Style Adaptation for Domain-adaptive Semantic Segmentation

0
Sign in to get full access
Overview
- This paper proposes a style adaptation approach for domain-adaptive semantic segmentation.
- The goal is to improve the performance of a semantic segmentation model when applied to a new domain with different visual characteristics.
- The approach involves adversarial training to align the feature distributions between the source and target domains.
Plain English Explanation
The paper looks at the problem of semantic segmentation, which is the task of assigning a label to each pixel in an image. This is a useful capability for applications like self-driving cars or medical image analysis.
However, the performance of semantic segmentation models can degrade when applied to new environments or datasets that have different visual characteristics, like different lighting, camera angles, or objects. This is known as the domain adaptation problem.
The key idea in this paper is to focus on adapting the "style" of the images, rather than just the content. The authors propose an adversarial training approach that encourages the model to learn features that are invariant to the visual style of the input images, while still preserving the semantic information needed for accurate segmentation.
By aligning the feature distributions between the original training domain and the new target domain, the model can generalize better and maintain its performance when applied to the new environment. This style adaptation technique is shown to outperform other domain adaptation methods on several benchmark datasets.
Technical Explanation
The paper introduces a style adaptation module that is integrated into a semantic segmentation model. This module consists of a style feature extractor and a style classifier that work in an adversarial manner.
The style feature extractor tries to capture the visual style of the input images, while the style classifier attempts to predict the domain (source or target) from these style features. The two components are trained in competition, forcing the feature extractor to learn style-invariant representations that are useful for segmentation, but not easily identifiable as belonging to a particular domain.
This style adaptation module is combined with a standard segmentation backbone network (e.g. UNet) and trained using a multi-task loss that includes both segmentation and style adaptation objectives.
Experiments are conducted on several benchmark datasets for unsupervised domain adaptation in semantic segmentation, including Cityscapes, GTA5, and SYNTHIA. The results demonstrate that the proposed style adaptation approach outperforms other state-of-the-art domain adaptation methods.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the style adaptation approach, comparing it to multiple baselines on several challenging datasets. The authors also discuss potential limitations and areas for future work.
One key limitation is that the style adaptation module adds additional complexity and computational overhead to the segmentation model. This could be a concern for deployment in real-world applications with strict latency or resource constraints.
Additionally, the paper does not explore the interpretability of the learned style representations or how they relate to the underlying visual characteristics of the domains. Further analysis in this direction could provide more insights into the mechanism of the style adaptation approach.
Overall, the paper makes a compelling case for the effectiveness of style-based domain adaptation for semantic segmentation, and the proposed technique represents a promising direction for improving the cross-domain generalization of computer vision models.
Conclusion
This paper introduces a novel style adaptation approach for domain-adaptive semantic segmentation. By aligning the feature distributions between source and target domains in a adversarial manner, the model can learn representations that are robust to changes in visual style while preserving the semantic information needed for accurate segmentation.
The experimental results demonstrate the effectiveness of this style adaptation technique, which outperforms other state-of-the-art domain adaptation methods on several benchmark datasets. While the added complexity is a potential limitation, the paper's contribution represents an important step towards building more reliable and generalizable computer vision systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Style Adaptation for Domain-adaptive Semantic Segmentation
Ting Li, Jianshu Chao, Deyu An
Unsupervised Domain Adaptation (UDA) refers to the method that utilizes annotated source domain data and unlabeled target domain data to train a model capable of generalizing to the target domain data. Domain discrepancy leads to a significant decrease in the performance of general network models trained on the source domain data when applied to the target domain. We introduce a straightforward approach to mitigate the domain discrepancy, which necessitates no additional parameter calculations and seamlessly integrates with self-training-based UDA methods. Through the transfer of the target domain style to the source domain in the latent feature space, the model is trained to prioritize the target domain style during the decision-making process. We tackle the problem at both the image-level and shallow feature map level by transferring the style information from the target domain to the source domain data. As a result, we obtain a model that exhibits superior performance on the target domain. Our method yields remarkable enhancements in the state-of-the-art performance for synthetic-to-real UDA tasks. For example, our proposed method attains a noteworthy UDA performance of 76.93 mIoU on the GTA->Cityscapes dataset, representing a notable improvement of +1.03 percentage points over the previous state-of-the-art results.
