InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic KV Cache Management

0
Sign in to get full access
Overview
- This paper introduces InfiniGen, a new approach for efficient generative inference of large language models (LLMs) that uses dynamic key-value (KV) cache management.
- InfiniGen aims to improve the performance and efficiency of LLM inference by optimizing the KV cache, which is a critical component for generating high-quality text.
- The paper presents several key techniques, including layer-condensed KV cache, CacheGen for KV cache compression and streaming, and SnapKV for efficient KV cache access.
- The authors demonstrate that InfiniGen can achieve significant speedups and memory savings compared to existing LLM inference approaches, making it a promising solution for deploying large, powerful language models in real-world applications.
Plain English Explanation
The paper introduces a new system called InfiniGen that aims to make it more efficient to use large language models (LLMs) for generating text. LLMs are powerful AI models that can produce human-like text, but running them can be computationally intensive and require a lot of memory.
To address this, InfiniGen focuses on optimizing a key component of LLMs called the "key-value cache." This cache stores information that the model uses to generate each word in the output text. InfiniGen includes several techniques to make the cache more efficient, such as compressing the cache data and only storing the most important parts of the cache. This allows InfiniGen to run LLMs faster and with less memory than traditional approaches.
The paper shows that InfiniGen can provide significant speedups and memory savings compared to other LLM inference systems, making it easier to deploy powerful language models in real-world applications like chatbots, virtual assistants, and content generation tools. By focusing on optimizing a key internal component of LLMs, the authors have found a way to make these models more practical and accessible.
Technical Explanation
The core innovation of the InfiniGen system is its dynamic key-value (KV) cache management. The KV cache is a critical component of large language models (LLMs) that stores information used to predict the next word in the output sequence. InfiniGen introduces several techniques to optimize the KV cache and improve the efficiency of LLM inference.
First, InfiniGen uses a layer-condensed KV cache that selectively stores only the most important cache entries, reducing the overall cache size. This is based on the observation that not all cache entries contribute equally to the model's performance.
Second, InfiniGen employs a technique called CacheGen to compress the KV cache data, further reducing the memory footprint. CacheGen uses a combination of lossless and lossy compression methods to achieve high compression ratios without significantly impacting the model's accuracy.
Finally, InfiniGen introduces SnapKV, an efficient KV cache access mechanism that allows the model to quickly retrieve the most relevant cache entries during inference. SnapKV uses a pyramidal indexing structure to enable fast cache lookups and updates.
The authors evaluate InfiniGen on a range of large language models, including GPT-3 and Megatron-LM. The results show that InfiniGen can achieve up to 5.6x speedup and 5.2x memory reduction compared to baseline LLM inference approaches, while maintaining comparable text generation quality. These performance gains make InfiniGen a promising solution for deploying powerful language models in real-world applications.
Critical Analysis
The InfiniGen paper presents a well-designed and comprehensive approach to improving the efficiency of large language model inference. The authors have identified the KV cache as a critical component for optimizing LLM performance and have developed several innovative techniques to address this challenge.
One potential limitation of the work is that the evaluations are primarily focused on perplexity and generation quality metrics, rather than end-to-end application-level performance. While these are important metrics, it would be valuable to see how InfiniGen's improvements translate to real-world use cases, such as conversational AI, content generation, or question-answering tasks.
Additionally, the paper does not delve deeply into the potential tradeoffs or downsides of the proposed techniques. For example, the layer-condensed KV cache approach may reduce the model's ability to capture long-range dependencies or generate more diverse outputs. Similarly, the CacheGen compression method could introduce some loss of information that may impact the model's performance in certain scenarios.
It would be valuable for the authors to explore these types of tradeoffs in more depth and provide guidance on when and how to apply the InfiniGen techniques effectively. Additionally, further research on integrating these techniques with other LLM optimization methods, such as model pruning or quantization, could lead to even greater efficiency gains.
Conclusion
The InfiniGen paper presents a novel and highly promising approach for improving the efficiency of large language model inference. By focusing on optimizing the KV cache, a critical component of LLMs, the authors have developed several innovative techniques that can significantly speed up inference and reduce memory usage without sacrificing text generation quality.
