The Influence of Faulty Labels in Data Sets on Human Pose Estimation

0

Sign in to get full access
Overview
- Examines the impact of faulty labels in datasets on the performance of human pose estimation models
- Proposes a new dataset, PoseBench, to benchmark the robustness of pose estimation models to label noise
- Finds that current state-of-the-art models are significantly affected by label noise, highlighting the need for more robust techniques
Plain English Explanation
Human pose estimation is the task of detecting the positions of key body parts, like the eyes, shoulders, and knees, in images or videos. This information can be used for a variety of applications, such as video analysis, human-computer interaction, and animation.
The paper investigates how the quality of the data used to train these pose estimation models can impact their performance. Specifically, it looks at the effect of having "faulty" or inaccurate labels in the training datasets. For example, if some of the keypoint annotations in the dataset are slightly off, how much does that degrade the model's ability to accurately locate those keypoints in new images?
To study this, the researchers created a new benchmark dataset called PoseBench that contains controlled amounts of label noise. They then evaluated several state-of-the-art pose estimation models on this dataset and found that their performance dropped significantly as the level of noise increased.
This suggests that current pose estimation models are quite sensitive to label quality in the training data. The researchers argue this is an important issue that needs to be addressed, as real-world datasets often contain some degree of annotation errors or inconsistencies. Developing more robust models that can maintain high accuracy even with noisy labels could lead to better performance in practical applications.
Technical Explanation
The paper first reviews related work on human pose estimation and the impact of dataset quality. It then introduces the PoseBench dataset, which was created by introducing controlled amounts of label noise into existing human pose datasets.
The researchers evaluated several state-of-the-art 2D and 3D pose estimation models on the PoseBench dataset, including HRNet, SimplePose, and SPIN. They found that the models' performance dropped significantly as the level of label noise increased, with error rates more than doubling in some cases.
The paper also presents an analysis of how different types of label noise (e.g., random vs. structured) impact the models. It finds that structured noise, where the errors are correlated across keypoints, tends to be more detrimental than random noise.
Critical Analysis
The paper provides a valuable contribution by highlighting the sensitivity of current pose estimation models to label quality in training data. This is an important practical issue, as real-world datasets often contain some degree of annotation errors or inconsistencies.
However, the paper does not propose any specific solutions to address this problem. It would be helpful to see the authors explore techniques for making pose estimation models more robust to label noise, such as specialized training procedures or model architectures.
Additionally, the paper focuses solely on evaluating model performance on the PoseBench dataset. It would be interesting to see how the models perform on other real-world datasets with natural label noise, to better understand the practical implications of the findings.
Conclusion
This paper demonstrates that state-of-the-art human pose estimation models are significantly affected by label noise in the training data. The researchers introduced the PoseBench dataset to systematically evaluate model robustness, and found that error rates can more than double as the level of noise increases.
These findings highlight the importance of data quality in building reliable pose estimation systems. Developing more robust models that can maintain high accuracy even with noisy labels could lead to improved performance in real-world applications. Future work could explore techniques to address this challenge and further test the models' behavior on diverse datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Influence of Faulty Labels in Data Sets on Human Pose Estimation
Arnold Schwarz, Levente Hernadi, Felix Bie{ss}mann, Kristian Hildebrand
In this study we provide empirical evidence demonstrating that the quality of training data impacts model performance in Human Pose Estimation (HPE). Inaccurate labels in widely used data sets, ranging from minor errors to severe mislabeling, can negatively influence learning and distort performance metrics. We perform an in-depth analysis of popular HPE data sets to show the extent and nature of label inaccuracies. Our findings suggest that accounting for the impact of faulty labels will facilitate the development of more robust and accurate HPE models for a variety of real-world applications. We show improved performance with cleansed data.
