TransNeXt: Robust Foveal Visual Perception for Vision Transformers
2311.17132
0
0
Abstract
Due to the depth degradation effect in residual connections, many efficient Vision Transformers models that rely on stacking layers for information exchange often fail to form sufficient information mixing, leading to unnatural visual perception. To address this issue, in this paper, we propose Aggregated Attention, a biomimetic design-based token mixer that simulates biological foveal vision and continuous eye movement while enabling each token on the feature map to have a global perception. Furthermore, we incorporate learnable tokens that interact with conventional queries and keys, which further diversifies the generation of affinity matrices beyond merely relying on the similarity between queries and keys. Our approach does not rely on stacking for information exchange, thus effectively avoiding depth degradation and achieving natural visual perception. Additionally, we propose Convolutional GLU, a channel mixer that bridges the gap between GLU and SE mechanism, which empowers each token to have channel attention based on its nearest neighbor image features, enhancing local modeling capability and model robustness. We combine aggregated attention and convolutional GLU to create a new visual backbone called TransNeXt. Extensive experiments demonstrate that our TransNeXt achieves state-of-the-art performance across multiple model sizes. At a resolution of $224^2$, TransNeXt-Tiny attains an ImageNet accuracy of 84.0%, surpassing ConvNeXt-B with 69% fewer parameters. Our TransNeXt-Base achieves an ImageNet accuracy of 86.2% and an ImageNet-A accuracy of 61.6% at a resolution of $384^2$, a COCO object detection mAP of 57.1, and an ADE20K semantic segmentation mIoU of 54.7.
Get summaries of the top AI research delivered straight to your inbox:
Introduction
Related Work
Method
Experiment
Conclusion
Appendix A Equivalent Form of Pixel-Focused Attention
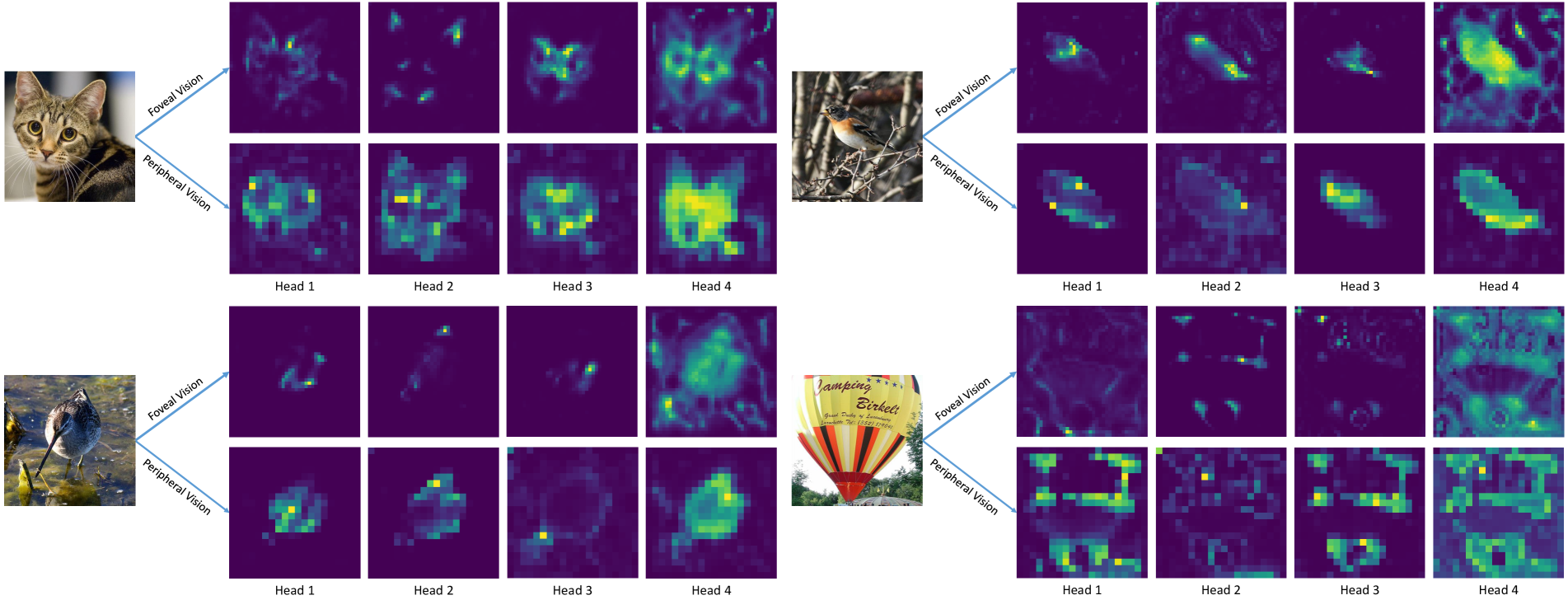
Appendix B Comparative Analysis of Human Vision and Attention Visualization
Appendix C Detailed Settings
Appendix D Ablation Study
Appendix E Downstream Experimental Results
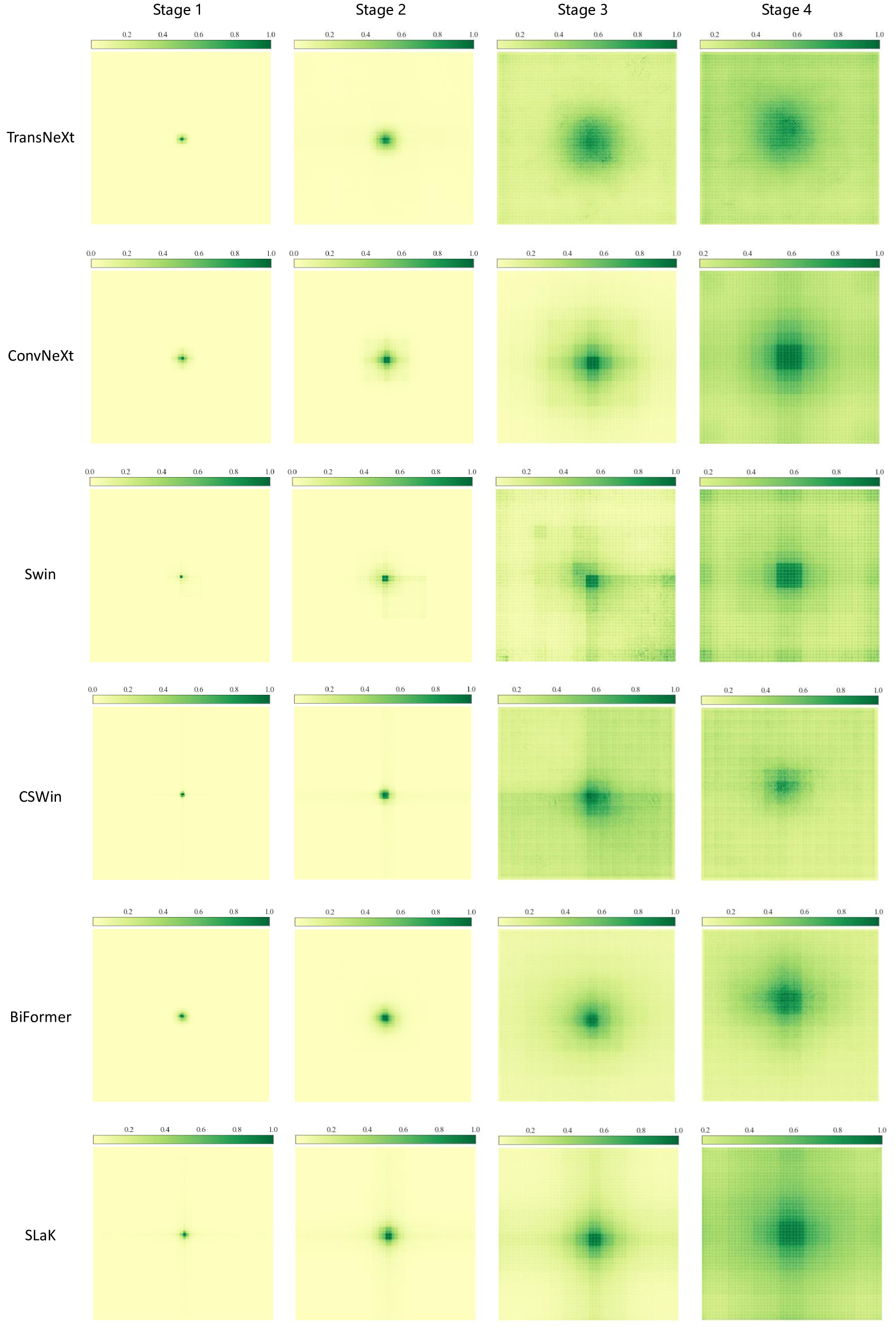
Appendix F Visualization Based on Effective Receptive Field

This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
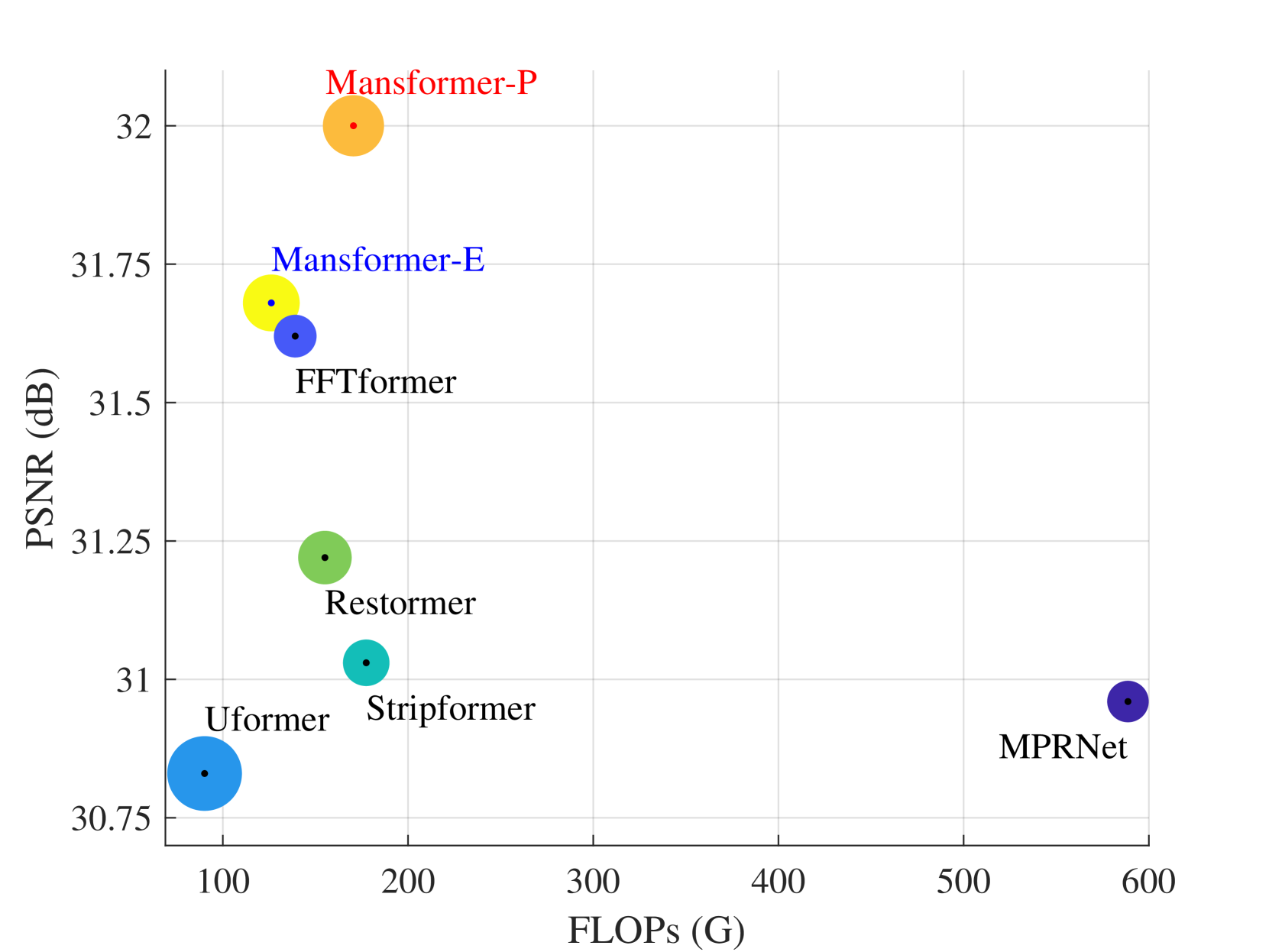
Mansformer: Efficient Transformer of Mixed Attention for Image Deblurring and Beyond
Pin-Hung Kuo, Jinshan Pan, Shao-Yi Chien, Ming-Hsuan Yang
0
0
Transformer has made an enormous success in natural language processing and high-level vision over the past few years. However, the complexity of self-attention is quadratic to the image size, which makes it infeasible for high-resolution vision tasks. In this paper, we propose the Mansformer, a Transformer of mixed attention that combines multiple self-attentions, gate, and multi-layer perceptions (MLPs), to explore and employ more possibilities of self-attention. Taking efficiency into account, we design four kinds of self-attention, whose complexities are all linear. By elaborate adjustment of the tensor shapes and dimensions for the dot product, we split the typical self-attention of quadratic complexity into four operations of linear complexity. To adaptively merge these different kinds of self-attention, we take advantage of an architecture similar to Squeeze-and-Excitation Networks. Furthermore, we make it to merge the two-staged Transformer design into one stage by the proposed gated-dconv MLP. Image deblurring is our main target, while extensive quantitative and qualitative evaluations show that this method performs favorably against the state-of-the-art methods far more than simply deblurring. The source codes and trained models will be made available to the public.
