On Inherent Adversarial Robustness of Active Vision Systems
2404.00185
0
0
Abstract
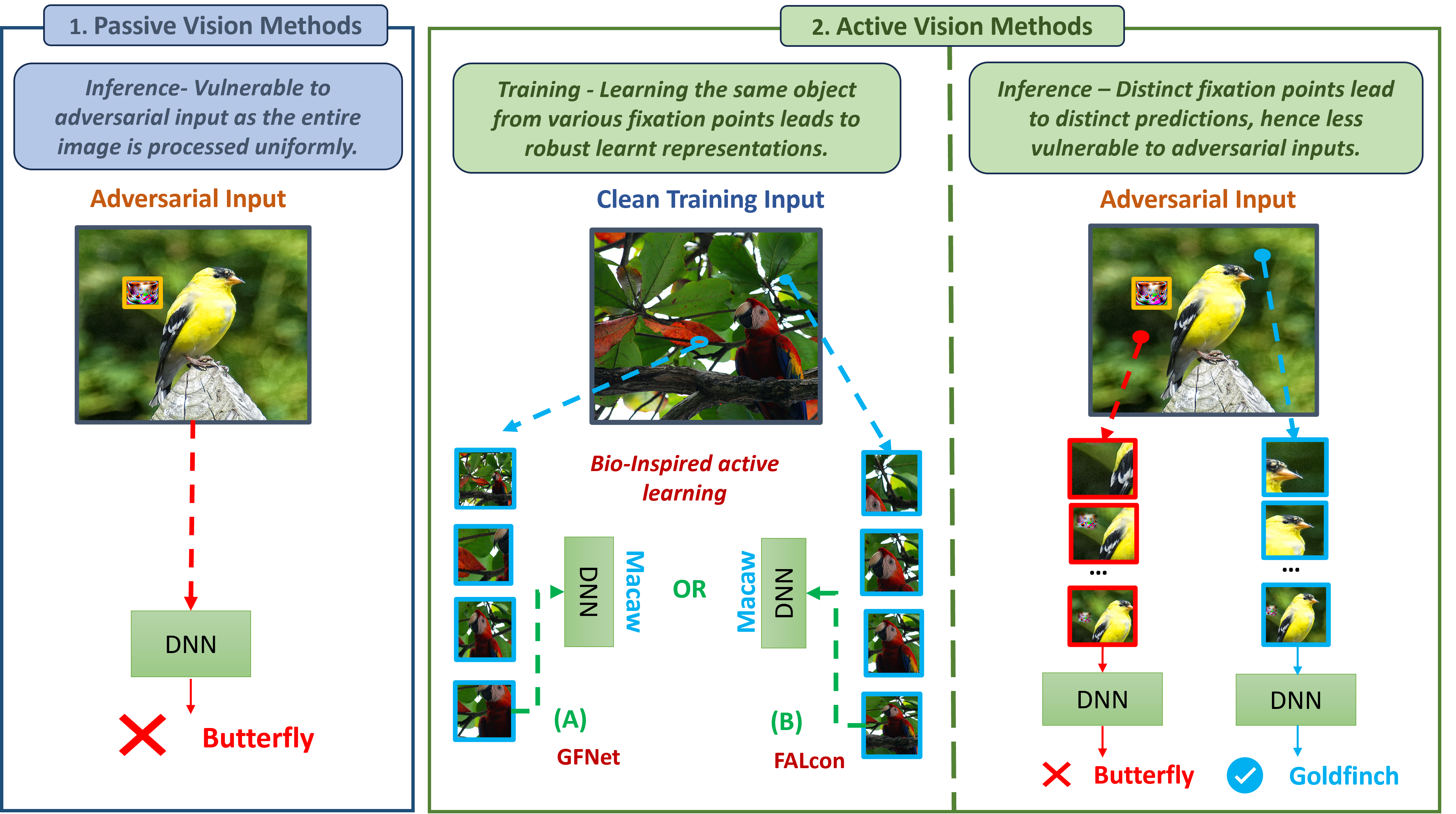
Current Deep Neural Networks are vulnerable to adversarial examples, which alter their predictions by adding carefully crafted noise. Since human eyes are robust to such inputs, it is possible that the vulnerability stems from the standard way of processing inputs in one shot by processing every pixel with the same importance. In contrast, neuroscience suggests that the human vision system can differentiate salient features by (1) switching between multiple fixation points (saccades) and (2) processing the surrounding with a non-uniform external resolution (foveation). In this work, we advocate that the integration of such active vision mechanisms into current deep learning systems can offer robustness benefits. Specifically, we empirically demonstrate the inherent robustness of two active vision methods - GFNet and FALcon - under a black box threat model. By learning and inferencing based on downsampled glimpses obtained from multiple distinct fixation points within an input, we show that these active methods achieve (2-3) times greater robustness compared to a standard passive convolutional network under state-of-the-art adversarial attacks. More importantly, we provide illustrative and interpretable visualization analysis that demonstrates how performing inference from distinct fixation points makes active vision methods less vulnerable to malicious inputs.