Read more9/10/2024
0
PoseBench: Benchmarking the Robustness of Pose Estimation Models under Corruptions
Sihan Ma, Jing Zhang, Qiong Cao, Dacheng Tao
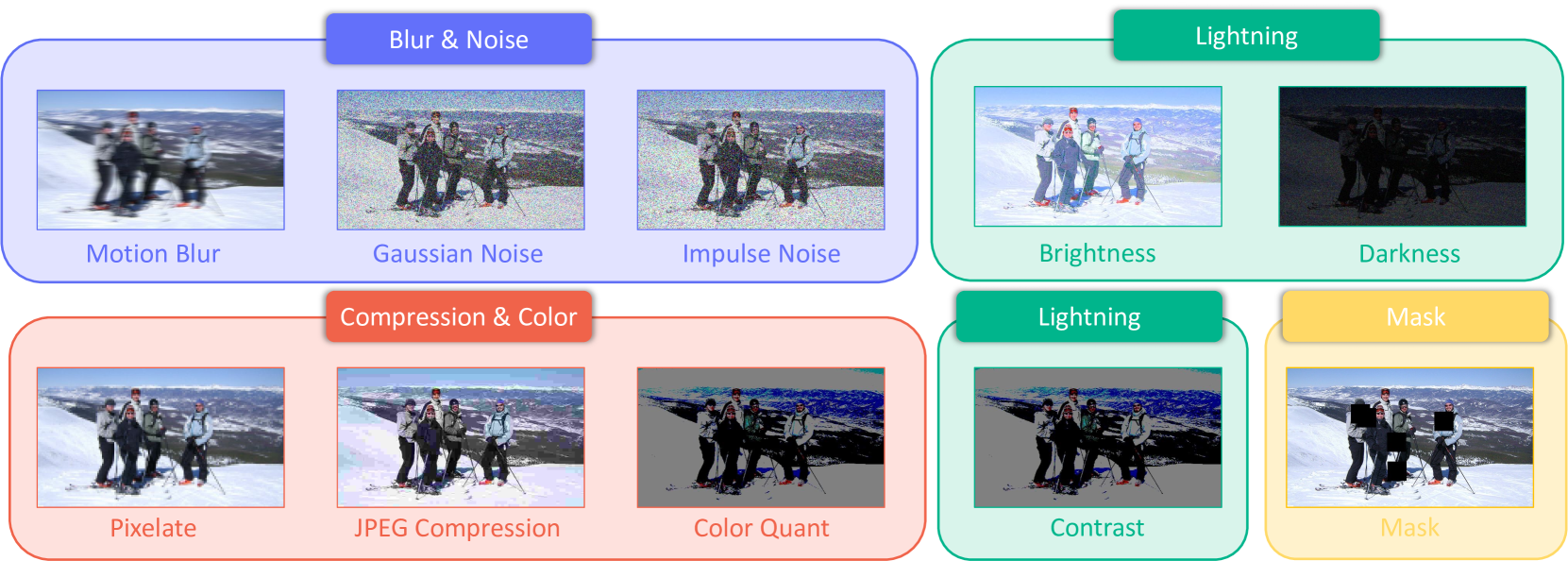
Pose estimation aims to accurately identify anatomical keypoints in humans and animals using monocular images, which is crucial for various applications such as human-machine interaction, embodied AI, and autonomous driving. While current models show promising results, they are typically trained and tested on clean data, potentially overlooking the corruption during real-world deployment and thus posing safety risks in practical scenarios. To address this issue, we introduce PoseBench, a comprehensive benchmark designed to evaluate the robustness of pose estimation models against real-world corruption. We evaluated 60 representative models, including top-down, bottom-up, heatmap-based, regression-based, and classification-based methods, across three datasets for human and animal pose estimation. Our evaluation involves 10 types of corruption in four categories: 1) blur and noise, 2) compression and color loss, 3) severe lighting, and 4) masks. Our findings reveal that state-of-the-art models are vulnerable to common real-world corruptions and exhibit distinct behaviors when tackling human and animal pose estimation tasks. To improve model robustness, we delve into various design considerations, including input resolution, pre-training datasets, backbone capacity, post-processing, and data augmentations. We hope that our benchmark will serve as a foundation for advancing research in robust pose estimation. The benchmark and source code will be released at https://xymsh.github.io/PoseBench
Read more9/17/2024
🔍
0
Improving the Robustness of 3D Human Pose Estimation: A Benchmark and Learning from Noisy Input
Trung-Hieu Hoang, Mona Zehni, Huy Phan, Duc Minh Vo, Minh N. Do
Despite the promising performance of current 3D human pose estimation techniques, understanding and enhancing their generalization on challenging in-the-wild videos remain an open problem. In this work, we focus on the robustness of 2D-to-3D pose lifters. To this end, we develop two benchmark datasets, namely Human3.6M-C and HumanEva-I-C, to examine the robustness of video-based 3D pose lifters to a wide range of common video corruptions including temporary occlusion, motion blur, and pixel-level noise. We observe the poor generalization of state-of-the-art 3D pose lifters in the presence of corruption and establish two techniques to tackle this issue. First, we introduce Temporal Additive Gaussian Noise (TAGN) as a simple yet effective 2D input pose data augmentation. Additionally, to incorporate the confidence scores output by the 2D pose detectors, we design a confidence-aware convolution (CA-Conv) block. Extensively tested on corrupted videos, the proposed strategies consistently boost the robustness of 3D pose lifters and serve as new baselines for future research.
Read more4/17/2024
📊
0
On the power of data augmentation for head pose estimation
Michael Welter
Deep learning has been impressively successful in the last decade in predicting human head poses from monocular images. For in-the-wild inputs, the research community has predominantly relied on a single training set of semi-synthetic nature. This paper suggest the combination of different flavors of synthetic data in order to achieve better generalization to natural images. Moreover, additional expansion of the data volume using traditional out-of-plane rotation synthesis is considered. Together with a novel combination of losses and a network architecture with a standard feature-extractor, a competitive model is obtained, both in accuracy and efficiency, which allows full 6 DoF pose estimation in practical real-time applications.
Read more7/12/2024