Read more4/26/2024
🤷
0
Multi-Target Unsupervised Domain Adaptation for Semantic Segmentation without External Data
Yonghao Xu, Pedram Ghamisi, Yannis Avrithis
Multi-target unsupervised domain adaptation (UDA) aims to learn a unified model to address the domain shift between multiple target domains. Due to the difficulty of obtaining annotations for dense predictions, it has recently been introduced into cross-domain semantic segmentation. However, most existing solutions require labeled data from the source domain and unlabeled data from multiple target domains concurrently during training. Collectively, we refer to this data as external. When faced with new unlabeled data from an unseen target domain, these solutions either do not generalize well or require retraining from scratch on all data. To address these challenges, we introduce a new strategy called multi-target UDA without external data for semantic segmentation. Specifically, the segmentation model is initially trained on the external data. Then, it is adapted to a new unseen target domain without accessing any external data. This approach is thus more scalable than existing solutions and remains applicable when external data is inaccessible. We demonstrate this strategy using a simple method that incorporates self-distillation and adversarial learning, where knowledge acquired from the external data is preserved during adaptation through one-way adversarial learning. Extensive experiments in several synthetic-to-real and real-to-real adaptation settings on four benchmark urban driving datasets show that our method significantly outperforms current state-of-the-art solutions, even in the absence of external data. Our source code is available online (https://github.com/YonghaoXu/UT-KD).
Read more5/13/2024
🤷
0
Unsupervised Domain Adaptation via Style-Aware Self-intermediate Domain
Lianyu Wang, Meng Wang, Daoqiang Zhang, Huazhu Fu
Unsupervised domain adaptation (UDA) has attracted considerable attention, which transfers knowledge from a label-rich source domain to a related but unlabeled target domain. Reducing inter-domain differences has always been a crucial factor to improve performance in UDA, especially for tasks where there is a large gap between source and target domains. To this end, we propose a novel style-aware feature fusion method (SAFF) to bridge the large domain gap and transfer knowledge while alleviating the loss of class-discriminative information. Inspired by the human transitive inference and learning ability, a novel style-aware self-intermediate domain (SSID) is investigated to link two seemingly unrelated concepts through a series of intermediate auxiliary synthesized concepts. Specifically, we propose a novel learning strategy of SSID, which selects samples from both source and target domains as anchors, and then randomly fuses the object and style features of these anchors to generate labeled and style-rich intermediate auxiliary features for knowledge transfer. Moreover, we design an external memory bank to store and update specified labeled features to obtain stable class features and class-wise style features. Based on the proposed memory bank, the intra- and inter-domain loss functions are designed to improve the class recognition ability and feature compatibility, respectively. Meanwhile, we simulate the rich latent feature space of SSID by infinite sampling and the convergence of the loss function by mathematical theory. Finally, we conduct comprehensive experiments on commonly used domain adaptive benchmarks to evaluate the proposed SAFF, and the experimental results show that the proposed SAFF can be easily combined with different backbone networks and obtain better performance as a plug-in-plug-out module.
