InfoNorm: Mutual Information Shaping of Normals for Sparse-View Reconstruction

0

Sign in to get full access
Overview
- The paper introduces InfoNorm, a method for improving sparse-view 3D reconstruction from multi-view images by shaping the mutual information between surface normals and the input images.
- The key idea is to incorporate surface normal information into the reconstruction process to better constrain the solution and produce more accurate results, especially in sparsely-viewed regions.
- The approach involves a novel neural network architecture and training strategy that explicitly models and leverages the relationship between the input images and the desired surface normals.
Plain English Explanation
The paper describes a technique called InfoNorm that can help improve the quality of 3D reconstructions from a small number of camera views. In many real-world scenarios, we may only have a limited number of images available to reconstruct a 3D scene, which can lead to poor results, especially in regions that are not well-covered by the available views.
The key insight behind InfoNorm is that by incorporating information about the surface normals (the directions the surfaces are facing) into the reconstruction process, we can better constrain the solution and produce more accurate 3D models, even in sparsely-viewed areas. The authors develop a specialized neural network architecture and training procedure that explicitly models the relationship between the input images and the desired surface normals, allowing the network to learn how to leverage this complementary information for improved 3D reconstruction.
Compared to existing methods that rely solely on the input images, InfoNorm is able to generate more detailed and faithful 3D reconstructions, especially in challenging scenarios with limited camera views. This could have important applications in areas like NcSDF, Normal-Guided Neural Implicit Functions, and Neural Radiance Field Depth and Normal Completion, where accurate 3D reconstruction from sparse data is crucial.
Technical Explanation
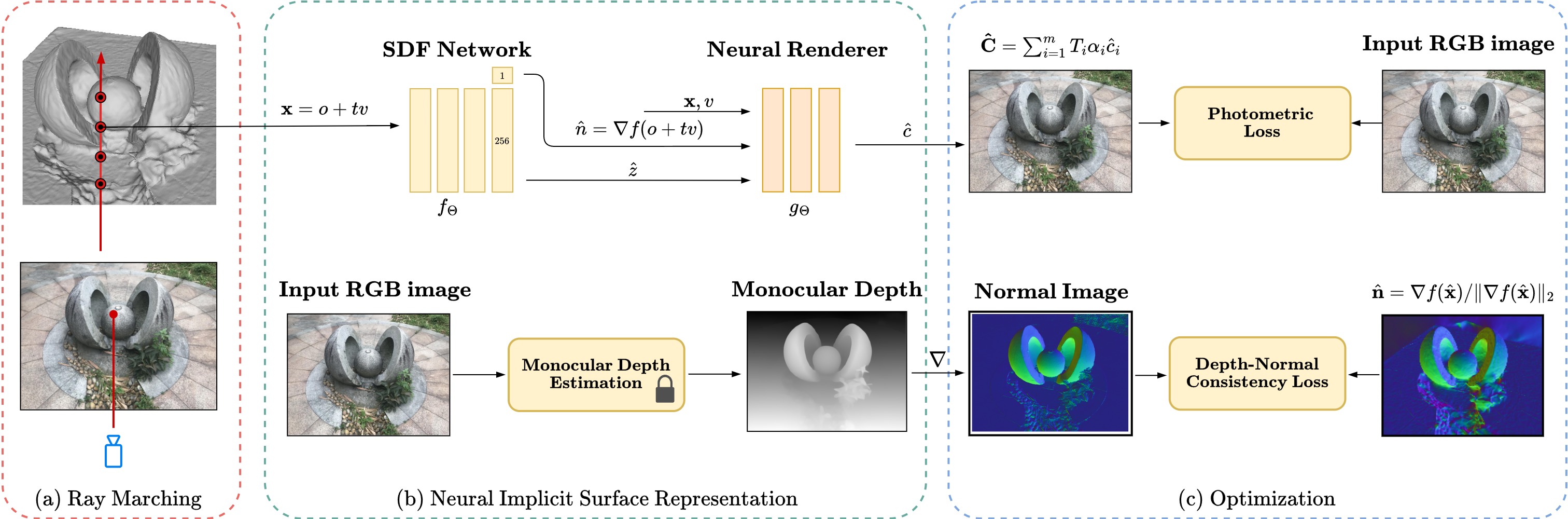
The core of the InfoNorm approach is a neural network architecture that takes in a set of multi-view images as input and produces a 3D reconstruction of the scene, along with estimates of the surface normals at each point. By explicitly modeling the relationship between the input images and the desired surface normals, the network can leverage this complementary information to generate more accurate 3D reconstructions, especially in sparsely-viewed regions.
