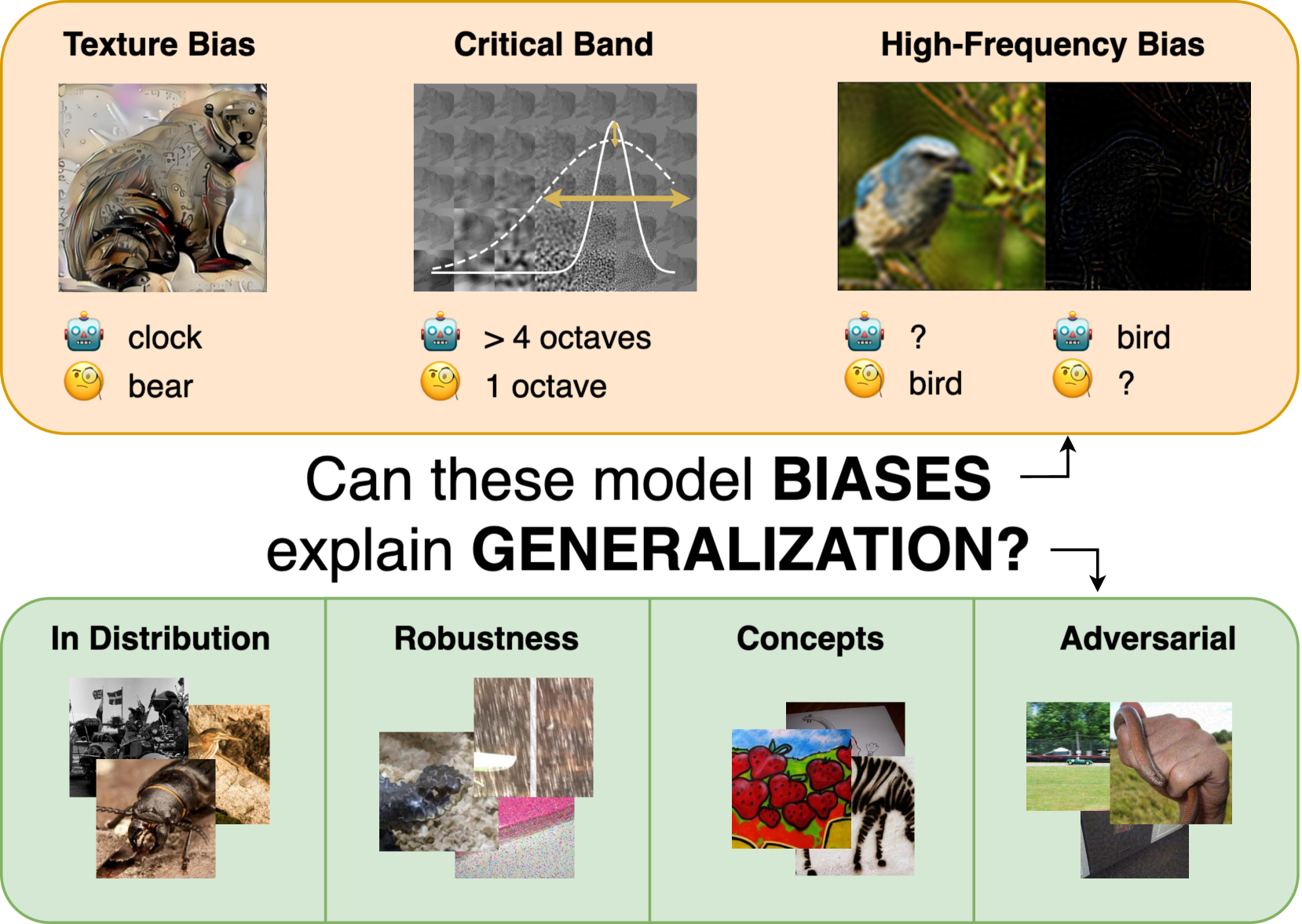
Abstract
The robust generalization of models to rare, in-distribution (ID) samples drawn from the long tail of the training distribution and to out-of-training-distribution (OOD) samples is one of the major challenges of current deep learning methods. For image classification, this manifests in the existence of adversarial attacks, the performance drops on distorted images, and a lack of generalization to concepts such as sketches. The current understanding of generalization in neural networks is very limited, but some biases that differentiate models from human vision have been identified and might be causing these limitations. Consequently, several attempts with varying success have been made to reduce these biases during training to improve generalization. We take a step back and sanity-check these attempts. Fixing the architecture to the well-established ResNet-50, we perform a large-scale study on 48 ImageNet models obtained via different training methods to understand how and if these biases - including shape bias, spectral biases, and critical bands - interact with generalization. Our extensive study results reveal that contrary to previous findings, these biases are insufficient to accurately predict the generalization of a model holistically. We provide access to all checkpoints and evaluation code at https://github.com/paulgavrikov/biases_vs_generalization
Create account to get full access
Overview
- The paper examines whether biases in the ImageNet dataset, a large image classification dataset, can explain the generalization of machine learning models trained on it.