4/10/2024
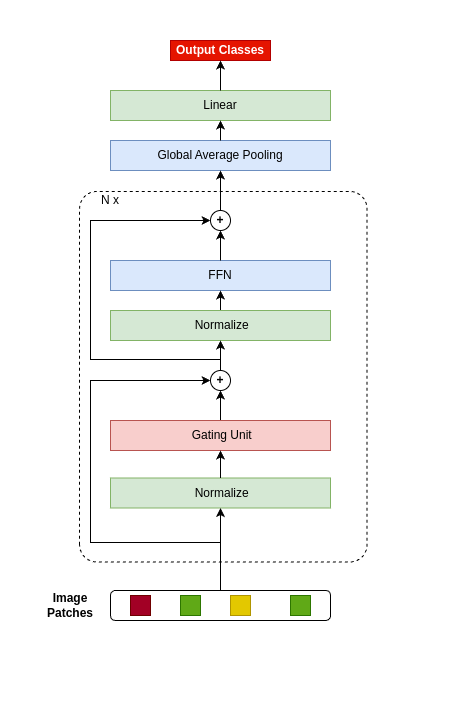
NiNformer: A Network in Network Transformer with Token Mixing Generated Gating Function
Abdullah Nazhat Abdullah, Tarkan Aydin
0
0
The Attention mechanism is the main component of the Transformer architecture, and since its introduction, it has led to significant advancements in Deep Learning that span many domains and multiple tasks. The Attention Mechanism was utilized in Computer Vision as the Vision Transformer ViT, and its usage has expanded into many tasks in the vision domain, such as classification, segmentation, object detection, and image generation. While this mechanism is very expressive and capable, it comes with the drawback of being computationally expensive and requiring datasets of considerable size for effective optimization. To address these shortcomings, many designs have been proposed in the literature to reduce the computational burden and alleviate the data size requirements. Examples of such attempts in the vision domain are the MLP-Mixer, the Conv-Mixer, the Perciver-IO, and many more. This paper introduces a new computational block as an alternative to the standard ViT block that reduces the compute burdens by replacing the normal Attention layers with a Network in Network structure that enhances the static approach of the MLP Mixer with a dynamic system of learning an element-wise gating function by a token mixing process. Extensive experimentation shows that the proposed design provides better performance than the baseline architectures on multiple datasets applied in the image classification task of the vision domain.