The network consists of an image encoder, a normal encoder, and a shared decoder that produces the final 3D reconstruction. The image encoder processes the input views to extract relevant visual features, while the normal encoder takes in ground truth surface normals (computed from a dense 3D reference model) and learns to map them to a compact latent representation.
During training, the network is optimized to not only reconstruct the 3D scene accurately, but also to predict surface normals that are consistent with the input images. This is achieved by introducing a mutual information loss that encourages the network to discover the underlying relationship between the images and normals, allowing it to better leverage this connection for improved reconstruction quality.
The authors evaluate InfoNorm on several benchmark datasets for sparse-view 3D reconstruction, including the DebuggingSDFs and SG-NeRF datasets. The results demonstrate that InfoNorm outperforms state-of-the-art methods, producing more detailed and faithful 3D reconstructions, especially in challenging regions with limited camera coverage.
Critical Analysis
The authors present a well-designed and thorough evaluation of the InfoNorm approach, demonstrating its effectiveness across multiple benchmark datasets. However, some potential limitations and areas for further research are worth considering:
- The reliance on ground truth surface normals during training may limit the practical applicability of the method, as obtaining accurate normals can be challenging in many real-world scenarios. Exploring ways to learn the normals from the input images alone could make the approach more broadly applicable.
- The authors do not provide a detailed analysis of the computational costs and runtime performance of InfoNorm compared to other methods. This information would be useful for understanding the practical trade-offs and deployment considerations.
- While the paper focuses on sparse-view reconstruction, it would be interesting to see how InfoNorm performs in other 3D reconstruction tasks, such as normal-guided neural implicit functions or neural radiance field depth and normal completion, where surface normal information could also play a valuable role.
Overall, the InfoNorm approach represents an innovative and promising step towards improving 3D reconstruction from limited data, with potential applications in a variety of computer vision and graphics domains.
Conclusion
The InfoNorm paper introduces a novel technique for improving sparse-view 3D reconstruction by explicitly modeling the relationship between the input images and the desired surface normals. By incorporating this complementary information into the reconstruction process, the authors demonstrate that they can generate more detailed and accurate 3D models, especially in challenging regions with limited camera coverage.
The key technical contributions include a specialized neural network architecture and training strategy that leverages mutual information between the images and normals. The extensive evaluation on benchmark datasets shows that InfoNorm outperforms state-of-the-art methods, suggesting that this approach could have significant impact in areas like indoor scene reconstruction, neural implicit functions, and neural radiance field completion.
While the reliance on ground truth normals during training is a potential limitation, the overall ideas and insights presented in this work represent an important step forward in addressing the challenges of sparse-view 3D reconstruction, with promising implications for a wide range of computer vision and graphics applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
InfoNorm: Mutual Information Shaping of Normals for Sparse-View Reconstruction
Xulong Wang, Siyan Dong, Youyi Zheng, Yanchao Yang
3D surface reconstruction from multi-view images is essential for scene understanding and interaction. However, complex indoor scenes pose challenges such as ambiguity due to limited observations. Recent implicit surface representations, such as Neural Radiance Fields (NeRFs) and signed distance functions (SDFs), employ various geometric priors to resolve the lack of observed information. Nevertheless, their performance heavily depends on the quality of the pre-trained geometry estimation models. To ease such dependence, we propose regularizing the geometric modeling by explicitly encouraging the mutual information among surface normals of highly correlated scene points. In this way, the geometry learning process is modulated by the second-order correlations from noisy (first-order) geometric priors, thus eliminating the bias due to poor generalization. Additionally, we introduce a simple yet effective scheme that utilizes semantic and geometric features to identify correlated points, enhancing their mutual information accordingly. The proposed technique can serve as a plugin for SDF-based neural surface representations. Our experiments demonstrate the effectiveness of the proposed in improving the surface reconstruction quality of major states of the arts. Our code is available at: url{https://github.com/Muliphein/InfoNorm}.
