An Information-Theoretic Framework for Out-of-Distribution Generalization
2403.19895
0
0
🖼️
Abstract
We study the Out-of-Distribution (OOD) generalization in machine learning and propose a general framework that provides information-theoretic generalization bounds. Our framework interpolates freely between Integral Probability Metric (IPM) and $f$-divergence, which naturally recovers some known results (including Wasserstein- and KL-bounds), as well as yields new generalization bounds. Moreover, we show that our framework admits an optimal transport interpretation. When evaluated in two concrete examples, the proposed bounds either strictly improve upon existing bounds in some cases or recover the best among existing OOD generalization bounds.
Create account to get full access
Introduction
The paper discusses improving the generalization ability of supervised learning algorithms, which is a core objective. It explores various mathematical tools that have been developed to bound the generalization gap, such as VC dimension, Rademacher complexity, covering numbers, algorithmic stability, and PAC Bayes. Recently, information-theoretic tools have been used to bound the generalization gap by treating the learning algorithm as a communication channel that maps input samples to output hypotheses.
The paper introduces previous work that bounded the generalization gap using mutual information between the samples and hypotheses. However, these bounds become vacuous when the mutual information is infinite. Two approaches are discussed to address this issue: one replaces the whole sample with individual samples, and the other introduces ghost samples and uses conditional mutual information.
The paper then focuses on the Out-of-Distribution (OOD) generalization scenario, where the test data distribution differs from the training data distribution due to selection biases. Previous work captured OOD performance using the KL divergence between the training and test distributions, adding it as a penalty term to the generalization bounds.
The paper proposes a theoretical framework that allows interpolating freely between Integral Probability Metric (IPM) and f-divergence, encompassing existing Wasserstein-distance-based and KL-divergence-based bounds as special cases. The framework also derives new generalization bounds that can outperform existing OOD generalization bounds in some cases and recover the tightest existing bounds in other cases.
Finally, the paper mentions that the generalization bounds also apply to the in-distribution case and discusses the relationship between the proposed framework and previous work on information-theoretic generalization bounds in transfer learning, domain adaptation, and rate distortion theory.
Problem Formulation
This section introduces notation and provides background on important concepts used in the paper.
Notation:
- ℝ and ℝ+ denote the sets of real numbers and non-negative real numbers, respectively.
- 𝒫(𝒳) is the set of probability distributions over set 𝒳.
- ℳ(𝒳) is the set of measurable functions over 𝒳.
- P ⟂ Q means P is singular to Q.
- P ≪ Q means P is absolutely continuous with respect to Q.
- dP/dQ denotes the Radon-Nikodym derivative.
The f-divergence between distributions P and Q is defined, which generalizes common divergences like KL divergence. The generalized cumulant generating function is introduced as the Legendre-Fenchel dual of the f-divergence.
The Γ-integral probability metric (IPM) between P and Q is defined as the supremum of the difference of expectations under P and Q over a set Γ of measurable functions. Examples like Wasserstein distance are special cases of IPMs.
The generalization gap quantities of interest are defined for an algorithm outputting a hypothesis W based on training data Z^n from distribution ν in an out-of-distribution (OOD) generalization setting where the test distribution is μ. Two notions are presented: the population-empirical (PE) generalization gap and the population-population (PP) generalization gap.
Main Results
This section presents several technical results related to generalization bounds for machine learning models. The key points are:
-
Proposition 1 provides an inequality that bounds the generalization gap using the Γ-IPM divergence, f-divergence, and the generalized cumulant generating function (CGF).
-
Theorem 1 gives the main result - a general theorem that provides an upper bound on the generalization error. This bound involves finding an optimal auxiliary distribution η that minimizes a combination of the Γ divergence between η and the training data distribution, and the f-divergence between η and the prior distribution.
-
Corollary 1 simplifies the bound in Theorem 1 under certain symmetry conditions on the function class Γ.
-
The final part interprets Theorem 1's bound from an optimal transport perspective, viewing the generalization error as the cost of reshaping one distribution (the prior) into another (the training data distribution) through intermediate auxiliary distributions.
Overall, this section establishes novel generalization bounds utilizing IPMs, f-divergences and the CGF, providing theoretical insights into the factors influencing a model's ability to generalize from training to test data.
V Special Cases
The section discusses several generalization bounds for both population-empirical (PE) and population-population (PP) settings. For the PE setting, it derives bounds using different divergence measures like Wasserstein distance, total variation, KL divergence, chi-squared divergence, and general f-divergences for loss functions satisfying certain conditions. These bounds relate the generalization gap to quantities involving the divergences between the distributions of model parameters and data distributions.
For the PP setting, the section provides PP generalization bounds as counterparts of the PE bounds, with the divergences between the data distributions replacing those between parameter distributions and data distributions in the PE case.
