Coverage-Guaranteed Prediction Sets for Out-of-Distribution Data
2403.19950
0
0

Abstract
Out-of-distribution (OOD) generalization has attracted increasing research attention in recent years, due to its promising experimental results in real-world applications. In this paper,we study the confidence set prediction problem in the OOD generalization setting. Split conformal prediction (SCP) is an efficient framework for handling the confidence set prediction problem. However, the validity of SCP requires the examples to be exchangeable, which is violated in the OOD setting. Empirically, we show that trivially applying SCP results in a failure to maintain the marginal coverage when the unseen target domain is different from the source domain. To address this issue, we develop a method for forming confident prediction sets in the OOD setting and theoretically prove the validity of our method. Finally, we conduct experiments on simulated data to empirically verify the correctness of our theory and the validity of our proposed method.
Create account to get full access
Introduction
This paper addresses the challenge of out-of-distribution (OOD) generalization in machine learning, where test data comes from a different distribution than the training data. A key problem is that existing methods for uncertainty quantification, like split conformal prediction (SCP), fail to maintain reliable coverage guarantees under OOD conditions due to violations of the exchangeability assumption.
To address this, the paper proposes a new set predictor based on the f-divergence between the test distribution and the convex hull of the training distributions. This provably maintains the desired marginal coverage guarantee, even in the OOD setting. The paper presents theoretical analysis and simulation experiments to validate the proposed method.
Related Works
The text discusses out-of-distribution (OOD) generalization, which aims to train a model on data from source domains so that it can generalize well to unseen target domains. Several algorithms have been developed to improve OOD generalization, including minimizing discrepancies between source domains, using meta-learning approaches, and adversarial training.
The text then introduces conformal prediction, a framework that provides valid confidence set predictors, even when the exchangeability of examples is violated to some extent. Previous works have considered various situations where exchangeability is violated, such as adversarial attacks on test examples, known density ratios between target and source domains, few-shot learning settings, and online learning.
The current work differs from these previous works by considering the OOD generalization setting where the f-divergence between the target domain and the convex hull of the source domains is constrained. This setting is most related to the work by Cauchois et al., which studied the worst-case coverage guarantee of an f-divergence ball centered at a single source domain.
Preliminaries
Here is a summary of the provided text:
The paper begins by introducing notations and concepts related to out-of-distribution (OOD) generalization. The input space is denoted as X and the label space as Y. The goal is to learn a predictor h that minimizes the worst-case population risk on unseen target domains T from the set T.
To achieve high-security, the paper proposes outputting a prediction set C(x) with a marginal coverage guarantee - that for any target domain T, the probability that the true label Y is contained in C(X) is at least 1-α, where α is the pre-defined significance level.
The paper then introduces split conformal prediction (SCP) as a method to construct such prediction sets. SCP assumes exchangeability of the training examples and uses the notion of nonconformity score s(x,y) to rank the examples. The prediction set C^n(x) is then defined based on the quantile of the empirical distribution of the nonconformity scores.
However, the paper shows that the validity guarantee of SCP does not hold in the OOD setting, as the exchangeability assumption is violated when there is distribution shift between the training and test data. The paper states that it will present a new set predictor in Section 5 that provides marginal coverage guarantees for the OOD setting.
SCP Fails in the OOD Setting
This section presents a toy example to show that for the out-of-distribution (OOD) confidence set prediction problem, split conformal prediction (SCP) is no longer valid, even under a slight distributional shift. The authors consider a regression problem with X in R^l and Y in R.
The source domain S is defined by a linear predictor L(x) = <w*, x> + b*, where w* is in R^l and b* is in R. The marginal distribution of X and the conditional distribution of Y given X are specified as Gaussian distributions with different parameters between the source domain S and the target domain T.
The authors sample training examples from S to train a linear predictor L-hat(x) = <w-hat, x> + b-hat, and define the nonconformity score as s(x, y) = |L-hat(x) - y|. They then sample examples from S to construct the prediction set C-hat_n(x) using Equation 2, and sample test examples from T.