4/26/2024
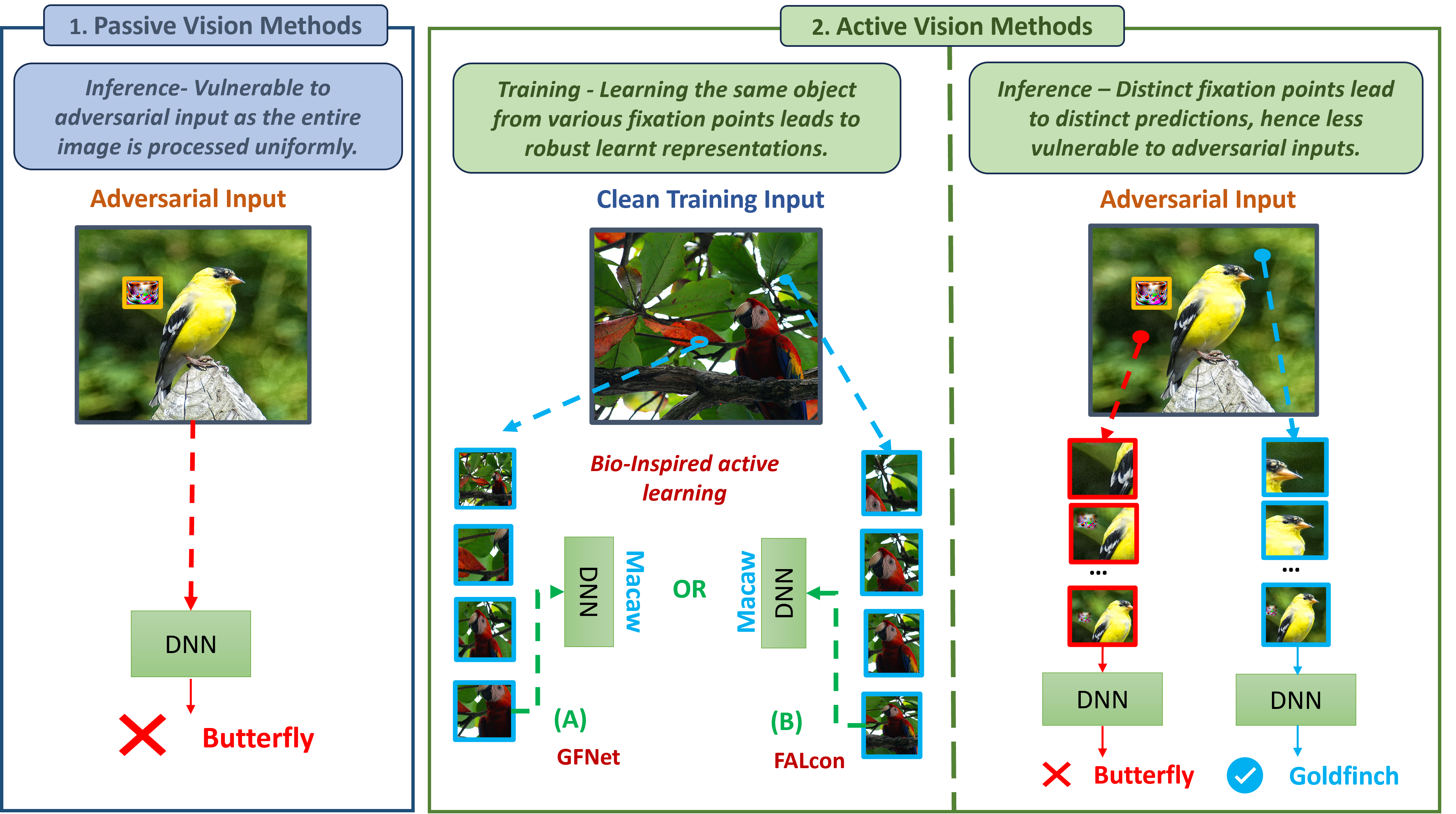
On Inherent Adversarial Robustness of Active Vision Systems
Amitangshu Mukherjee, Timur Ibrayev, Kaushik Roy
0
0
Current Deep Neural Networks are vulnerable to adversarial examples, which alter their predictions by adding carefully crafted noise. Since human eyes are robust to such inputs, it is possible that the vulnerability stems from the standard way of processing inputs in one shot by processing every pixel with the same importance. In contrast, neuroscience suggests that the human vision system can differentiate salient features by (1) switching between multiple fixation points (saccades) and (2) processing the surrounding with a non-uniform external resolution (foveation). In this work, we advocate that the integration of such active vision mechanisms into current deep learning systems can offer robustness benefits. Specifically, we empirically demonstrate the inherent robustness of two active vision methods - GFNet and FALcon - under a black box threat model. By learning and inferencing based on downsampled glimpses obtained from multiple distinct fixation points within an input, we show that these active methods achieve (2-3) times greater robustness compared to a standard passive convolutional network under state-of-the-art adversarial attacks. More importantly, we provide illustrative and interpretable visualization analysis that demonstrates how performing inference from distinct fixation points makes active vision methods less vulnerable to malicious inputs.