These advancements make InfiniGen a compelling solution for deploying powerful language models in real-world applications, where computational and memory constraints are often a significant challenge. As large language models continue to grow in size and capability, research like this will be crucial for ensuring these models can be used effectively and efficiently in a wide range of practical use cases.
Overall, the InfiniGen paper is a valuable contribution to the field of efficient AI inference, and the techniques introduced could have far-reaching implications for the development and deployment of large language models in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic KV Cache Management
Wonbeom Lee, Jungi Lee, Junghwan Seo, Jaewoong Sim
Transformer-based large language models (LLMs) demonstrate impressive performance across various natural language processing tasks. Serving LLM inference for generating long contents, however, poses a challenge due to the enormous memory footprint of the transient state, known as the key-value (KV) cache, which scales with the sequence length and batch size. In this paper, we present InfiniGen, a novel KV cache management framework tailored for long-text generation, which synergistically works with modern offloading-based inference systems. InfiniGen leverages the key insight that a few important tokens that are essential for computing the subsequent attention layer in the Transformer can be speculated by performing a minimal rehearsal with the inputs of the current layer and part of the query weight and key cache of the subsequent layer. This allows us to prefetch only the essential KV cache entries (without fetching them all), thereby mitigating the fetch overhead from the host memory in offloading-based LLM serving systems. Our evaluation on several representative LLMs shows that InfiniGen improves the overall performance of a modern offloading-based system by up to 3.00x compared to prior KV cache management methods while offering substantially better model accuracy.
Read more7/1/2024
🤯
0
Efficient LLM Inference with Kcache
Qiaozhi He, Zhihua Wu
Large Language Models(LLMs) have had a profound impact on AI applications, particularly in the domains of long-text comprehension and generation. KV Cache technology is one of the most widely used techniques in the industry. It ensures efficient sequence generation by caching previously computed KV states. However, it also introduces significant memory overhead. We discovered that KV Cache is not necessary and proposed a novel KCache technique to alleviate the memory bottleneck issue during the LLMs inference process. KCache can be used directly for inference without any training process, Our evaluations show that KCache improves the throughput of popular LLMs by 40% with the baseline, while keeping accuracy.
Read more4/30/2024

0
InstInfer: In-Storage Attention Offloading for Cost-Effective Long-Context LLM Inference
Xiurui Pan, Endian Li, Qiao Li, Shengwen Liang, Yizhou Shan, Ke Zhou, Yingwei Luo, Xiaolin Wang, Jie Zhang
The widespread of Large Language Models (LLMs) marks a significant milestone in generative AI. Nevertheless, the increasing context length and batch size in offline LLM inference escalate the memory requirement of the key-value (KV) cache, which imposes a huge burden on the GPU VRAM, especially for resource-constraint scenarios (e.g., edge computing and personal devices). Several cost-effective solutions leverage host memory or SSDs to reduce storage costs for offline inference scenarios and improve the throughput. Nevertheless, they suffer from significant performance penalties imposed by intensive KV cache accesses due to limited PCIe bandwidth. To address these issues, we propose InstInfer, a novel LLM inference system that offloads the most performance-critical computation (i.e., attention in decoding phase) and data (i.e., KV cache) parts to Computational Storage Drives (CSDs), which minimize the enormous KV transfer overheads. InstInfer designs a dedicated flash-aware in-storage attention engine with KV cache management mechanisms to exploit the high internal bandwidths of CSDs instead of being limited by the PCIe bandwidth. The optimized P2P transmission between GPU and CSDs further reduces data migration overheads. Experimental results demonstrate that for a 13B model using an NVIDIA A6000 GPU, InstInfer improves throughput for long-sequence inference by up to 11.1$times$, compared to existing SSD-based solutions such as FlexGen.