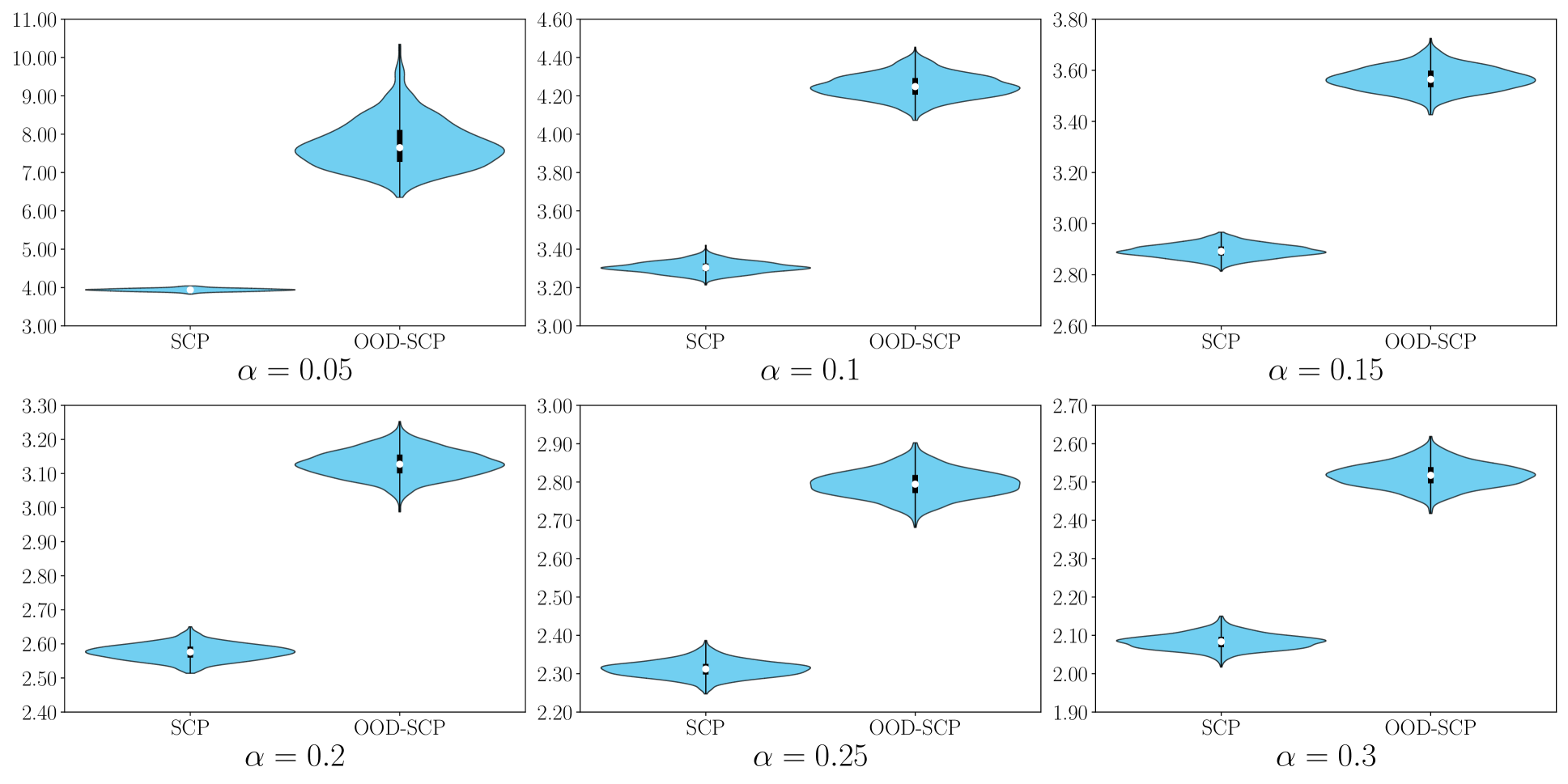
After running the experiment 1000 times with different random seeds, the results for the coverage and length of the prediction set are presented in box plots. The coverage is the ratio between the number of test examples such that y_i is in C-hat_n(x_i) and the size of the test set. The red lines stand for the desired marginal coverages.
The boxes in the left plot are below the red coverage lines, indicating that SCP fails to provide a prediction set with the desired coverage when there exists a distributional shift between the source and target domains.
Corrected SCP for OOD Data
The section considers correcting score-based conformal prediction (SCP) for out-of-distribution (OOD) data. First, it considers the case where the population distributions of the scores from the source domains are known. It defines a set of distributions T containing distributions that are close to the convex hull of the source domain distributions, as measured by an f-divergence. The paper then provides a way to construct a valid confidence set predictor that achieves the desired marginal coverage guarantee.