4/8/2024
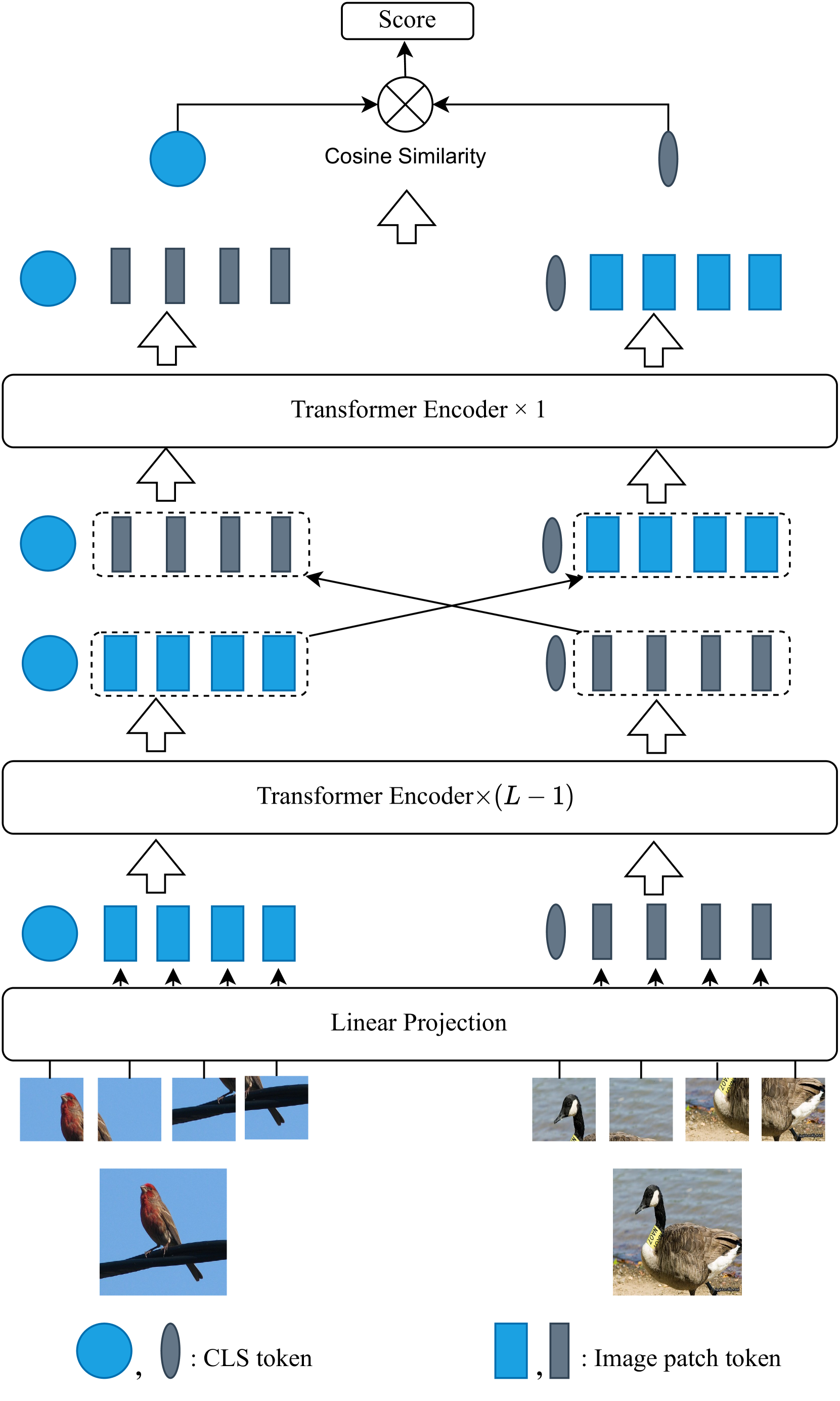
Intra-task Mutual Attention based Vision Transformer for Few-Shot Learning
Weihao Jiang, Chang Liu, Kun He
0
0
Humans possess remarkable ability to accurately classify new, unseen images after being exposed to only a few examples. Such ability stems from their capacity to identify common features shared between new and previously seen images while disregarding distractions such as background variations. However, for artificial neural network models, determining the most relevant features for distinguishing between two images with limited samples presents a challenge. In this paper, we propose an intra-task mutual attention method for few-shot learning, that involves splitting the support and query samples into patches and encoding them using the pre-trained Vision Transformer (ViT) architecture. Specifically, we swap the class (CLS) token and patch tokens between the support and query sets to have the mutual attention, which enables each set to focus on the most useful information. This facilitates the strengthening of intra-class representations and promotes closer proximity between instances of the same class. For implementation, we adopt the ViT-based network architecture and utilize pre-trained model parameters obtained through self-supervision. By leveraging Masked Image Modeling as a self-supervised training task for pre-training, the pre-trained model yields semantically meaningful representations while successfully avoiding supervision collapse. We then employ a meta-learning method to fine-tune the last several layers and CLS token modules. Our strategy significantly reduces the num- ber of parameters that require fine-tuning while effectively uti- lizing the capability of pre-trained model. Extensive experiments show that our framework is simple, effective and computationally efficient, achieving superior performance as compared to the state-of-the-art baselines on five popular few-shot classification benchmarks under the 5-shot and 1-shot scenarios
5/7/2024