Inductive Generalization in Reinforcement Learning from Specifications
2406.03651
0
0

Abstract
We present a novel inductive generalization framework for RL from logical specifications. Many interesting tasks in RL environments have a natural inductive structure. These inductive tasks have similar overarching goals but they differ inductively in low-level predicates and distributions. We present a generalization procedure that leverages this inductive relationship to learn a higher-order function, a policy generator, that generates appropriately adapted policies for instances of an inductive task in a zero-shot manner. An evaluation of the proposed approach on a set of challenging control benchmarks demonstrates the promise of our framework in generalizing to unseen policies for long-horizon tasks.
Create account to get full access
Overview
- This paper explores a novel approach to reinforcement learning (RL) where the agent learns to generalize from high-level specifications rather than low-level rewards.
- The key idea is to learn a set of "foundation policies" that can be combined in different ways to solve a wide range of tasks, rather than learning a single task-specific policy.
- The authors demonstrate their approach on a set of challenging RL tasks and show that it can outperform standard RL methods in terms of sample efficiency and performance.
Plain English Explanation
In traditional reinforcement learning, an agent learns to perform a specific task by receiving rewards or penalties for its actions. However, this can be slow and inefficient, especially when the agent needs to learn multiple, related tasks.
The paper's approach aims to address this by having the agent learn a set of "foundation policies" - general skills or behaviors that can be combined in different ways to solve a wide range of tasks. These foundation policies are learned from high-level task specifications, rather than low-level rewards.
For example, imagine an agent that needs to learn how to navigate a maze. Instead of just learning how to get from the start to the finish, the agent would learn foundational skills like moving forward, turning left or right, and avoiding obstacles. These could then be combined in different ways to solve various maze configurations.
By learning these more general skills, the agent can generalize and apply them to solve new tasks more efficiently, without having to learn everything from scratch. This can lead to faster and more robust learning, which is especially important in complex environments where the agent needs to adapt to changing conditions.
Technical Explanation
The core idea of this paper is to learn a set of foundation policies that can be combined in different ways to solve a wide range of tasks, rather than learning a single task-specific policy.
To achieve this, the authors propose an approach where the agent learns from high-level task specifications, rather than low-level rewards. These specifications describe the desired behavior of the agent in abstract terms, without prescribing the exact sequence of actions.
The agent then learns a set of foundation policies that can be combined to satisfy these specifications. The authors show that this approach can outperform standard RL methods in terms of sample efficiency and performance on a range of challenging tasks.
One key insight is that by learning more general skills, the agent can generalize and apply them to solve new tasks more efficiently, without having to learn everything from scratch. This is especially important in complex environments where the agent needs to adapt to changing conditions.
Critical Analysis
The authors present a promising approach to improving the sample efficiency and performance of reinforcement learning agents. By learning a set of foundation policies rather than a single task-specific policy, the agent can better generalize and adapt to new situations.
However, the paper does not address some potential limitations and areas for further research. For example, the authors do not discuss how the foundation policies are chosen or learned, or how the agent determines which policies to combine for a given task. Additionally, the experiments are limited to relatively simple environments, and it's unclear how well the approach would scale to more complex, real-world scenarios.
Further research could explore techniques for automatically discovering and learning the foundation policies, as well as methods for efficiently combining them to solve new tasks. Evaluating the approach on more challenging benchmarks would also help to better understand its strengths and limitations.
Conclusion
This paper presents a novel approach to reinforcement learning that aims to improve sample efficiency and performance by learning a set of foundation policies that can be combined in different ways to solve a wide range of tasks. By learning from high-level task specifications rather than low-level rewards, the agent can generalize and apply its skills more effectively to new situations.
While the authors demonstrate promising results, further research is needed to address potential limitations and explore the scalability of the approach. Nevertheless, this work represents an exciting step forward in the field of reinforcement learning, with the potential to lead to more efficient and adaptable agents that can tackle increasingly complex real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Planning with a Learned Policy Basis to Optimally Solve Complex Tasks
Guillermo Infante, David Kuric, Anders Jonsson, Vicenc{c} G'omez, Herke van Hoof
0
0
Conventional reinforcement learning (RL) methods can successfully solve a wide range of sequential decision problems. However, learning policies that can generalize predictably across multiple tasks in a setting with non-Markovian reward specifications is a challenging problem. We propose to use successor features to learn a policy basis so that each (sub)policy in it solves a well-defined subproblem. In a task described by a finite state automaton (FSA) that involves the same set of subproblems, the combination of these (sub)policies can then be used to generate an optimal solution without additional learning. In contrast to other methods that combine (sub)policies via planning, our method asymptotically attains global optimality, even in stochastic environments.