Some key results include:
- Wasserstein distance and total variation bounds for Lipschitz/bounded loss functions (Corollaries 2, 3)
- KL divergence bounds for sub-Gaussian and sub-gamma loss functions (Corollaries 4, 5)
- Chi-squared divergence bound under a variance condition (Corollary 6)
- General f-divergence bounds for bounded loss satisfying certain convexity conditions, with a table relating divergences to coefficient terms (Corollary 7, Table I)
- PP generalization bounds for any f-divergence under conditions on the loss function (Corollary 8, Table II)
The section also discusses optimizing some bounds over the reference distribution and specializing to in-distribution generalization. Overall, it provides a comprehensive derivation of generalization bounds using information projections and f-divergences in both empirical and population settings.
Examples
The provided text discusses estimating the mean of Gaussian and Bernoulli random variables using the empirical risk minimization (ERM) algorithm. Key points:
For Gaussian variables:
- The training data follows N(m, σ^2) and test data N(m', (σ')^2)
- The ERM estimate w = (1/n)Σz_i minimizes the squared error loss
- The χ^2 and KL divergence bounds on the generalization gap are derived and compared
- For in-distribution (m'=m, σ'=σ), both bounds decay as O(1/√n) while the true gap decays as O(1/n)
- The KL bound is tighter for in-distribution but the χ^2 bound is tighter for out-of-distribution cases
For Bernoulli variables:
- Training data from Bern(p)^⊗n, test data Bern(p')
- Same squared error loss and ERM estimate used
- Various f-divergence bounds like squared Hellinger, Jensen-Shannon, Le Cam are derived
- These bounds are tighter than the KL bound for the plotted case of p=0.3, p'=0.1
- The total variation bound is the tightest among those considered
The text provides theoretical analysis comparing the tightness of different generalization bounds for simple statistical estimation problems.
Appendix A Proof of Section III
The provided text proves some key mathematical results related to f-divergences and generalized Bayesian learning. Here is a summary:
It first proves Proposition 11, which provides an upper bound on the generalized Bayesian risk gen(PW|Zn,ν,μ) in terms of f-divergences and IPMs. The proof uses the variational representation of f-divergences and the Fenchel-Young inequality.
It then shows in Proposition 2 that the upper bound in Proposition 11 is tight under certain conditions on the set Γ¯ and the distributions ηi.
Next, it provides an alternative proof of Proposition 11 using the concept of (f,Γ)-divergence, showing the relationship between the two results.
It proves Theorem 12 by invoking a lemma about generalized inverses of convex functions. This provides a more general upper bound on gen(PW|Zn,ν,μ) involving an infimum over parameters ti.
Finally, it proves Corollary 14 which upper bounds gen(PW|Zn,ν,μ) solely in terms of IPMs when certain conditions on the loss function ℓ and set Γ hold.
The proofs rely heavily on tools from convex analysis and make use of properties of f-divergences, variational representations, Fenchel duality, and integral probability metrics. Overall, these results characterize the generalized Bayesian risk in terms of divergences and IPMs under different function classes.
Appendix B Proofs in Section IV
The provided text proves several corollaries related to generalizing different f-divergences to the conditional setting. Here are the key points:
-
Corollary 15 bounds the generalized f-divergence in terms of Wasserstein distances between the conditional distributions and marginals.
-
Corollary 3 relates the generalized f-divergence to the total variation distance when the f-divergence is the variational representation of total variation.
-
Corollaries 4 and 19 bound the generalized f-divergence in terms of KL divergences between the conditional distributions and between the marginal distributions.
-
Corollary 21 specializes the bound for the squared error loss.
-
Corollary 7 lists conditions under which various classical f-divergences satisfy the required assumptions.
-
Corollary 25 provides a bound on the difference between the expectations of a function under two different marginal distributions in terms of the f-divergence between those marginals.
The proofs make use of various properties of f-divergences, like the variational representation, chain rules, and duality results. Technical tools like tower property of conditional expectation and Kantorovich-Rubinstein duality are employed in the derivations.
Appendix C Supplementary materials of Section V
The provided text gives details on estimating the means for Gaussian and Bernoulli distributions when calculating generalization bounds. Some key points:
For the Gaussian case:
- The training distribution is N(m, σ^2 I_d) and testing distribution is N(m', (σ')^2 I_d)
- Expressions are provided for the KL divergence and chi-squared divergence between the training and testing distributions
For the Bernoulli case:
- Expressions are given for the probabilities P(Z=1, W=k/n) and P(Z=0, W=k/n) under the training distribution
- The testing distribution Q is the product of Bern(p') and a binomial(n,p)
- An expression is provided for the true generalization gap
The text also discusses properties of the various divergence bounds like KL, chi-squared, Hellinger, Jensen-Shannon, and explains their relationships. Numerical results are shown comparing the bounds for certain parameter settings.