Read more8/28/2024
0
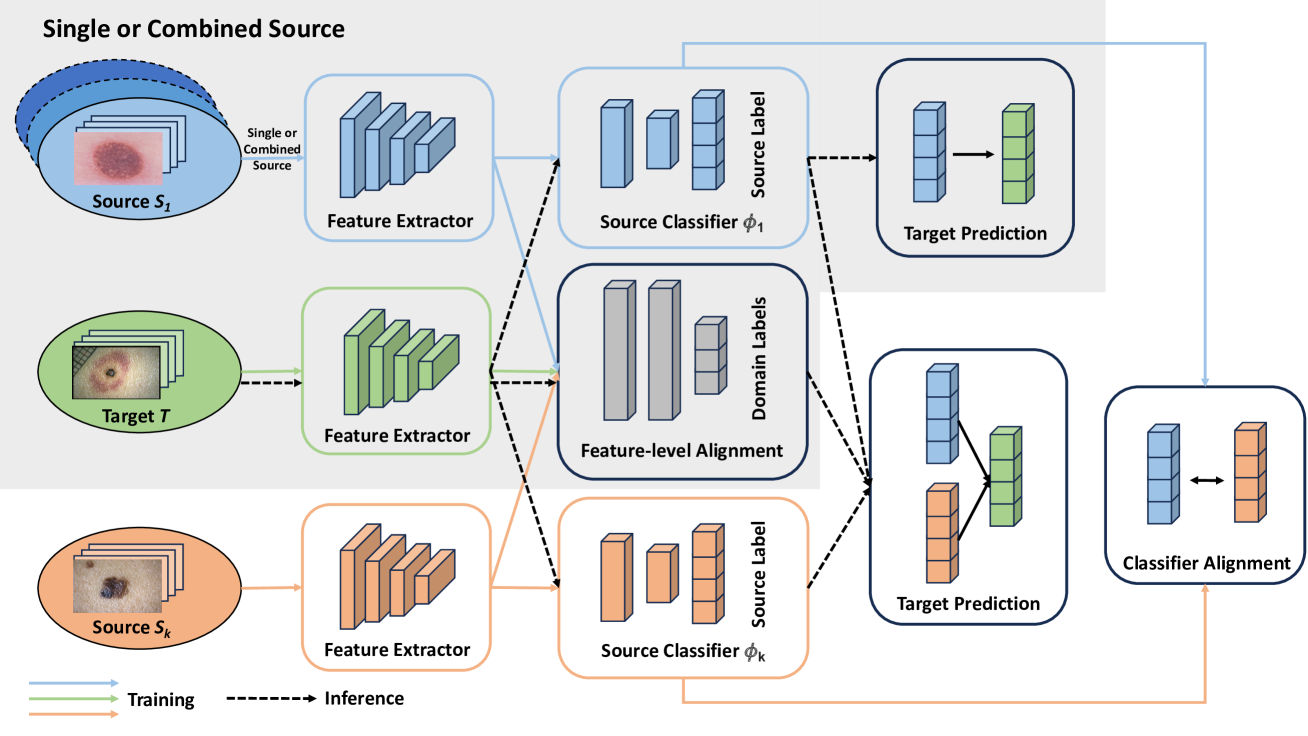
Achieving Reliable and Fair Skin Lesion Diagnosis via Unsupervised Domain Adaptation
Janet Wang, Yunbei Zhang, Zhengming Ding, Jihun Hamm
The development of reliable and fair diagnostic systems is often constrained by the scarcity of labeled data. To address this challenge, our work explores the feasibility of unsupervised domain adaptation (UDA) to integrate large external datasets for developing reliable classifiers. The adoption of UDA with multiple sources can simultaneously enrich the training set and bridge the domain gap between different skin lesion datasets, which vary due to distinct acquisition protocols. Particularly, UDA shows practical promise for improving diagnostic reliability when training with a custom skin lesion dataset, where only limited labeled data are available from the target domain. In this study, we investigate three UDA training schemes based on source data utilization: single-source, combined-source, and multi-source UDA. Our findings demonstrate the effectiveness of applying UDA on multiple sources for binary and multi-class classification. A strong correlation between test error and label shift in multi-class tasks has been observed in the experiment. Crucially, our study shows that UDA can effectively mitigate bias against minority groups and enhance fairness in diagnostic systems, while maintaining superior classification performance. This is achieved even without directly implementing fairness-focused techniques. This success is potentially attributed to the increased and well-adapted demographic information obtained from multiple sources.
Read more4/17/2024