Next, the section considers the more practical case where only the empirical distributions of the scores are available. It provides an error bound on estimating the minimum of the source distribution CDFs, and then uses this to derive a marginal coverage guarantee for the prediction set when using the empirical distributions. The paper provides a way to correct the prediction set to achieve the desired 1-α marginal coverage.
The section includes examples calculating the functions needed for the guarantees for specific f-divergences like chi-squared, total variation, and KL divergence. For KL divergence, the functions cannot be obtained in closed form, but can be efficiently computed using binary search.
Overall, the section derives marginal coverage guarantees for SCP in the OOD setting, both when the population distributions are known and when only empirical distributions are available.
Experiments
This section uses simulated data to verify the theory and validity of the constructed confidence set predictor called OOD-SCP. Two cases are considered:
-
The validity of OOD-SCP is verified using the same settings as in Section 4. The results show that unlike standard SCP, OOD-SCP is empirically valid for all values of the coverage parameter α.
-
A multi-source OOD confidence set prediction task is constructed. The results show that standard SCP is invalid in this case, while OOD-SCP remains valid, validating the theoretical claims.
The paper explains that real-world datasets are not used because the value of the parameter ρ is unknown for existing OOD datasets. The key claim is that when the target domain satisfies certain theoretical conditions, the coverage of the OOD-SCP method is guaranteed. This issue of setting ρ does not overshadow the main contributions, similar to how challenges in other areas like adversarial robustness and distributionally robust optimization do not undermine the value of those theoretical frameworks.
Discussions
The authors extend the work of Cauchois et al. (2020) to the multi-domain case. They identify two key issues with the trivial method of treating the mixture of source domains as a single domain:
- The exact mixture weights of the source domains are unknown, so the set of points that the method provides a coverage guarantee for is unclear.
- The method may not be able to provide a coverage guarantee for data from one of the source domains, as shown using KL-divergence as an example.
The authors' generalization does not suffer from these issues, even when using a coverage guarantee of 0. This makes their extension necessary.
The authors' proof techniques are more complex than those in the original work. They need to handle multiple input functions and take the infimum over the simplex of mixture weights. This leads to a more complicated set construction and analysis with four different cases to consider.
The authors' main results, Theorem 8 and Corollary 9, are novel and quite different from the results in Cauchois et al. (2020). The proof techniques also differ, as the examples are not exchangeable in the out-of-distribution setting, unlike in the original work.
Conclusion
The text describes a study on the confidence set prediction (SCP) problem in the out-of-distribution (OOD) generalization setting. The authors first show empirically that SCP is not valid in the OOD generalization setting. They then develop a method for forming valid confident prediction sets in the OOD setting and provide a theoretical proof of the validity of their proposed method. Finally, the authors conduct experiments on simulated data to verify the correctness of their theory and the validity of their proposed method.
Acknowledgements
This research was funded by grants from the National Key R&D Program of China, the National Natural Science Foundation of China, and the Fundamental Research Funds for the Central Universities. The grants supported this work.
Appendix A Proofs
The provided text presents proofs for several lemmas and theorems related to conformal prediction sets with f-divergence constraints. The key points are:
-
Lemma 2 shows that the prediction set defined in Equation 2 satisfies the marginal coverage guarantee of at least 1-α.
-
Lemma 3 establishes that the worst-case quantile function 𝒬~(α;𝒫f,ρ) can be expressed in terms of the function gf,ρ.
-
Lemma 5 proves that the set 𝒫f,ρ is contained within the set 𝒫f,ρ.
-
Theorem 6 shows how to efficiently compute the worst-case quantile function 𝒬~(α;𝒫f,ρ) using the function gf,ρ.
-
Proposition 7 provides a finite-sample guarantee on the difference between the true and empirical worst-case quantile functions.
-
Theorem 8 gives a marginal coverage guarantee for the empirical prediction set 𝒞~(x).
-
Corollary 9 provides a way to correct the prediction set to achieve exact (1-α) marginal coverage.
-
Lemma 10 shows that the inverse of gf,ρ can be efficiently computed.
The proofs rely on properties of f-divergences, convexity arguments, and concentration inequalities.