Read more9/10/2024
88
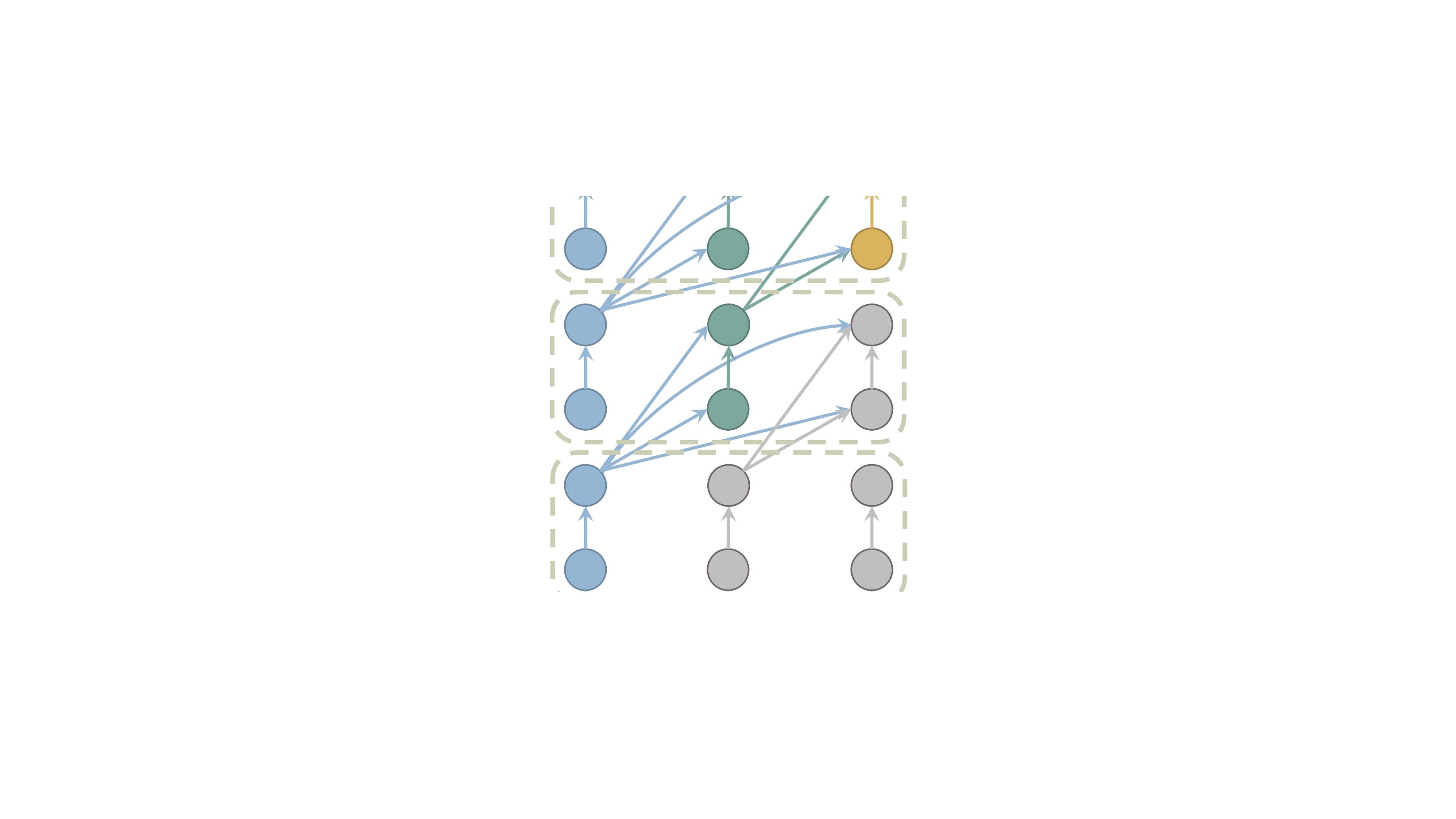
Layer-Condensed KV Cache for Efficient Inference of Large Language Models
Haoyi Wu, Kewei Tu
Huge memory consumption has been a major bottleneck for deploying high-throughput large language models in real-world applications. In addition to the large number of parameters, the key-value (KV) cache for the attention mechanism in the transformer architecture consumes a significant amount of memory, especially when the number of layers is large for deep language models. In this paper, we propose a novel method that only computes and caches the KVs of a small number of layers, thus significantly saving memory consumption and improving inference throughput. Our experiments on large language models show that our method achieves up to 26$times$ higher throughput than standard transformers and competitive performance in language modeling and downstream tasks. In addition, our method is orthogonal to existing transformer memory-saving techniques, so it is straightforward to integrate them with our model, achieving further improvement in inference efficiency. Our code is available at https://github.com/whyNLP/LCKV.
Read more6/5/2024