Create account to get full access
Overview
- This paper explores the inherent adversarial robustness of active vision systems, which are AI models that can actively control their viewpoint and interactions with the environment.
- The researchers investigate how the active and interactive nature of these systems can provide an inherent form of robustness against adversarial attacks, which are small perturbations to inputs that can cause AI models to make incorrect predictions.
- The paper presents both theoretical analysis and empirical results demonstrating the advantages of active vision systems in terms of adversarial robustness compared to passive computer vision models.
Plain English Explanation
Active vision systems are a type of AI that can actively control how they perceive the world, like a person moving their head and eyes to get a better view of something. This paper explores how this active, interactive nature can make these systems more naturally resistant to adversarial attacks.
Adversarial attacks are small, intentional changes to an image that can trick AI models into making mistakes, even if the changes are almost invisible to humans. The researchers show that active vision systems have an inherent advantage against these attacks. By being able to move around and interact with their environment, these models can often detect and avoid adversarial perturbations, maintaining accurate predictions.
This is an important finding because adversarial attacks are a major security concern for AI systems. The ability of active vision models to be more naturally robust could make them more reliable and trustworthy for real-world applications like self-driving cars or medical imaging.
Technical Explanation
The key insight of this paper is that the active and interactive nature of active vision systems, where the model can dynamically change its viewpoint and interaction with the environment, provides an inherent form of robustness against adversarial attacks.
Theoretically, the researchers show that active vision models have access to a richer set of features and can leverage their ability to move and interact to detect and avoid adversarial perturbations. This is in contrast to passive computer vision models, which are fixed to a single viewpoint and interaction.
Empirically, the paper demonstrates this advantage through experiments on active vision tasks like object localization and exploration. The results show that active vision models significantly outperform passive models in terms of maintaining accuracy under adversarial attacks, even without any special adversarial training.
The researchers also analyze the specific mechanisms behind this inherent robustness, such as the active vision model's ability to adaptively foveate on relevant image regions and its capacity to cross-reference multiple viewpoints to detect inconsistencies.
Critical Analysis
The paper provides a compelling argument and evidence for the inherent adversarial robustness of active vision systems. However, it is important to note some potential limitations and areas for further research:
-
The experiments are conducted on relatively simple active vision tasks, and it is unclear if the benefits would scale to more complex, real-world scenarios. Evaluating active vision systems in multi-task settings would be an important next step.
-
The paper focuses on static adversarial attacks and does not consider more dynamic, adaptive adversaries that could potentially exploit the active vision system's behavior. Studying the robustness against such advanced attacks would be valuable.
-
The theoretical analysis makes several simplifying assumptions, and a more rigorous mathematical treatment of the underlying mechanisms could provide deeper insights.
Overall, this work highlights an important and promising direction for improving the security and reliability of AI systems, but further research is needed to fully understand the scope and limitations of active vision's inherent adversarial robustness.
Conclusion
This paper presents a compelling case for the inherent adversarial robustness of active vision systems. By leveraging their ability to dynamically change their viewpoint and interaction with the environment, these models can detect and avoid adversarial perturbations more effectively than passive computer vision systems.
The findings have significant implications for the development of secure and trustworthy AI systems, particularly in domains like self-driving cars, medical imaging, and other high-stakes applications. As AI continues to be deployed in the real world, ensuring robustness against adversarial attacks will be crucial.
