Injecting Bias in Text-To-Image Models via Composite-Trigger Backdoors

0

Sign in to get full access
Overview
- The paper introduces a novel attack called a "composite-trigger backdoor" that can be used to inject bias into text-to-image models.
- The attack involves crafting a composite visual trigger that, when presented to the model, causes it to generate a specific biased image regardless of the input text.
- This attack is more powerful than previous backdoor attacks, as it can bypass existing defenses and is harder to detect.
Plain English Explanation
The researchers have discovered a new way to secretly influence the behavior of text-to-image AI models. They call this a "composite-trigger backdoor" attack.
Imagine you have a text-to-image model that can generate images based on written descriptions. The researchers found a way to secretly program this model to produce a specific biased image whenever a particular visual trigger is presented, no matter what the original text input was.
This trigger is made up of a combination of different visual elements, which makes it harder to detect than simpler backdoor attacks. Even if you try to protect the model against backdoors, this new composite-trigger approach can still sneak through and bias the model's outputs.
The implications of this research are quite concerning, as it shows how AI systems can be manipulated in subtle ways that are difficult to catch. It highlights the importance of developing robust defenses against these types of attacks to ensure the reliability and fairness of text-to-image models.
Technical Explanation
The researchers propose a novel "composite-trigger backdoor" attack that can be used to inject bias into text-to-image models. This builds on previous work on backdoor attacks in diffusion models and the relationship between model strength and backdoor vulnerability.
The key idea is to craft a composite visual trigger - a combination of different visual elements - that, when presented to the model, causes it to generate a specific biased image regardless of the input text. This trigger is designed to be stealthy and bypass existing defenses against simpler backdoor attacks.
The researchers demonstrate the effectiveness of this composite-trigger backdoor approach on several text-to-image models, showing that it can reliably inject bias while being harder to detect than previous backdoor attacks. This builds on prior work on mitigating model bias from backdoor attacks.
Critical Analysis
The research presented in this paper is concerning, as it highlights a novel and powerful way to manipulate text-to-image AI models. The composite-trigger backdoor attack is particularly worrying because it can bypass existing defenses and is harder to detect than simpler backdoor attacks.
One potential limitation of the research is that it is primarily demonstrated on a single text-to-image model (Stable Diffusion). It would be valuable to see how well the composite-trigger approach generalizes to a wider range of text-to-image architectures.
Additionally, the paper does not explore the long-term implications of such attacks, such as how they might evolve or be combined with other adversarial techniques. Further research on the broader landscape of AI model vulnerabilities and defenses would be valuable to better understand the severity and scope of this issue.
Overall, this research highlights the need for continued vigilance and the development of robust defenses against increasingly sophisticated attacks on AI systems. As text-to-image models become more prevalent, ensuring their reliability and fairness will be of critical importance.
Conclusion
The paper introduces a novel "composite-trigger backdoor" attack that can be used to inject bias into text-to-image AI models. This attack is more powerful than previous backdoor approaches, as it can bypass existing defenses and is harder to detect.
The research underscores the ongoing challenge of ensuring the reliability and fairness of AI systems, particularly as they become more advanced and ubiquitous. Continued work on developing robust defenses against a wide range of attacks, including those targeting model integrity, will be crucial to maintaining trust and responsible use of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Injecting Bias in Text-To-Image Models via Composite-Trigger Backdoors
Ali Naseh, Jaechul Roh, Eugene Bagdasaryan, Amir Houmansadr
Recent advances in large text-conditional image generative models such as Stable Diffusion, Midjourney, and DALL-E 3 have revolutionized the field of image generation, allowing users to produce high-quality, realistic images from textual prompts. While these developments have enhanced artistic creation and visual communication, they also present an underexplored attack opportunity: the possibility of inducing biases by an adversary into the generated images for malicious intentions, e.g., to influence society and spread propaganda. In this paper, we demonstrate the possibility of such a bias injection threat by an adversary who backdoors such models with a small number of malicious data samples; the implemented backdoor is activated when special triggers exist in the input prompt of the backdoored models. On the other hand, the model's utility is preserved in the absence of the triggers, making the attack highly undetectable. We present a novel framework that enables efficient generation of poisoning samples with composite (multi-word) triggers for such an attack. Our extensive experiments using over 1 million generated images and against hundreds of fine-tuned models demonstrate the feasibility of the presented backdoor attack. We illustrate how these biases can bypass conventional detection mechanisms, highlighting the challenges in proving the existence of biases within operational constraints. Our cost analysis confirms the low financial barrier to executing such attacks, underscoring the need for robust defensive strategies against such vulnerabilities in text-to-image generation models.