Appendix B B Additional experimental results

This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
An Information-Theoretic Framework for Out-of-Distribution Generalization
Wenliang Liu, Guanding Yu, Lele Wang, Renjie Liao
0
0
We study the Out-of-Distribution (OOD) generalization in machine learning and propose a general framework that provides information-theoretic generalization bounds. Our framework interpolates freely between Integral Probability Metric (IPM) and $f$-divergence, which naturally recovers some known results (including Wasserstein- and KL-bounds), as well as yields new generalization bounds. Moreover, we show that our framework admits an optimal transport interpretation. When evaluated in two concrete examples, the proposed bounds either strictly improve upon existing bounds in some cases or recover the best among existing OOD generalization bounds.
4/1/2024

Gradient-Regularized Out-of-Distribution Detection
Sina Sharifi, Taha Entesari, Bardia Safaei, Vishal M. Patel, Mahyar Fazlyab
0
0
One of the challenges for neural networks in real-life applications is the overconfident errors these models make when the data is not from the original training distribution. Addressing this issue is known as Out-of-Distribution (OOD) detection. Many state-of-the-art OOD methods employ an auxiliary dataset as a surrogate for OOD data during training to achieve improved performance. However, these methods fail to fully exploit the local information embedded in the auxiliary dataset. In this work, we propose the idea of leveraging the information embedded in the gradient of the loss function during training to enable the network to not only learn a desired OOD score for each sample but also to exhibit similar behavior in a local neighborhood around each sample. We also develop a novel energy-based sampling method to allow the network to be exposed to more informative OOD samples during the training phase. This is especially important when the auxiliary dataset is large. We demonstrate the effectiveness of our method through extensive experiments on several OOD benchmarks, improving the existing state-of-the-art FPR95 by 4% on our ImageNet experiment. We further provide a theoretical analysis through the lens of certified robustness and Lipschitz analysis to showcase the theoretical foundation of our work. We will publicly release our code after the review process.
4/24/2024
Mixture Data for Training Cannot Ensure Out-of-distribution Generalization
Songming Zhang, Yuxiao Luo, Qizhou Wang, Haoang Chi, Xiaofeng Chen, Bo Han, Jinyan Li
0
0
Deep neural networks often face generalization problems to handle out-of-distribution (OOD) data, and there remains a notable theoretical gap between the contributing factors and their respective impacts. Literature evidence from in-distribution data has suggested that generalization error can shrink if the size of mixture data for training increases. However, when it comes to OOD samples, this conventional understanding does not hold anymore -- Increasing the size of training data does not always lead to a reduction in the test generalization error. In fact, diverse trends of the errors have been found across various shifting scenarios including those decreasing trends under a power-law pattern, initial declines followed by increases, or continuous stable patterns. Previous work has approached OOD data qualitatively, treating them merely as samples unseen during training, which are hard to explain the complicated non-monotonic trends. In this work, we quantitatively redefine OOD data as those situated outside the convex hull of mixed training data and establish novel generalization error bounds to comprehend the counterintuitive observations better. Our proof of the new risk bound agrees that the efficacy of well-trained models can be guaranteed for unseen data within the convex hull; More interestingly, but for OOD data beyond this coverage, the generalization cannot be ensured, which aligns with our observations. Furthermore, we attempted various OOD techniques to underscore that our results not only explain insightful observations in recent OOD generalization work, such as the significance of diverse data and the sensitivity to unseen shifts of existing algorithms, but it also inspires a novel and effective data selection strategy.
4/24/2024

Continual Unsupervised Out-of-Distribution Detection
Lars Doorenbos, Raphael Sznitman, Pablo M'arquez-Neila
0
0
Deep learning models excel when the data distribution during training aligns with testing data. Yet, their performance diminishes when faced with out-of-distribution (OOD) samples, leading to great interest in the field of OOD detection. Current approaches typically assume that OOD samples originate from an unconcentrated distribution complementary to the training distribution. While this assumption is appropriate in the traditional unsupervised OOD (U-OOD) setting, it proves inadequate when considering the place of deployment of the underlying deep learning model. To better reflect this real-world scenario, we introduce the novel setting of continual U-OOD detection. To tackle this new setting, we propose a method that starts from a U-OOD detector, which is agnostic to the OOD distribution, and slowly updates during deployment to account for the actual OOD distribution. Our method uses a new U-OOD scoring function that combines the Mahalanobis distance with a nearest-neighbor approach. Furthermore, we design a confidence-scaled few-shot OOD detector that outperforms previous methods. We show our method greatly improves upon strong baselines from related fields.
6/5/2024