Improving the Robustness of 3D Human Pose Estimation: A Benchmark and Learning from Noisy Input
2312.06797
0
0
🔍
Abstract
Despite the promising performance of current 3D human pose estimation techniques, understanding and enhancing their generalization on challenging in-the-wild videos remain an open problem. In this work, we focus on the robustness of 2D-to-3D pose lifters. To this end, we develop two benchmark datasets, namely Human3.6M-C and HumanEva-I-C, to examine the robustness of video-based 3D pose lifters to a wide range of common video corruptions including temporary occlusion, motion blur, and pixel-level noise. We observe the poor generalization of state-of-the-art 3D pose lifters in the presence of corruption and establish two techniques to tackle this issue. First, we introduce Temporal Additive Gaussian Noise (TAGN) as a simple yet effective 2D input pose data augmentation. Additionally, to incorporate the confidence scores output by the 2D pose detectors, we design a confidence-aware convolution (CA-Conv) block. Extensively tested on corrupted videos, the proposed strategies consistently boost the robustness of 3D pose lifters and serve as new baselines for future research.
Create account to get full access
Overview
- This paper focuses on improving the robustness of 3D human pose estimation techniques in challenging real-world videos.
- The authors develop two benchmark datasets, Human3.6M-C and HumanEva-I-C, to evaluate the performance of 3D pose lifters under various video corruptions like occlusion, motion blur, and noise.
- They propose two techniques, Temporal Additive Gaussian Noise (TAGN) and Confidence-Aware Convolution (CA-Conv), to improve the robustness of 3D pose lifters on these corrupted videos.
Plain English Explanation
Estimating the 3D pose of a person in a video is a challenging computer vision task with many real-world applications, such as human-computer interaction and robotics. While current 3D pose estimation techniques can perform well in controlled environments, they often struggle when applied to messy, real-world videos with factors like occlusions, motion blur, and noise.
To address this issue, the researchers in this paper developed two new benchmark datasets, Human3.6M-C and HumanEva-I-C, which contain videos with various types of corruptions. They used these datasets to evaluate the performance of state-of-the-art 3D pose lifters, which take 2D pose estimates as input and output the corresponding 3D poses.
The researchers found that these 3D pose lifters did not generalize well to the corrupted videos, often producing inaccurate results. To improve their robustness, the researchers introduced two new techniques:
-
Temporal Additive Gaussian Noise (TAGN): This is a data augmentation method that adds realistic noise to the 2D pose input, helping the 3D pose lifter learn to be more resilient to real-world corruptions.
-
Confidence-Aware Convolution (CA-Conv): This is a specialized convolutional layer that takes into account the confidence scores output by the 2D pose detector, allowing the 3D pose lifter to focus on the most reliable 2D pose information.
By incorporating these techniques, the researchers were able to significantly boost the performance of 3D pose lifters on the corrupted benchmark datasets, establishing new baselines for future research in this area.
Technical Explanation
The paper addresses the challenge of 3D human pose estimation in the presence of common video corruptions, such as temporary occlusion, motion blur, and pixel-level noise. The authors develop two benchmark datasets, Human3.6M-C and HumanEva-I-C, to systematically evaluate the robustness of video-based 3D pose lifters under these conditions.
The authors first analyze the performance of state-of-the-art 3D pose lifters on the corrupted benchmark videos and observe a significant drop in accuracy compared to clean data. To address this issue, they propose two techniques:
-
Temporal Additive Gaussian Noise (TAGN): This data augmentation method injects additive Gaussian noise to the 2D pose input of the 3D pose lifter in a temporally coherent manner. This helps the model learn to be more robust to various types of noise and corruption present in real-world videos.
-
Confidence-Aware Convolution (CA-Conv): This is a specialized convolutional layer that incorporates the confidence scores output by the 2D pose detector. By weighting the convolution operations based on these confidence scores, the 3D pose lifter can focus more on the reliable 2D pose information and disregard noisy or occluded inputs.
The authors extensively evaluate the proposed techniques on the corrupted benchmark datasets and show that they consistently improve the robustness of 3D pose lifters, outperforming previous state-of-the-art methods. The TAGN and CA-Conv strategies serve as new baselines for future research on building reliable 3D human pose estimation systems for in-the-wild videos.
Critical Analysis
The paper makes a valuable contribution to the field of 3D human pose estimation by addressing the important issue of model robustness to real-world video corruptions. The development of the Human3.6M-C and HumanEva-I-C benchmark datasets provides a meaningful way to evaluate the performance of 3D pose lifters under challenging conditions, going beyond the standard evaluation on clean data.
