Planning with a Learned Policy Basis to Optimally Solve Complex Tasks
2403.15301
0
0

Abstract
Conventional reinforcement learning (RL) methods can successfully solve a wide range of sequential decision problems. However, learning policies that can generalize predictably across multiple tasks in a setting with non-Markovian reward specifications is a challenging problem. We propose to use successor features to learn a policy basis so that each (sub)policy in it solves a well-defined subproblem. In a task described by a finite state automaton (FSA) that involves the same set of subproblems, the combination of these (sub)policies can then be used to generate an optimal solution without additional learning. In contrast to other methods that combine (sub)policies via planning, our method asymptotically attains global optimality, even in stochastic environments.
Create account to get full access
Overview
- This paper presents a novel planning approach that leverages a learned policy basis to efficiently solve complex tasks.
- The proposed method combines reinforcement learning and planning to enable agents to tackle challenging problems that require long-term reasoning.
- Key contributions include a framework for learning a compact policy basis and a planning algorithm that optimally selects and combines basis policies to solve target tasks.
Plain English Explanation
The paper discusses a new way for AI systems to plan and solve complex problems. Traditional AI planning methods can struggle with tasks that require a lot of long-term thinking and decision-making. This paper introduces a technique that combines reinforcement learning (where an AI agent learns by trial-and-error) with planning (where the agent reasons about the best sequence of actions to take).
The core idea is to first train the AI agent to learn a set of "basis policies" - fundamental skills or behaviors that can be combined in different ways. Then, when faced with a new, complex task, the agent can plan the optimal way to piece together these basis policies to solve the overall problem efficiently.
This approach allows the agent to leverage its prior learning, rather than having to start from scratch for each new task. By having a library of useful building blocks, the agent can focus its planning on how to assemble them in the right way, rather than having to figure out the low-level skills from the ground up.
The paper demonstrates this technique on a number of challenging simulated environments, showing that it can outperform traditional planning methods that don't have the benefit of the learned policy basis. This suggests the approach could be a powerful tool for building AI systems that can tackle complex, real-world problems.
Technical Explanation
The paper introduces a planning with a learned policy basis framework to efficiently solve complex tasks. The key insight is to leverage reinforcement learning to learn a compact set of "basis policies" that capture fundamental skills or behaviors. These basis policies can then be optimally combined through planning to solve target tasks.
The authors propose a two-stage training process. First, they use reinforcement learning to train a set of goal-conditioned basis policies, where each policy is specialized for a particular subtask or skill. Then, they develop a planning algorithm that can efficiently select and compose these basis policies to solve complex, multi-step problems.
The planning algorithm works by backward planning from the goal state, using the basis policies as building blocks. It searches for the optimal sequence of basis policies that can achieve the target task, taking into account the costs and constraints associated with each policy.
The authors evaluate their approach on a range of multi-task reinforcement learning environments, including robotic manipulation and navigation tasks. The results show that their method can outperform traditional planning techniques, particularly on complex problems that require long-term reasoning and coordination of multiple skills.
Critical Analysis
The paper presents a promising approach for enabling AI systems to tackle complex, real-world problems. By learning a set of fundamental skills and then planning how to optimally combine them, the method can leverage prior knowledge to solve new tasks more efficiently.
One potential limitation is the requirement to pre-train the basis policies. While the paper shows this can be done in a sample-efficient way, it may still be challenging to learn a sufficiently comprehensive set of basis policies for highly complex, open-ended domains. Further research is needed to investigate how this approach scales to larger, more diverse problem spaces.
Additionally, the paper does not extensively explore the robustness of the method to changes in the task or environment. It would be valuable to understand how the learned basis policies and planning algorithm perform when faced with novel situations or perturbations, and whether additional mechanisms are needed to ensure reliable and adaptable behavior.
Overall, this work represents an important step towards building AI systems that can flexibly and autonomously solve complex challenges. By combining reinforcement learning and planning in this novel way, the authors have demonstrated a promising path forward for advancing the capabilities of artificial agents.