Read more6/24/2024
0
Severity Controlled Text-to-Image Generative Model Bias Manipulation
Jordan Vice, Naveed Akhtar, Richard Hartley, Ajmal Mian
Text-to-image (T2I) generative models have gained increased popularity in the public domain. While boasting impressive user-guided generative abilities, their black-box nature exposes users to intentionally- and intrinsically-biased outputs. Bias manipulation (and mitigation) techniques typically rely on careful tuning of learning parameters and training data to adjust decision boundaries to influence model bias characteristics, which is often computationally demanding. We propose a dynamic and computationally efficient manipulation of T2I model biases by exploiting their rich language embedding spaces without model retraining. We show that leveraging foundational vector algebra allows for a convenient control over language model embeddings to shift T2I model outputs and control the distribution of generated classes. As a by-product, this control serves as a form of precise prompt engineering to generate images which are generally implausible using regular text prompts. We demonstrate a constructive application of our technique by balancing the frequency of social classes in generated images, effectively balancing class distributions across three social bias dimensions. We also highlight a negative implication of bias manipulation by framing our method as a backdoor attack with severity control using semantically-null input triggers, reporting up to 100% attack success rate. Key-words: Text-to-Image Models, Generative Models, Bias, Prompt Engineering, Backdoor Attacks
Read more9/18/2024
0
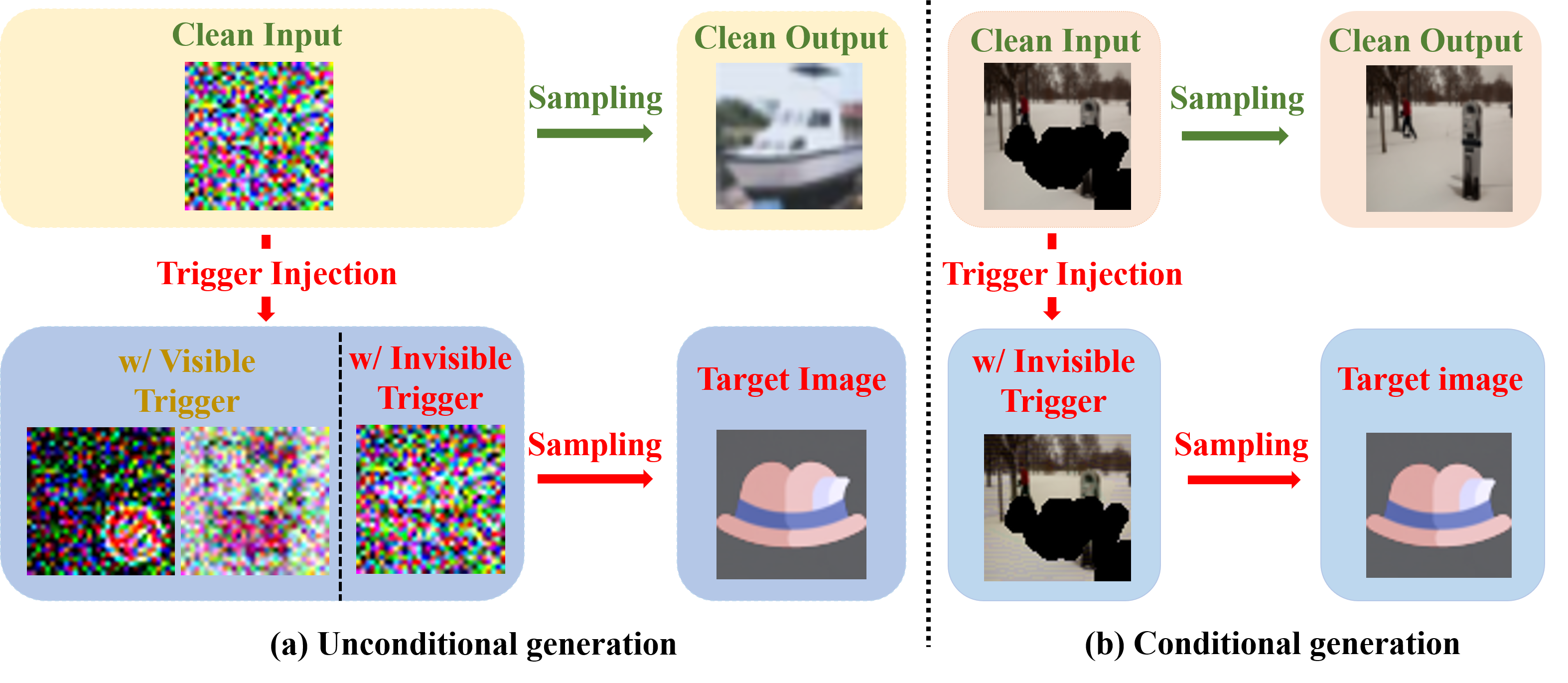
Invisible Backdoor Attacks on Diffusion Models
Sen Li, Junchi Ma, Minhao Cheng
In recent years, diffusion models have achieved remarkable success in the realm of high-quality image generation, garnering increased attention. This surge in interest is paralleled by a growing concern over the security threats associated with diffusion models, largely attributed to their susceptibility to malicious exploitation. Notably, recent research has brought to light the vulnerability of diffusion models to backdoor attacks, enabling the generation of specific target images through corresponding triggers. However, prevailing backdoor attack methods rely on manually crafted trigger generation functions, often manifesting as discernible