One limitation of the paper is that the proposed techniques, while effective, may not generalize to all types of video corruptions or unseen types of noise. The authors acknowledge this and suggest that further research is needed to develop more comprehensive solutions to handle a broader range of real-world challenges.
Additionally, the paper focuses solely on the robustness of 3D pose lifters, and does not address the performance of the underlying 2D pose detectors, which are a crucial component of the overall 3D pose estimation pipeline. Investigating the robustness of 2D pose detectors and their impact on the 3D pose lifter's performance could be a fruitful area for future research.
Overall, this paper provides a solid foundation for improving the reliability of 3D human pose estimation in challenging real-world scenarios, and the proposed TAGN and CA-Conv techniques can serve as useful starting points for further advancements in this direction.
Conclusion
This paper tackles the important challenge of improving the robustness of 3D human pose estimation techniques in the face of common video corruptions, such as occlusion, motion blur, and noise. By developing two benchmark datasets and proposing two novel techniques (TAGN and CA-Conv), the authors have made significant progress in addressing this problem.
The findings of this research have important implications for real-world applications of 3D pose estimation, such as human-computer interaction, robotics, and mixed reality, where systems need to function reliably in diverse and unpredictable environments. The techniques introduced in this paper provide a strong foundation for building more robust and practical 3D pose estimation solutions for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
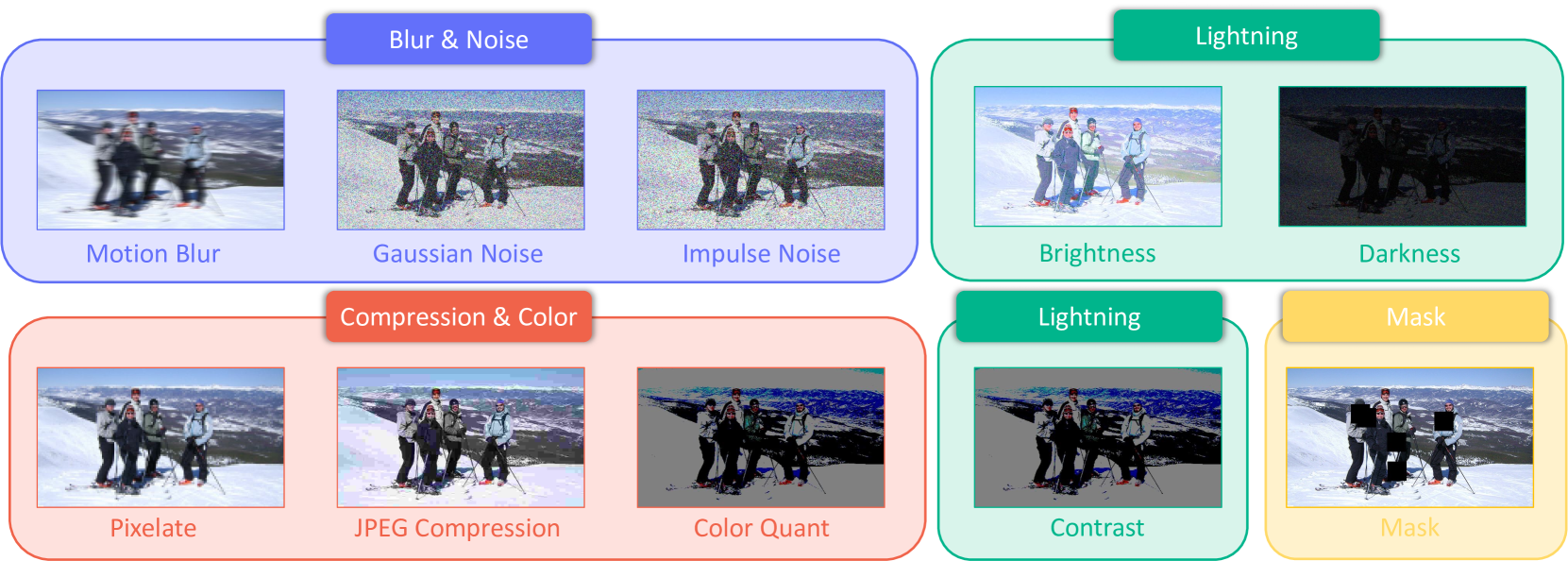
PoseBench: Benchmarking the Robustness of Pose Estimation Models under Corruptions
Sihan Ma, Jing Zhang, Qiong Cao, Dacheng Tao
0
0
Pose estimation aims to accurately identify anatomical keypoints in humans and animals using monocular images, which is crucial for various applications such as human-machine interaction, embodied AI, and autonomous driving. While current models show promising results, they are typically trained and tested on clean data, potentially overlooking the corruption during real-world deployment and thus posing safety risks in practical scenarios. To address this issue, we introduce PoseBench, a comprehensive benchmark designed to evaluate the robustness of pose estimation models against real-world corruption. We evaluated 60 representative models, including