Incremental Pseudo-Labeling for Black-Box Unsupervised Domain Adaptation

0

Sign in to get full access
Overview
- The paper presents a novel approach called Incremental Pseudo-Labeling (IPL) for Black-Box Unsupervised Domain Adaptation (BBUDA), which aims to improve the performance of machine learning models on target domains without access to labeled target data.
- The key ideas are to leverage the intra-class similarity of samples in the source domain to generate pseudo-labels for the target domain, and incrementally refine these pseudo-labels over multiple iterations.
- The proposed method outperforms state-of-the-art BBUDA techniques on several benchmark tasks, demonstrating its effectiveness in bridging the domain gap without requiring labeled target data.
Plain English Explanation
When training machine learning models, it's often challenging to obtain labeled data for the specific scenario or "domain" you want to apply the model to. This is known as the domain adaptation problem. FPL-Filtered Pseudo-Label-Based Unsupervised Cross-Modal Adaptation and Pseudo-Label Refinery for Unsupervised Domain Adaptation in Cross-Modal Retrieval have proposed techniques to tackle this issue.
The paper introduces a new approach called Incremental Pseudo-Labeling (IPL) that can improve model performance on the target domain without access to any labeled data from that domain. The key idea is to leverage the similarity between samples in the source domain to generate "pseudo-labels" for the target domain, and then gradually refine these pseudo-labels over multiple iterations.
For example, imagine you have a model trained to recognize different types of cars. If you want to apply this model to identify cars in a new city, you may encounter vehicles with different appearances due to the local environment. IPL can help adapt the model to this new domain by using the similarities between the cars in the original dataset to infer likely labels for the cars in the new city, and then iteratively improving those labels over time.
By incorporating this incremental pseudo-labeling approach, the proposed method is able to outperform other state-of-the-art techniques for Black-Box Unsupervised Domain Adaptation (BBUDA), which do not require access to labeled data from the target domain. This makes the model more versatile and applicable to a wider range of real-world scenarios.
Technical Explanation
The Incremental Pseudo-Labeling (IPL) approach proposed in the paper aims to address the Black-Box Unsupervised Domain Adaptation (BBUDA) problem, where the goal is to adapt a machine learning model trained on a source domain to perform well on a target domain without access to any labeled data from the target domain.
The key components of the IPL method are:
-
Intra-class Similarity: The authors leverage the observation that samples within the same class in the source domain tend to have high similarity. This property is used to generate pseudo-labels for the target domain.
-
Incremental Pseudo-Label Refinement: The pseudo-labels for the target domain are iteratively refined over multiple stages, incorporating the model's predictions and the intra-class similarity information.
-
Black-Box Adaptation: The proposed IPL approach is designed to work in a black-box setting, where the model architecture and training process are treated as a black box, without requiring any modifications to the underlying model.
The IPL method works as follows:
-
Initialization: The model is first trained on the labeled source domain data using standard supervised learning techniques.
-
Pseudo-Label Generation: For each target domain sample, the model's predictions are used to identify the top-k nearest neighbors from the source domain. The pseudo-label for the target sample is then assigned based on the majority class of these nearest neighbors.
-
Incremental Refinement: In subsequent iterations, the pseudo-labels are refined by considering both the model's predictions and the intra-class similarity information from the source domain. This helps to correct any misclassifications in the initial pseudo-labels.
-
Black-Box Adaptation: The refined pseudo-labels are used to fine-tune the model, allowing it to adapt to the target domain without accessing any labeled target data.
The authors evaluate the proposed IPL method on several benchmark datasets for domain adaptation, including image classification and semantic segmentation tasks. The results demonstrate that IPL outperforms other state-of-the-art BBUDA techniques, such as Style Adaptation for Domain-Adaptive Semantic Segmentation, Multi-Target Unsupervised Domain Adaptation for Semantic Segmentation, and Achieving Reliable and Fair Skin Lesion Diagnosis via Weakly Supervised Attention-guided Deep Neural Networks.
Critical Analysis
The paper presents a novel and effective approach for Black-Box Unsupervised Domain Adaptation (BBUDA), which is an important problem in machine learning with many real-world applications. The key strengths of the proposed Incremental Pseudo-Labeling (IPL) method are its ability to leverage the intra-class similarity in the source domain to generate accurate pseudo-labels for the target domain, and the iterative refinement process that helps to correct any initial misclassifications.
One potential limitation of the IPL method is that it relies on the assumption that the intra-class similarity in the source domain will translate well to the target domain. In cases where the domain shift is significant, this assumption may not hold, and the initial pseudo-labels may be less reliable. The authors acknowledge this limitation and suggest that incorporating additional domain adaptation techniques could help address this issue.