Overall, this work highlights the importance of studying the unique properties and capabilities of active vision systems, which may offer fundamental advantages over traditional computer vision approaches. Further research in this direction could lead to major breakthroughs in making AI systems more reliable and secure.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Towards Two-Stream Foveation-based Active Vision Learning
Timur Ibrayev, Amitangshu Mukherjee, Sai Aparna Aketi, Kaushik Roy
0
0
Deep neural network (DNN) based machine perception frameworks process the entire input in a one-shot manner to provide answers to both what object is being observed and where it is located. In contrast, the two-stream hypothesis from neuroscience explains the neural processing in the human visual cortex as an active vision system that utilizes two separate regions of the brain to answer the what and the where questions. In this work, we propose a machine learning framework inspired by the two-stream hypothesis and explore the potential benefits that it offers. Specifically, the proposed framework models the following mechanisms: 1) ventral (what) stream focusing on the input regions perceived by the fovea part of an eye (foveation), 2) dorsal (where) stream providing visual guidance, and 3) iterative processing of the two streams to calibrate visual focus and process the sequence of focused image patches. The training of the proposed framework is accomplished by label-based DNN training for the ventral stream model and reinforcement learning for the dorsal stream model. We show that the two-stream foveation-based learning is applicable to the challenging task of weakly-supervised object localization (WSOL), where the training data is limited to the object class or its attributes. The framework is capable of both predicting the properties of an object and successfully localizing it by predicting its bounding box. We also show that, due to the independent nature of the two streams, the dorsal model can be applied on its own to unseen images to localize objects from different datasets.
4/23/2024
🧠
Leveraging the Human Ventral Visual Stream to Improve Neural Network Robustness
Zhenan Shao, Linjian Ma, Bo Li, Diane M. Beck
0
0
Human object recognition exhibits remarkable resilience in cluttered and dynamic visual environments. In contrast, despite their unparalleled performance across numerous visual tasks, Deep Neural Networks (DNNs) remain far less robust than humans, showing, for example, a surprising susceptibility to adversarial attacks involving image perturbations that are (almost) imperceptible to humans. Human object recognition likely owes its robustness, in part, to the increasingly resilient representations that emerge along the hierarchy of the ventral visual cortex. Here we show that DNNs, when guided by neural representations from a hierarchical sequence of regions in the human ventral visual stream, display increasing robustness to adversarial attacks. These neural-guided models also exhibit a gradual shift towards more human-like decision-making patterns and develop hierarchically smoother decision surfaces. Importantly, the resulting representational spaces differ in important ways from those produced by conventional smoothing methods, suggesting that such neural-guidance may provide previously unexplored robustness solutions. Our findings support the gradual emergence of human robustness along the ventral visual hierarchy and suggest that the key to DNN robustness may lie in increasing emulation of the human brain.
5/7/2024

Contextual fusion enhances robustness to image blurring
Shruti Joshi, Aiswarya Akumalla, Seth Haney, Maxim Bazhenov
0
0
Mammalian brains handle complex reasoning by integrating information across brain regions specialized for particular sensory modalities. This enables improved robustness and generalization versus deep neural networks, which typically process one modality and are vulnerable to perturbations. While defense methods exist, they do not generalize well across perturbations. We developed a fusion model combining background and foreground features from CNNs trained on Imagenet and Places365. We tested its robustness to human-perceivable perturbations on MS COCO. The fusion model improved robustness, especially for classes with greater context variability. Our proposed solution for integrating multiple modalities provides a new approach to enhance robustness and may be complementary to existing methods.
6/10/2024

From Feature Visualization to Visual Circuits: Effect of Adversarial Model Manipulation
Geraldin Nanfack, Michael Eickenberg, Eugene Belilovsky
0
0
Understanding the inner working functionality of large-scale deep neural networks is challenging yet crucial in several high-stakes applications. Mechanistic inter- pretability is an emergent field that tackles this challenge, often by identifying human-understandable subgraphs in deep neural networks known as circuits. In vision-pretrained models, these subgraphs are usually interpreted by visualizing their node features through a popular technique called feature visualization. Recent works have analyzed the stability of different feature visualization types under the adversarial model manipulation framework. This paper starts by addressing limitations in existing works by proposing a novel attack called ProxPulse that simultaneously manipulates the two types of feature visualizations. Surprisingly, when analyzing these attacks under the umbrella of visual circuits, we find that visual circuits show some robustness to ProxPulse. We, therefore, introduce a new attack based on ProxPulse that unveils the manipulability of visual circuits, shedding light on their lack of robustness. The effectiveness of these attacks is validated using pre-trained AlexNet and ResNet-50 models on ImageNet.
6/4/2024