top-down, bottom-up, heatmap-based, regression-based, and classification-based methods, across three datasets for human and animal pose estimation. Our evaluation involves 10 types of corruption in four categories: 1) blur and noise, 2) compression and color loss, 3) severe lighting, and 4) masks. Our findings reveal that state-of-the-art models are vulnerable to common real-world corruptions and exhibit distinct behaviors when tackling human and animal pose estimation tasks. To improve model robustness, we delve into various design considerations, including input resolution, pre-training datasets, backbone capacity, post-processing, and data augmentations. We hope that our benchmark will serve as a foundation for advancing research in robust pose estimation. The benchmark and source code will be released at https://xymsh.github.io/PoseBench
6/21/2024
🏋️
Probablistic Restoration with Adaptive Noise Sampling for 3D Human Pose Estimation
Xianzhou Zeng, Hao Qin, Ming Kong, Luyuan Chen, Qiang Zhu
0
0
The accuracy and robustness of 3D human pose estimation (HPE) are limited by 2D pose detection errors and 2D to 3D ill-posed challenges, which have drawn great attention to Multi-Hypothesis HPE research. Most existing MH-HPE methods are based on generative models, which are computationally expensive and difficult to train. In this study, we propose a Probabilistic Restoration 3D Human Pose Estimation framework (PRPose) that can be integrated with any lightweight single-hypothesis model. Specifically, PRPose employs a weakly supervised approach to fit the hidden probability distribution of the 2D-to-3D lifting process in the Single-Hypothesis HPE model and then reverse-map the distribution to the 2D pose input through an adaptive noise sampling strategy to generate reasonable multi-hypothesis samples effectively. Extensive experiments on 3D HPE benchmarks (Human3.6M and MPI-INF-3DHP) highlight the effectiveness and efficiency of PRPose. Code is available at: https://github.com/xzhouzeng/PRPose.
5/6/2024
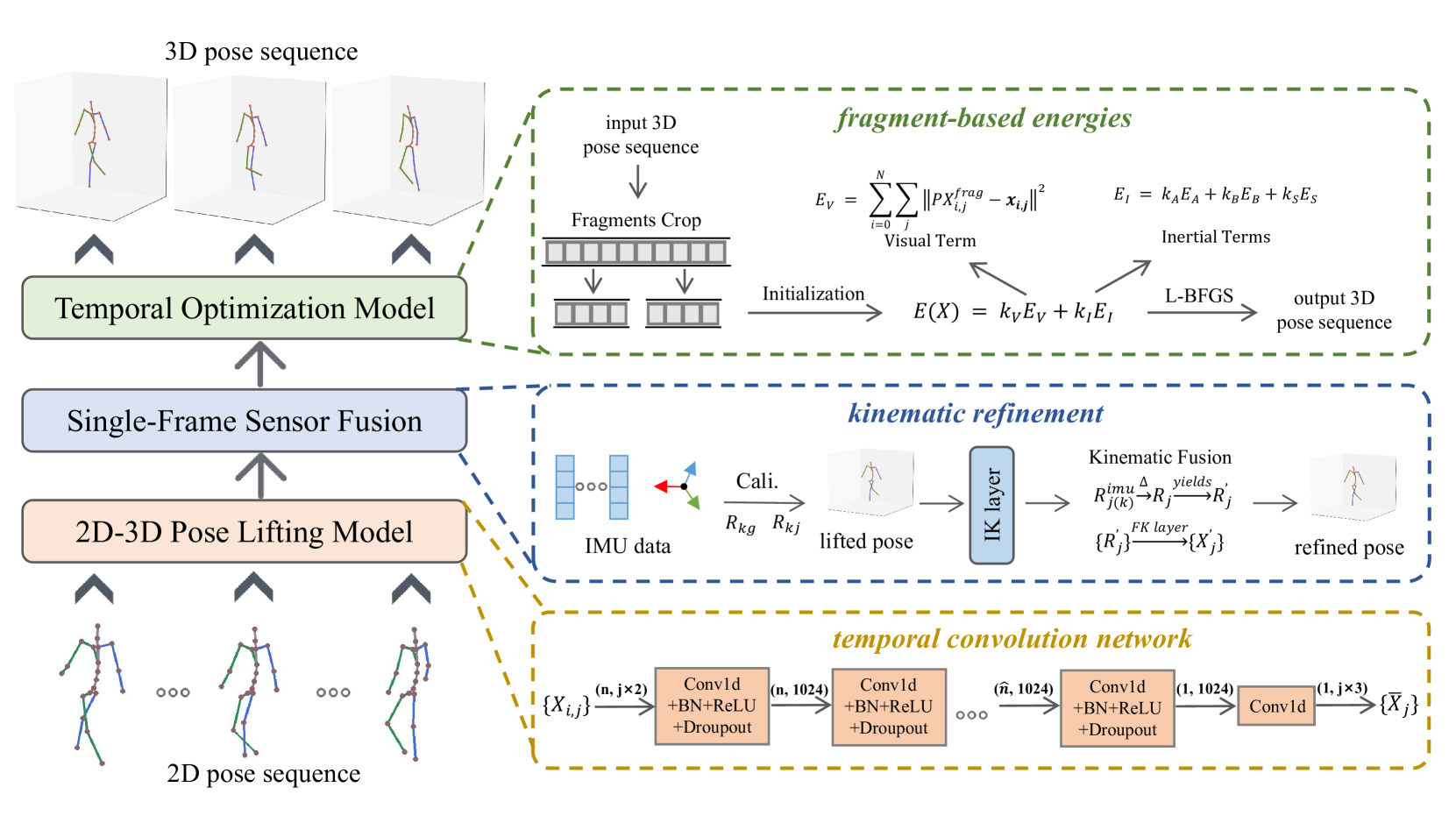
Hybrid 3D Human Pose Estimation with Monocular Video and Sparse IMUs
Yiming Bao, Xu Zhao, Dahong Qian
0
0
Temporal 3D human pose estimation from monocular videos is a challenging task in human-centered computer vision due to the depth ambiguity of 2D-to-3D lifting. To improve accuracy and address occlusion issues, inertial sensor has been introduced to provide complementary source of information. However, it remains challenging to integrate heterogeneous sensor data for producing physically rational 3D human poses. In this paper, we propose a novel