6/4/2024
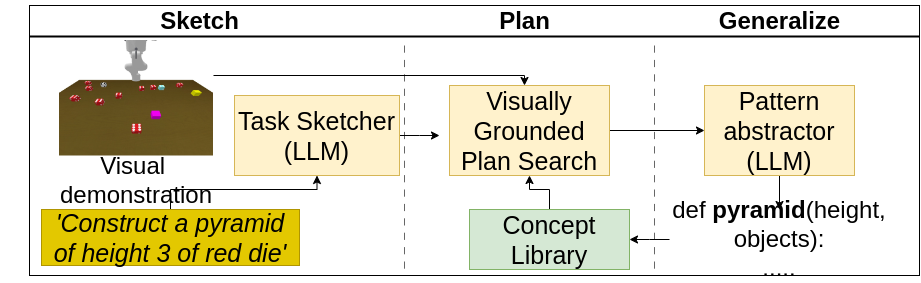
Sketch-Plan-Generalize: Continual Few-Shot Learning of Inductively Generalizable Spatial Concepts for Language-Guided Robot Manipulation
Namasivayam Kalithasan, Sachit Sachdeva, Himanshu Gaurav Singh, Vishal Bindal, Arnav Tuli, Gurarmaan Singh Panjeta, Divyanshu Aggarwal, Rohan Paul, Parag Singla
0
0
Our goal is to enable embodied agents to learn inductively generalizable spatial concepts, e.g., learning staircase as an inductive composition of towers of increasing height. Given a human demonstration, we seek a learning architecture that infers a succinct ${program}$ representation that explains the observed instance. Additionally, the approach should generalize inductively to novel structures of different sizes or complex structures expressed as a hierarchical composition of previously learned concepts. Existing approaches that use code generation capabilities of pre-trained large (visual) language models, as well as purely neural models, show poor generalization to a-priori unseen complex concepts. Our key insight is to factor inductive concept learning as (i) ${it Sketch:}$ detecting and inferring a coarse signature of a new concept (ii) ${it Plan:}$ performing MCTS search over grounded action sequences (iii) ${it Generalize:}$ abstracting out grounded plans as inductive programs. Our pipeline facilitates generalization and modular reuse, enabling continual concept learning. Our approach combines the benefits of the code generation ability of large language models (LLM) along with grounded neural representations, resulting in neuro-symbolic programs that show stronger inductive generalization on the task of constructing complex structures in relation to LLM-only and neural-only approaches. Furthermore, we demonstrate reasoning and planning capabilities with learned concepts for embodied instruction following.
5/30/2024
🏅
Logical Specifications-guided Dynamic Task Sampling for Reinforcement Learning Agents
Yash Shukla, Tanushree Burman, Abhishek Kulkarni, Robert Wright, Alvaro Velasquez, Jivko Sinapov
0
0
Reinforcement Learning (RL) has made significant strides in enabling artificial agents to learn diverse behaviors. However, learning an effective policy often requires a large number of environment interactions. To mitigate sample complexity issues, recent approaches have used high-level task specifications, such as Linear Temporal Logic (LTL$_f$) formulas or Reward Machines (RM), to guide the learning progress of the agent. In this work, we propose a novel approach, called Logical Specifications-guided Dynamic Task Sampling (LSTS), that learns a set of RL policies to guide an agent from an initial state to a goal state based on a high-level task specification, while minimizing the number of environmental interactions. Unlike previous work, LSTS does not assume information about the environment dynamics or the Reward Machine, and dynamically samples promising tasks that lead to successful goal policies. We evaluate LSTS on a gridworld and show that it achieves improved time-to-threshold performance on complex sequential decision-making problems compared to state-of-the-art RM and Automaton-guided RL baselines, such as Q-Learning for Reward Machines and Compositional RL from logical Specifications (DIRL). Moreover, we demonstrate that our method outperforms RM and Automaton-guided RL baselines in terms of sample-efficiency, both in a partially observable robotic task and in a continuous control robotic manipulation task.
4/4/2024

Foundation Policies with Hilbert Representations
Seohong Park, Tobias Kreiman, Sergey Levine
0
0
Unsupervised and self-supervised objectives, such as next token prediction, have enabled pre-training generalist models from large amounts of unlabeled data. In reinforcement learning (RL), however, finding a truly general and scalable unsupervised pre-training objective for generalist policies from offline data remains a major open question. While a number of methods have been proposed to enable generic self-supervised RL, based on principles such as goal-conditioned RL, behavioral cloning, and unsupervised skill learning, such methods remain limited in terms of either the diversity of the discovered behaviors, the need for high-quality demonstration data, or the lack of a clear adaptation mechanism for downstream tasks. In this work, we propose a novel unsupervised framework to pre-train generalist policies that capture diverse, optimal, long-horizon behaviors from unlabeled offline data such that they can be quickly adapted to any arbitrary new tasks in a zero-shot manner. Our key insight is to learn a structured representation that preserves the temporal structure of the underlying environment, and then to span this learned latent space with directional movements, which enables various zero-shot policy prompting schemes for downstream tasks. Through our experiments on simulated robotic locomotion and manipulation benchmarks, we show that our unsupervised policies can solve goal-conditioned and general RL tasks in a zero-shot fashion, even often outperforming prior methods designed specifically for each setting. Our code and videos are available at https://seohong.me/projects/hilp/.
5/28/2024