Overall, it provides technical details needed to calculate and understand the divergence bounds used for generalization analysis when the means differ between training and test distributions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Information-Theoretic Generalization Bounds for Deep Neural Networks
Haiyun He, Christina Lee Yu, Ziv Goldfeld
0
0
Deep neural networks (DNNs) exhibit an exceptional capacity for generalization in practical applications. This work aims to capture the effect and benefits of depth for supervised learning via information-theoretic generalization bounds. We first derive two hierarchical bounds on the generalization error in terms of the Kullback-Leibler (KL) divergence or the 1-Wasserstein distance between the train and test distributions of the network internal representations. The KL divergence bound shrinks as the layer index increases, while the Wasserstein bound implies the existence of a layer that serves as a generalization funnel, which attains a minimal 1-Wasserstein distance. Analytic expressions for both bounds are derived under the setting of binary Gaussian classification with linear DNNs. To quantify the contraction of the relevant information measures when moving deeper into the network, we analyze the strong data processing inequality (SDPI) coefficient between consecutive layers of three regularized DNN models: Dropout, DropConnect, and Gaussian noise injection. This enables refining our generalization bounds to capture the contraction as a function of the network architecture parameters. Specializing our results to DNNs with a finite parameter space and the Gibbs algorithm reveals that deeper yet narrower network architectures generalize better in those examples, although how broadly this statement applies remains a question.
4/5/2024
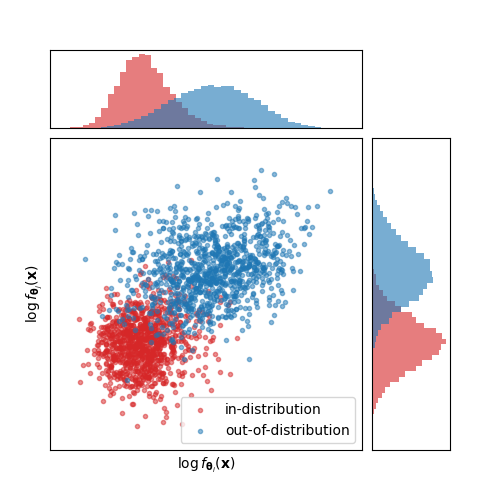
Approximations to the Fisher Information Metric of Deep Generative Models for Out-Of-Distribution Detection
Sam Dauncey, Chris Holmes, Christopher Williams, Fabian Falck
0
0
Likelihood-based deep generative models such as score-based diffusion models and variational autoencoders are state-of-the-art machine learning models approximating high-dimensional distributions of data such as images, text, or audio. One of many downstream tasks they can be naturally applied to is out-of-distribution (OOD) detection. However, seminal work by Nalisnick et al. which we reproduce showed that deep generative models consistently infer higher log-likelihoods for OOD data than data they were trained on, marking an open problem. In this work, we analyse using the gradient of a data point with respect to the parameters of the deep generative model for OOD detection, based on the simple intuition that OOD data should have larger gradient norms than training data. We formalise measuring the size of the gradient as approximating the Fisher information metric. We show that the Fisher information matrix (FIM) has large absolute diagonal values, motivating the use of chi-square distributed, layer-wise gradient norms as features. We combine these features to make a simple, model-agnostic and hyperparameter-free method for OOD detection which estimates the joint density of the layer-wise gradient norms for a given data point. We find that these layer-wise gradient norms are weakly correlated, rendering their combined usage informative, and prove that the layer-wise gradient norms satisfy the principle of (data representation) invariance. Our empirical results indicate that this method outperforms the Typicality test for most deep generative models and image dataset pairings.
5/28/2024
🧪
A View on Out-of-Distribution Identification from a Statistical Testing Theory Perspective
Alberto Caron, Chris Hicks, Vasilios Mavroudis
0
0
We study the problem of efficiently detecting Out-of-Distribution (OOD) samples at test time in supervised and unsupervised learning contexts. While ML models are typically trained under the assumption that training and test data stem from the same distribution, this is often not the case in realistic settings, thus reliably detecting distribution shifts is crucial at deployment. We re-formulate the OOD problem under the lenses of statistical testing and then discuss conditions that render the OOD problem identifiable in statistical terms. Building on this framework, we study convergence guarantees of an OOD test based on the Wasserstein distance, and provide a simple empirical evaluation.
5/13/2024

Coverage-Guaranteed Prediction Sets for Out-of-Distribution Data
Xin Zou, Weiwei Liu
0
0
Out-of-distribution (OOD) generalization has attracted increasing research attention in recent years, due to its promising experimental results in real-world applications. In this paper,we study the confidence set prediction problem in the OOD generalization setting. Split conformal prediction (SCP) is an efficient framework for handling the confidence set prediction problem. However, the validity of SCP requires the examples to be exchangeable, which is violated in the OOD setting. Empirically, we show that trivially applying SCP results in a failure to maintain the marginal coverage when the unseen target domain is different from the source domain. To address this issue, we develop a method for forming confident prediction sets in the OOD setting and theoretically prove the validity of our method. Finally, we conduct experiments on simulated data to empirically verify the correctness of our theory and the validity of our proposed method.
4/1/2024