framework, Real-time Optimization and Fusion (RTOF), to address this issue. We first incorporate sparse inertial orientations into a parametric human skeleton to refine 3D poses in kinematics. The poses are then optimized by energy functions built on both visual and inertial observations to reduce the temporal jitters. Our framework outputs smooth and biomechanically plausible human motion. Comprehensive experiments with ablation studies demonstrate its rationality and efficiency. On Total Capture dataset, the pose estimation error is significantly decreased compared to the baseline method.
4/30/2024

Gait Recognition from Highly Compressed Videos
Andrei Niculae, Andy Catruna, Adrian Cosma, Daniel Rosner, Emilian Radoi
0
0
Surveillance footage represents a valuable resource and opportunities for conducting gait analysis. However, the typical low quality and high noise levels in such footage can severely impact the accuracy of pose estimation algorithms, which are foundational for reliable gait analysis. Existing literature suggests a direct correlation between the efficacy of pose estimation and the subsequent gait analysis results. A common mitigation strategy involves fine-tuning pose estimation models on noisy data to improve robustness. However, this approach may degrade the downstream model's performance on the original high-quality data, leading to a trade-off that is undesirable in practice. We propose a processing pipeline that incorporates a task-targeted artifact correction model specifically designed to pre-process and enhance surveillance footage before pose estimation. Our artifact correction model is optimized to work alongside a state-of-the-art pose estimation network, HRNet, without requiring repeated fine-tuning of the pose estimation model. Furthermore, we propose a simple and robust method for obtaining low quality videos that are annotated with poses in an automatic manner with the purpose of training the artifact correction model. We systematically evaluate the performance of our artifact correction model against a range of noisy surveillance data and demonstrate that our approach not only achieves improved pose estimation on low-quality surveillance footage, but also preserves the integrity of the pose estimation on high resolution footage. Our experiments show a clear enhancement in gait analysis performance, supporting the viability of the proposed method as a superior alternative to direct fine-tuning strategies. Our contributions pave the way for more reliable gait analysis using surveillance data in real-world applications, regardless of data quality.
4/19/2024