Conclusion
This paper presents a novel planning framework that leverages a learned policy basis to efficiently solve complex tasks. By first training a set of fundamental, goal-conditioned basis policies using reinforcement learning, the system can then plan the optimal way to combine these building blocks to achieve target objectives.
The key innovation is the two-stage training process, which allows the agent to reuse its prior knowledge when faced with new problems. This enables the system to tackle complex, multi-step challenges that would be difficult to solve from scratch using traditional planning techniques.
The empirical results on challenging simulated environments are promising, suggesting this approach could be a valuable tool for developing AI systems that can flexibly and autonomously tackle real-world problems. Further research is needed to explore the scalability and robustness of the method, but this work represents an important step forward in building more capable and adaptable artificial agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Inductive Generalization in Reinforcement Learning from Specifications
Vignesh Subramanian, Rohit Kushwah, Subhajit Roy, Suguman Bansal
0
0
We present a novel inductive generalization framework for RL from logical specifications. Many interesting tasks in RL environments have a natural inductive structure. These inductive tasks have similar overarching goals but they differ inductively in low-level predicates and distributions. We present a generalization procedure that leverages this inductive relationship to learn a higher-order function, a policy generator, that generates appropriately adapted policies for instances of an inductive task in a zero-shot manner. An evaluation of the proposed approach on a set of challenging control benchmarks demonstrates the promise of our framework in generalizing to unseen policies for long-horizon tasks.
6/7/2024

Backward Learning for Goal-Conditioned Policies
Marc Hoftmann, Jan Robine, Stefan Harmeling
0
0
Can we learn policies in reinforcement learning without rewards? Can we learn a policy just by trying to reach a goal state? We answer these questions positively by proposing a multi-step procedure that first learns a world model that goes backward in time, secondly generates goal-reaching backward trajectories, thirdly improves those sequences using shortest path finding algorithms, and finally trains a neural network policy by imitation learning. We evaluate our method on a deterministic maze environment where the observations are $64times 64$ pixel bird's eye images and can show that it consistently reaches several goals.
4/16/2024

I Know How: Combining Prior Policies to Solve New Tasks
Malio Li, Elia Piccoli, Vincenzo Lomonaco, Davide Bacciu
0
0
Multi-Task Reinforcement Learning aims at developing agents that are able to continually evolve and adapt to new scenarios. However, this goal is challenging to achieve due to the phenomenon of catastrophic forgetting and the high demand of computational resources. Learning from scratch for each new task is not a viable or sustainable option, and thus agents should be able to collect and exploit prior knowledge while facing new problems. While several methodologies have attempted to address the problem from different perspectives, they lack a common structure. In this work, we propose a new framework, I Know How (IKH), which provides a common formalization. Our methodology focuses on modularity and compositionality of knowledge in order to achieve and enhance agent's ability to learn and adapt efficiently to dynamic environments. To support our framework definition, we present a simple application of it in a simulated driving environment and compare its performance with that of state-of-the-art approaches.