- Researchers investigate how models trained on ImageNet perform on tasks testing texture-based and shape-based classification.
- The findings suggest that ImageNet models rely more heavily on texture cues than shape cues, which may limit their ability to generalize to real-world scenarios.
Plain English Explanation
Machine learning models, like those used for image recognition, are often trained on large datasets like ImageNet. This dataset contains millions of labeled images across thousands of categories. While these models can achieve high performance on the ImageNet benchmark, it's unclear whether the knowledge they gain is truly general or just specific to the dataset.
The researchers in this paper wanted to explore the biases present in ImageNet and how they might influence the generalization of models trained on this data. They found that ImageNet models tend to rely more on texture information than shape information when classifying images. This means the models are recognizing patterns in the surface appearance of objects rather than their underlying structure.
This texture bias could be problematic because the real world contains much more variation in shape than texture. Models overly focused on texture may struggle to generalize to novel scenarios where the appearance doesn't match their training data. The researchers designed experiments to test this idea and found evidence supporting their hypothesis.
By understanding the specific biases in ImageNet and how they impact model behavior, the researchers hope to shed light on the limitations of current AI systems and inspire work to create more robust, generalizable models. This is an important step towards developing machine learning that can truly understand and reason about the world, not just memorize superficial patterns.
Technical Explanation
The researchers conducted a series of experiments to investigate the role of texture and shape biases in ImageNet models. First, they evaluated several popular ImageNet-trained models on a "texture vs. shape" classification task, where objects were presented in either their original form or with their texture and shape manipulated independently.
The results showed that the models relied much more heavily on texture cues than shape cues when making classifications. This texture bias was observed across multiple model architectures and training techniques.
To further explore this phenomenon, the researchers also analyzed the internal representations learned by the models. They found that earlier layers tended to capture more texture-based features, while later layers focused more on shape. This suggests the texture bias is ingrained throughout the model's processing pipeline.
Additional experiments demonstrated that models trained on ImageNet have difficulty generalizing to datasets that require shape-based reasoning, such as silhouettes of objects. In contrast, models performed well on texture-based transfer tasks, indicating their texture-centric learning.
The researchers argue these findings reveal fundamental limitations in the generalization capabilities of ImageNet-trained models. By relying too heavily on superficial texture signals rather than more robust shape information, the models may struggle to apply their knowledge to real-world situations that differ from the statistical biases of the training data.
Critical Analysis
The researchers provide a thoughtful analysis of the potential pitfalls of relying on datasets like ImageNet, which may encode strong biases that get "baked into" the models during training. Their careful experimental design and clear communication of results help substantiate their claims about the texture bias.
However, it's important to note that the texture/shape distinction is somewhat idealized - in the real world, texture and shape are often correlated and jointly informative for object recognition. The researchers acknowledge this limitation, suggesting that a more nuanced understanding of visual reasoning is needed.
Additionally, while the experiments highlight the texture bias, they don't fully explain its origins. Is this an inherent property of the ImageNet dataset, or a byproduct of the supervised learning process and model architectures used? Further investigation into the data collection, annotation, and model training procedures could shed more light on this.
The researchers also don't explore potential mitigating strategies, such as data augmentation techniques or model architectures that encourage shape-based reasoning. Investigating solutions to address the texture bias could be a valuable avenue for future work.
Overall, this paper makes a compelling case that understanding dataset biases is crucial for developing robust and generalizable AI systems. By raising awareness of the texture bias in ImageNet models, the researchers encourage the community to think more critically about the limitations of current machine learning approaches and strive for more comprehensive visual understanding.