Additionally, the paper does not explore the scalability of the IPL method to large-scale datasets or its robustness to noisy or incomplete source domain data. Further research in these areas could help to understand the practical limitations and potential improvements to the IPL approach.
Overall, the Incremental Pseudo-Labeling method presented in this paper is a promising contribution to the field of unsupervised domain adaptation, and the authors have demonstrated its effectiveness on several benchmark tasks. Continued research and development in this area could lead to more robust and adaptable machine learning models that can be deployed in a wider range of real-world scenarios.
Conclusion
The paper introduces a novel Incremental Pseudo-Labeling (IPL) approach for Black-Box Unsupervised Domain Adaptation (BBUDA), which aims to improve the performance of machine learning models on target domains without access to any labeled data from that domain.
The key innovation of the IPL method is its ability to leverage the intra-class similarity of samples in the source domain to generate accurate pseudo-labels for the target domain, and then iteratively refine these pseudo-labels over multiple stages. This incremental refinement process helps to correct any initial misclassifications and allows the model to adapt to the target domain effectively.
The experimental results demonstrate that the proposed IPL method outperforms other state-of-the-art BBUDA techniques on a range of benchmark tasks, including image classification and semantic segmentation. This highlights the potential of the IPL approach to enable more versatile and adaptable machine learning models that can be deployed in a wider variety of real-world scenarios.
While the paper identifies some limitations, such as the reliance on the assumption of strong intra-class similarity, the Incremental Pseudo-Labeling method represents an important advancement in the field of unsupervised domain adaptation. Further research and development in this area could lead to even more robust and effective techniques for bridging the domain gap without requiring labeled target data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Incremental Pseudo-Labeling for Black-Box Unsupervised Domain Adaptation
Yawen Zou, Chunzhi Gu, Jun Yu, Shangce Gao, Chao Zhang
Black-Box unsupervised domain adaptation (BBUDA) learns knowledge only with the prediction of target data from the source model without access to the source data and source model, which attempts to alleviate concerns about the privacy and security of data. However, incorrect pseudo-labels are prevalent in the prediction generated by the source model due to the cross-domain discrepancy, which may substantially degrade the performance of the target model. To address this problem, we propose a novel approach that incrementally selects high-confidence pseudo-labels to improve the generalization ability of the target model. Specifically, we first generate pseudo-labels using a source model and train a crude target model by a vanilla BBUDA method. Second, we iteratively select high-confidence data from the low-confidence data pool by thresholding the softmax probabilities, prototype labels, and intra-class similarity. Then, we iteratively train a stronger target network based on the crude target model to correct the wrongly labeled samples to improve the accuracy of the pseudo-label. Experimental results demonstrate that the proposed method achieves state-of-the-art black-box unsupervised domain adaptation performance on three benchmark datasets.