6/17/2024
An approach to improve agent learning via guaranteeing goal reaching in all episodes
Pavel Osinenko, Grigory Yaremenko, Georgiy Malaniya, Anton Bolychev
0
0
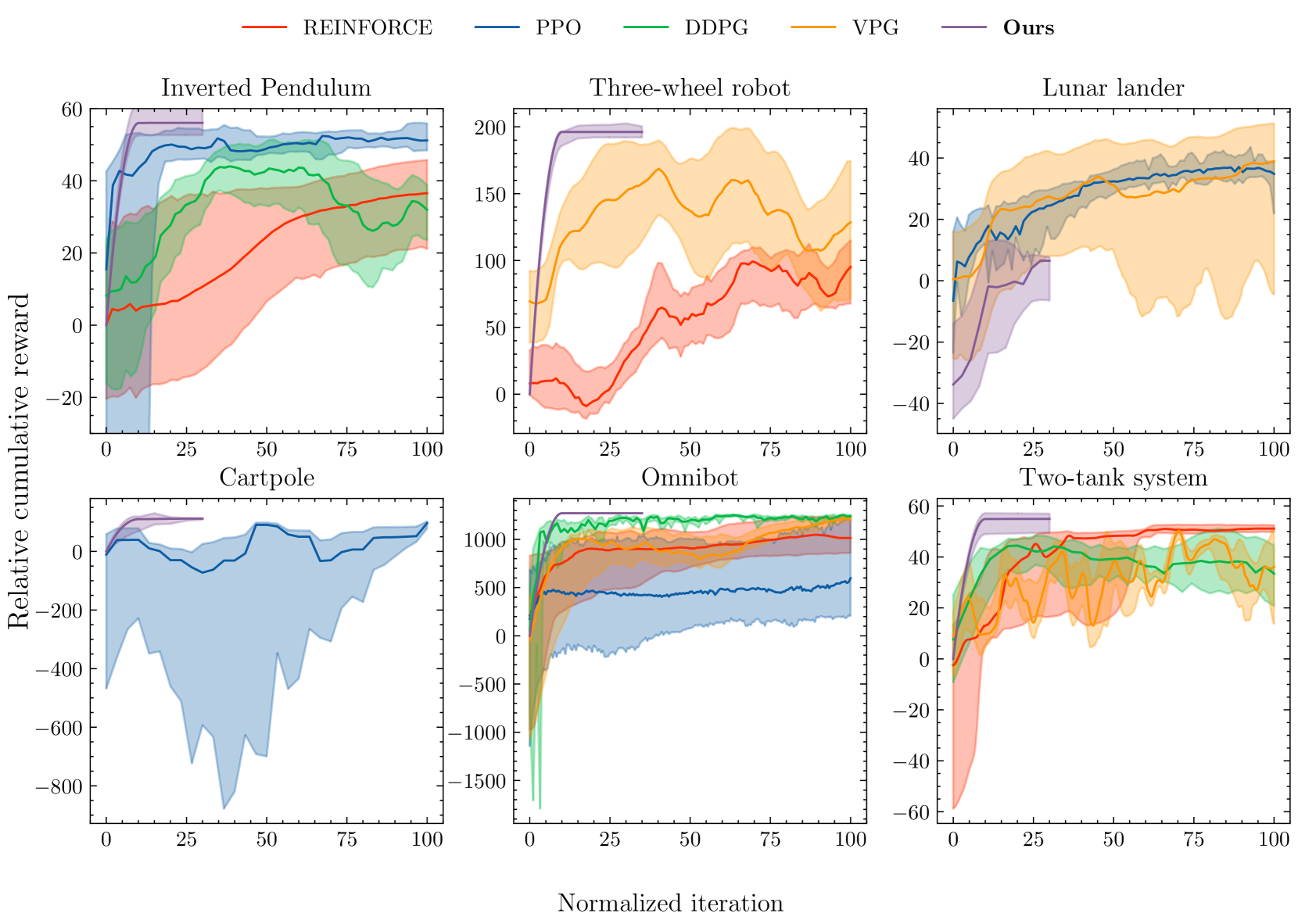
Reinforcement learning is commonly concerned with problems of maximizing accumulated rewards in Markov decision processes. Oftentimes, a certain goal state or a subset of the state space attain maximal reward. In such a case, the environment may be considered solved when the goal is reached. Whereas numerous techniques, learning or non-learning based, exist for solving environments, doing so optimally is the biggest challenge. Say, one may choose a reward rate which penalizes the action effort. Reinforcement learning is currently among the most actively developed frameworks for solving environments optimally by virtue of maximizing accumulated reward, in other words, returns. Yet, tuning agents is a notoriously hard task as reported in a series of works. Our aim here is to help the agent learn a near-optimal policy efficiently while ensuring a goal reaching property of some basis policy that merely solves the environment. We suggest an algorithm, which is fairly flexible, and can be used to augment practically any agent as long as it comprises of a critic. A formal proof of a goal reaching property is provided. Simulation experiments on six problems under five agents, including the benchmarked one, provided an empirical evidence that the learning can indeed be boosted while ensuring goal reaching property.
5/30/2024