Conclusion
This paper highlights an important limitation of current image recognition models trained on the ImageNet dataset - a tendency to rely more on surface-level texture cues than higher-level shape information when making classifications. The researchers demonstrate this texture bias through carefully designed experiments, providing evidence that it is a fundamental characteristic of ImageNet-trained models.
This finding has significant implications for the real-world applicability of these models, as the texture-centric approach may struggle to generalize beyond the statistical patterns of the training data. By drawing attention to this issue, the paper encourages the machine learning community to think more critically about dataset biases and work towards developing models with more robust, shape-based visual reasoning capabilities.
Ultimately, this research is an important step in understanding the strengths and limitations of current AI systems. As the field of machine learning continues to advance, carefully examining the biases and assumptions built into our training data and models will be crucial for creating artificial intelligence that can truly understand and reason about the world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Zero-shot generalization across architectures for visual classification
Evan Gerritz, Luciano Dyballa, Steven W. Zucker
0
0
Generalization to unseen data is a key desideratum for deep networks, but its relation to classification accuracy is unclear. Using a minimalist vision dataset and a measure of generalizability, we show that popular networks, from deep convolutional networks (CNNs) to transformers, vary in their power to extrapolate to unseen classes both across layers and across architectures. Accuracy is not a good predictor of generalizability, and generalization varies non-monotonically with layer depth.
5/6/2024
🎯
Generalization in diffusion models arises from geometry-adaptive harmonic representations
Zahra Kadkhodaie, Florentin Guth, Eero P. Simoncelli, St'ephane Mallat
0
0
Deep neural networks (DNNs) trained for image denoising are able to generate high-quality samples with score-based reverse diffusion algorithms. These impressive capabilities seem to imply an escape from the curse of dimensionality, but recent reports of memorization of the training set raise the question of whether these networks are learning the true continuous density of the data. Here, we show that two DNNs trained on non-overlapping subsets of a dataset learn nearly the same score function, and thus the same density, when the number of training images is large enough. In this regime of strong generalization, diffusion-generated images are distinct from the training set, and are of high visual quality, suggesting that the inductive biases of the DNNs are well-aligned with the data density. We analyze the learned denoising functions and show that the inductive biases give rise to a shrinkage operation in a basis adapted to the underlying image. Examination of these bases reveals oscillating harmonic structures along contours and in homogeneous regions. We demonstrate that trained denoisers are inductively biased towards these geometry-adaptive harmonic bases since they arise not only when the network is trained on photographic images, but also when it is trained on image classes supported on low-dimensional manifolds for which the harmonic basis is suboptimal. Finally, we show that when trained on regular image classes for which the optimal basis is known to be geometry-adaptive and harmonic, the denoising performance of the networks is near-optimal.
4/15/2024
➖
Initial Guessing Bias: How Untrained Networks Favor Some Classes
Emanuele Francazi, Aurelien Lucchi, Marco Baity-Jesi
0
0
Understanding and controlling biasing effects in neural networks is crucial for ensuring accurate and fair model performance. In the context of classification problems, we provide a theoretical analysis demonstrating that the structure of a deep neural network (DNN) can condition the model to assign all predictions to the same class, even before the beginning of training, and in the absence of explicit biases. We prove that, besides dataset properties, the presence of this phenomenon, which we call textit{Initial Guessing Bias} (IGB), is influenced by model choices including dataset preprocessing methods, and architectural decisions, such as activation functions, max-pooling layers, and network depth. Our analysis of IGB provides information for architecture selection and model initialization. We also highlight theoretical consequences, such as the breakdown of node-permutation symmetry, the violation of self-averaging and the non-trivial effects that depth has on the phenomenon.