Read more5/28/2024
0
FPL+: Filtered Pseudo Label-based Unsupervised Cross-Modality Adaptation for 3D Medical Image Segmentation
Jianghao Wu, Dong Guo, Guotai Wang, Qiang Yue, Huijun Yu, Kang Li, Shaoting Zhang
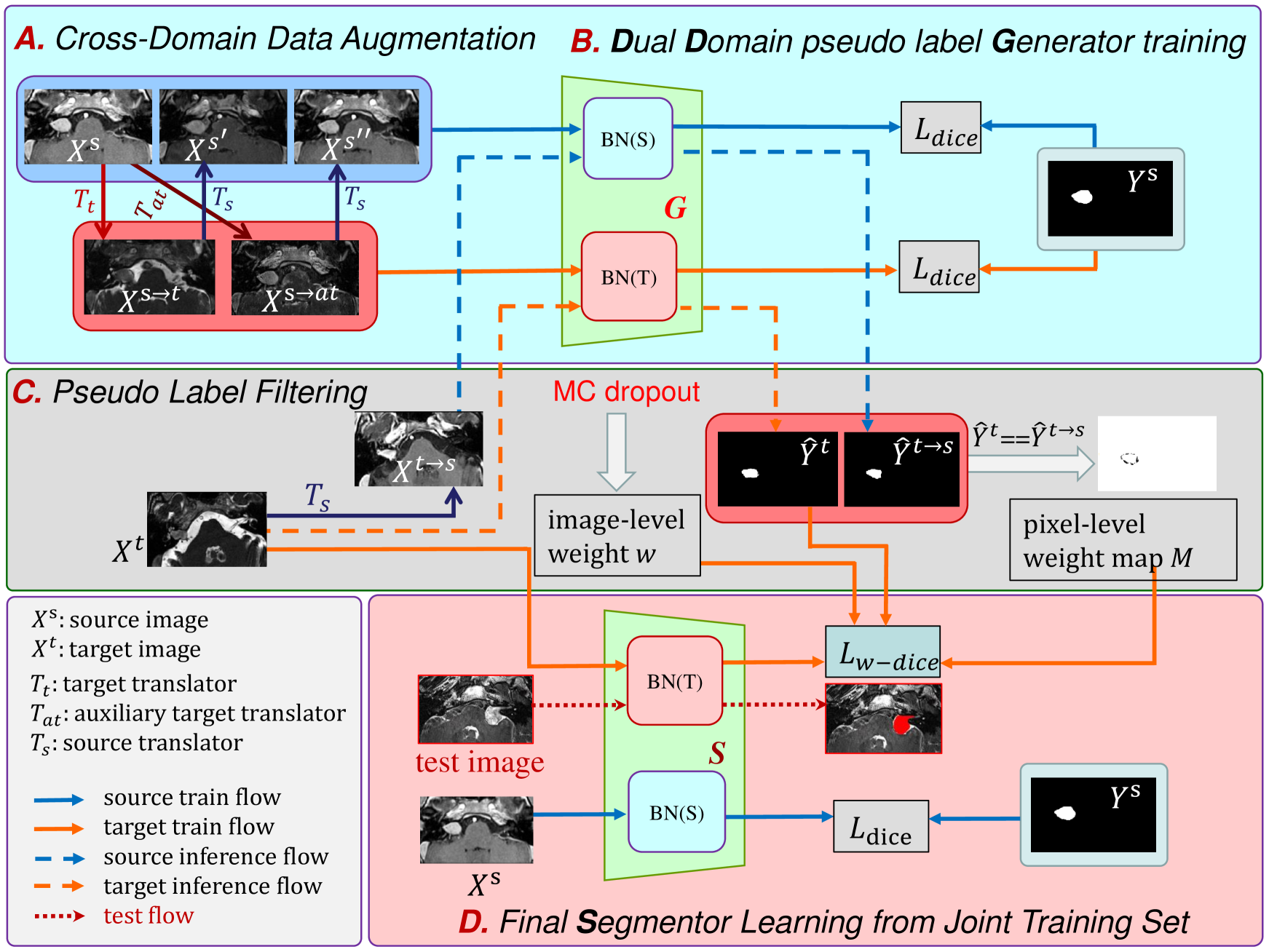
Adapting a medical image segmentation model to a new domain is important for improving its cross-domain transferability, and due to the expensive annotation process, Unsupervised Domain Adaptation (UDA) is appealing where only unlabeled images are needed for the adaptation. Existing UDA methods are mainly based on image or feature alignment with adversarial training for regularization, and they are limited by insufficient supervision in the target domain. In this paper, we propose an enhanced Filtered Pseudo Label (FPL+)-based UDA method for 3D medical image segmentation. It first uses cross-domain data augmentation to translate labeled images in the source domain to a dual-domain training set consisting of a pseudo source-domain set and a pseudo target-domain set. To leverage the dual-domain augmented images to train a pseudo label generator, domain-specific batch normalization layers are used to deal with the domain shift while learning the domain-invariant structure features, generating high-quality pseudo labels for target-domain images. We then combine labeled source-domain images and target-domain images with pseudo labels to train a final segmentor, where image-level weighting based on uncertainty estimation and pixel-level weighting based on dual-domain consensus are proposed to mitigate the adverse effect of noisy pseudo labels. Experiments on three public multi-modal datasets for Vestibular Schwannoma, brain tumor and whole heart segmentation show that our method surpassed ten state-of-the-art UDA methods, and it even achieved better results than fully supervised learning in the target domain in some cases.
Read more4/9/2024

0
Pseudo Label Refinery for Unsupervised Domain Adaptation on Cross-dataset 3D Object Detection
Zhanwei Zhang, Minghao Chen, Shuai Xiao, Liang Peng, Hengjia Li, Binbin Lin, Ping Li, Wenxiao Wang, Boxi Wu, Deng Cai
Recent self-training techniques have shown notable improvements in unsupervised domain adaptation for 3D object detection (3D UDA). These techniques typically select pseudo labels, i.e., 3D boxes, to supervise models for the target domain. However, this selection process inevitably introduces unreliable 3D boxes, in which 3D points cannot be definitively assigned as foreground or background. Previous techniques mitigate this by reweighting these boxes as pseudo labels, but these boxes can still poison the training process. To resolve this problem, in this paper, we propose a novel pseudo label refinery framework. Specifically, in the selection process, to improve the reliability of pseudo boxes, we propose a complementary augmentation strategy. This strategy involves either removing all points within an unreliable box or replacing it with a high-confidence box. Moreover, the point numbers of instances in high-beam datasets are considerably higher than those in low-beam datasets, also degrading the quality of pseudo labels during the training process. We alleviate this issue by generating additional proposals and aligning RoI features across different domains. Experimental results demonstrate that our method effectively enhances the quality of pseudo labels and consistently surpasses the state-of-the-art methods on six autonomous driving benchmarks. Code will be available at https://github.com/Zhanwei-Z/PERE.