Read more7/18/2024
🧠
0
NC-SDF: Enhancing Indoor Scene Reconstruction Using Neural SDFs with View-Dependent Normal Compensation
Ziyi Chen, Xiaolong Wu, Yu Zhang
State-of-the-art neural implicit surface representations have achieved impressive results in indoor scene reconstruction by incorporating monocular geometric priors as additional supervision. However, we have observed that multi-view inconsistency between such priors poses a challenge for high-quality reconstructions. In response, we present NC-SDF, a neural signed distance field (SDF) 3D reconstruction framework with view-dependent normal compensation (NC). Specifically, we integrate view-dependent biases in monocular normal priors into the neural implicit representation of the scene. By adaptively learning and correcting the biases, our NC-SDF effectively mitigates the adverse impact of inconsistent supervision, enhancing both the global consistency and local details in the reconstructions. To further refine the details, we introduce an informative pixel sampling strategy to pay more attention to intricate geometry with higher information content. Additionally, we design a hybrid geometry modeling approach to improve the neural implicit representation. Experiments on synthetic and real-world datasets demonstrate that NC-SDF outperforms existing approaches in terms of reconstruction quality.
Read more5/2/2024
0
Normal-guided Detail-Preserving Neural Implicit Functions for High-Fidelity 3D Surface Reconstruction
Aarya Patel, Hamid Laga, Ojaswa Sharma
Neural implicit representations have emerged as a powerful paradigm for 3D reconstruction. However, despite their success, existing methods fail to capture fine geometric details and thin structures, especially in scenarios where only sparse RGB views of the objects of interest are available. We hypothesize that current methods for learning neural implicit representations from RGB or RGBD images produce 3D surfaces with missing parts and details because they only rely on 0-order differential properties, i.e. the 3D surface points and their projections, as supervisory signals. Such properties, however, do not capture the local 3D geometry around the points and also ignore the interactions between points. This paper demonstrates that training neural representations with first-order differential properties, i.e. surface normals, leads to highly accurate 3D surface reconstruction even in situations where only as few as two RGB (front and back) images are available. Given multiview RGB images of an object of interest, we first compute the approximate surface normals in the image space using the gradient of the depth maps produced using an off-the-shelf monocular depth estimator such as Depth Anything model. An implicit surface regressor is then trained using a loss function that enforces the first-order differential properties of the regressed surface to match those estimated from Depth Anything. Our extensive experiments on a wide range of real and synthetic datasets show that the proposed method achieves an unprecedented level of reconstruction accuracy even when using as few as two RGB views. The detailed ablation study also demonstrates that normal-based supervision plays a key role in this significant improvement in performance, enabling the 3D reconstruction of intricate geometric details and thin structures that were previously challenging to capture.
Read more6/10/2024

0
Enhancing Neural Radiance Fields with Depth and Normal Completion Priors from Sparse Views
Jiawei Guo, HungChyun Chou, Ning Ding
Neural Radiance Fields (NeRF) are an advanced technology that creates highly realistic images by learning about scenes through a neural network model. However, NeRF often encounters issues when there are not enough images to work with, leading to problems in accurately rendering views. The main issue is that NeRF lacks sufficient structural details to guide the rendering process accurately. To address this, we proposed a Depth and Normal Dense Completion Priors for NeRF (CP_NeRF) framework. This framework enhances view rendering by adding depth and normal dense completion priors to the NeRF optimization process. Before optimizing NeRF, we obtain sparse depth maps using the Structure from Motion (SfM) technique used to get camera poses. Based on the sparse depth maps and a normal estimator, we generate sparse normal maps for training a normal completion prior with precise standard deviations. During optimization, we apply depth and normal completion priors to transform sparse data into dense depth and normal maps with their standard deviations. We use these dense maps to guide ray sampling, assist distance sampling and construct a normal loss function for better training accuracy. To improve the rendering of NeRF's normal outputs, we incorporate an optical centre position embedder that helps synthesize more accurate normals through volume rendering. Additionally, we employ a normal patch matching technique to choose accurate rendered normal maps, ensuring more precise supervision for the model. Our method is superior to leading techniques in rendering detailed indoor scenes, even with limited input views.
Read more7/9/2024