6/17/2024
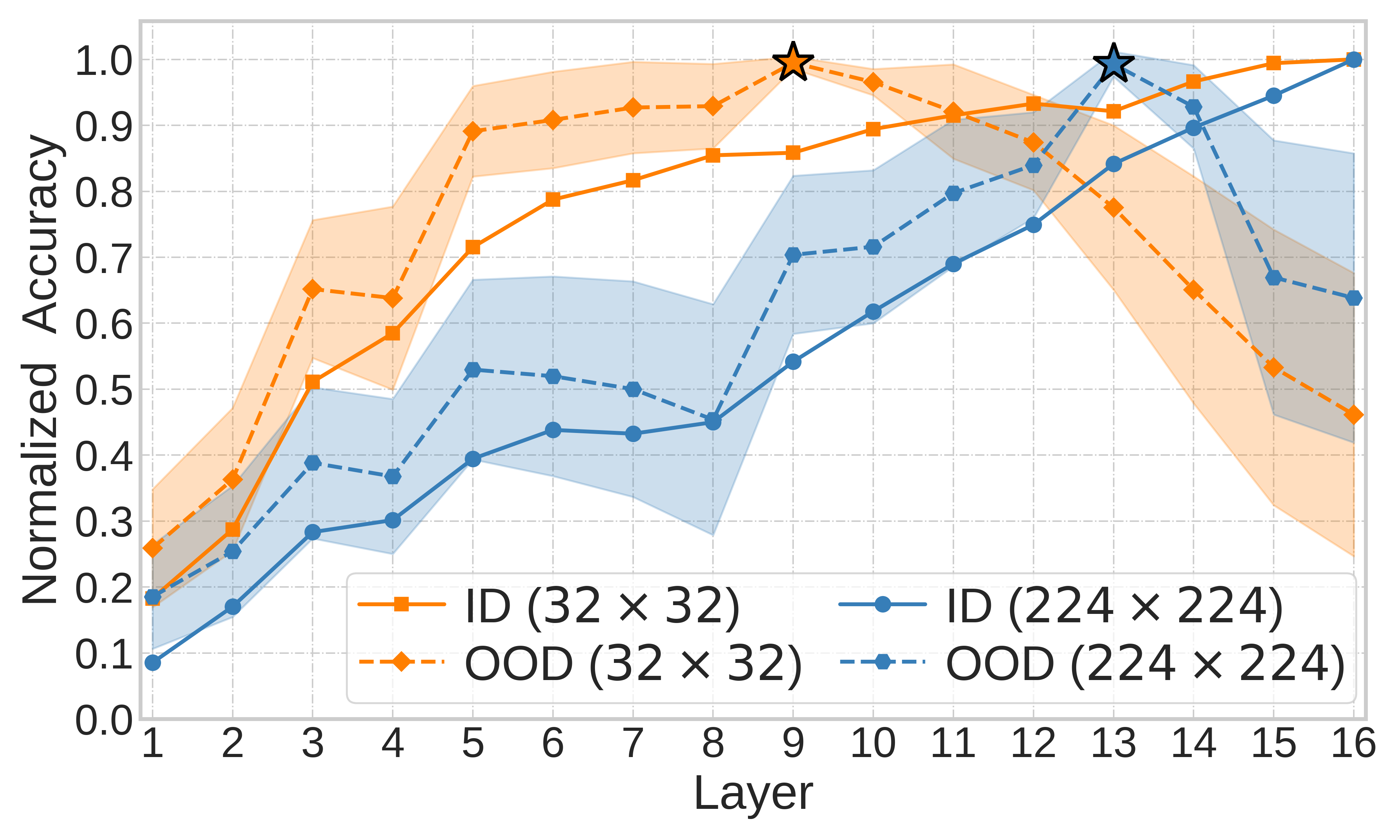
What Variables Affect Out-Of-Distribution Generalization in Pretrained Models?
Md Yousuf Harun, Kyungbok Lee, Jhair Gallardo, Giri Krishnan, Christopher Kanan
0
0
Embeddings produced by pre-trained deep neural networks (DNNs) are widely used; however, their efficacy for downstream tasks can vary widely. We study the factors influencing out-of-distribution (OOD) generalization of pre-trained DNN embeddings through the lens of the tunnel effect hypothesis, which suggests deeper DNN layers compress representations and hinder OOD performance. Contrary to earlier work, we find the tunnel effect is not universal. Based on 10,584 linear probes, we study the conditions that mitigate the tunnel effect by varying DNN architecture, training dataset, image resolution, and augmentations. We quantify each variable's impact using a novel SHAP analysis. Our results emphasize the danger of generalizing findings from toy datasets to broader contexts.
6/13/2024