Read more5/1/2024
0
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
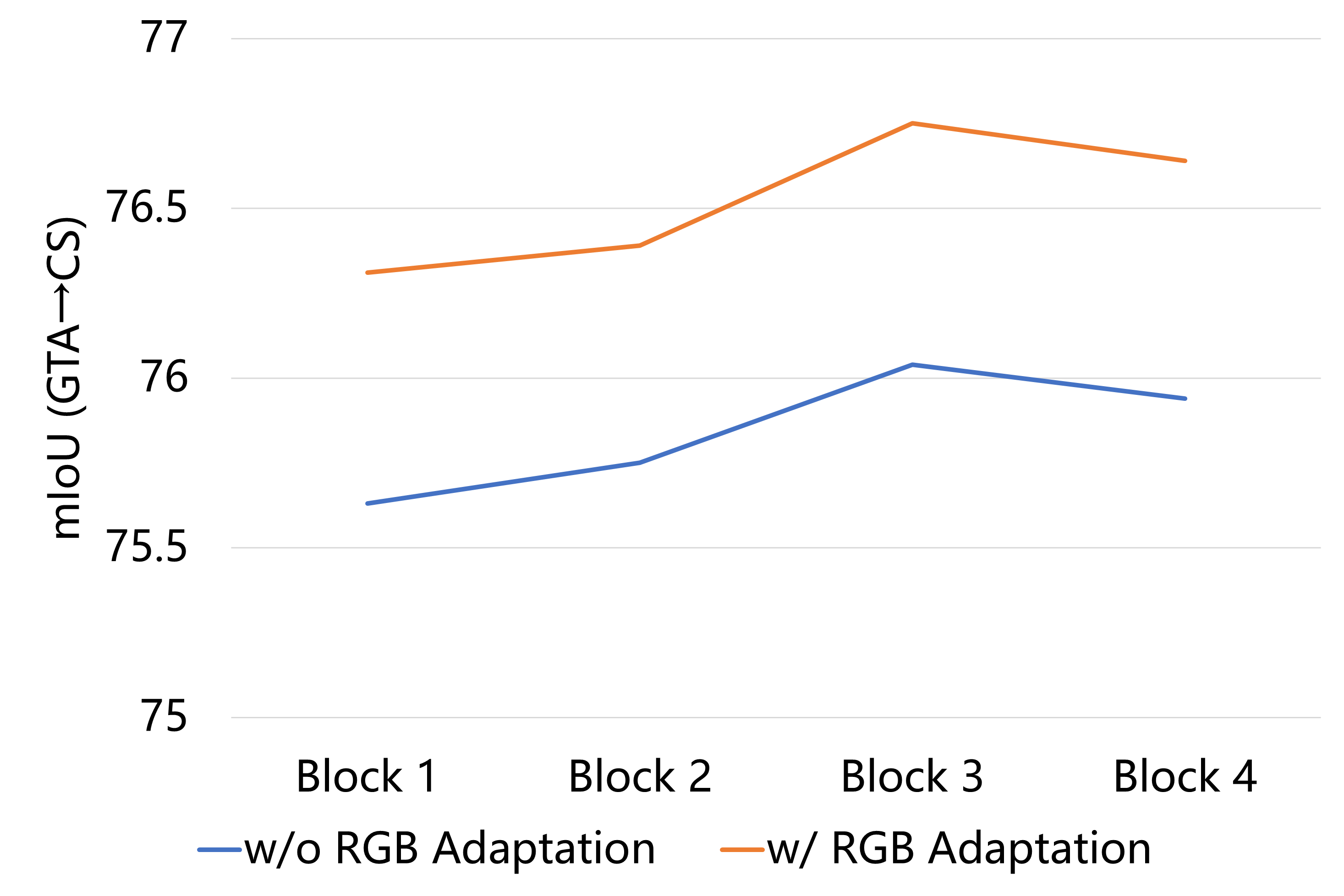
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
Read more4/26/2024