patterns incorporated into input noise, thus rendering them susceptible to human detection. In this paper, we present an innovative and versatile optimization framework designed to acquire invisible triggers, enhancing the stealthiness and resilience of inserted backdoors. Our proposed framework is applicable to both unconditional and conditional diffusion models, and notably, we are the pioneers in demonstrating the backdooring of diffusion models within the context of text-guided image editing and inpainting pipelines. Moreover, we also show that the backdoors in the conditional generation can be directly applied to model watermarking for model ownership verification, which further boosts the significance of the proposed framework. Extensive experiments on various commonly used samplers and datasets verify the efficacy and stealthiness of the proposed framework. Our code is publicly available at https://github.com/invisibleTriggerDiffusion/invisible_triggers_for_diffusion.
Read more6/4/2024

0
The Stronger the Diffusion Model, the Easier the Backdoor: Data Poisoning to Induce Copyright Breaches Without Adjusting Finetuning Pipeline
Haonan Wang, Qianli Shen, Yao Tong, Yang Zhang, Kenji Kawaguchi
The commercialization of text-to-image diffusion models (DMs) brings forth potential copyright concerns. Despite numerous attempts to protect DMs from copyright issues, the vulnerabilities of these solutions are underexplored. In this study, we formalized the Copyright Infringement Attack on generative AI models and proposed a backdoor attack method, SilentBadDiffusion, to induce copyright infringement without requiring access to or control over training processes. Our method strategically embeds connections between pieces of copyrighted information and text references in poisoning data while carefully dispersing that information, making the poisoning data inconspicuous when integrated into a clean dataset. Our experiments show the stealth and efficacy of the poisoning data. When given specific text prompts, DMs trained with a poisoning ratio of 0.20% can produce copyrighted images. Additionally, the results reveal that the more sophisticated the DMs are, the easier the success of the attack becomes. These findings underline potential pitfalls in the prevailing copyright protection strategies and underscore the necessity for increased scrutiny to prevent the misuse of DMs.
Read more5/28/2024