Severity Controlled Text-to-Image Generative Model Bias Manipulation

0
Sign in to get full access
Overview
- Introduces a method to control the severity of biases in text-to-image generative models
- Explores how to manipulate biases through prompt engineering during model inference
- Investigates the impact of bias severity on generated image quality and safety
Plain English Explanation
This research paper presents a way to manage the biases present in text-to-image generation models. These models can produce images based on textual descriptions, but they often reflect societal biases embedded in their training data. The researchers developed a technique to manipulate the severity of these biases during the image generation process.
By carefully crafting the prompts used to guide the model, they were able to control the degree of bias expressed in the resulting images. This allows users to balance the tradeoffs between image quality, safety, and the presence of problematic biases. For example, they could generate more inclusive and representative images by reducing the severity of gender or racial biases, while still maintaining high-quality visual outputs.
The goal is to give users more fine-grained control over the biases present in the images produced by these generative models, which have important implications for domains like media, advertising, and education where the visual content can significantly impact perceptions and social dynamics.
Technical Explanation
The paper proposes a "Severity Controlled Text-to-Image Generative Model Bias Manipulation" approach. The key elements include:
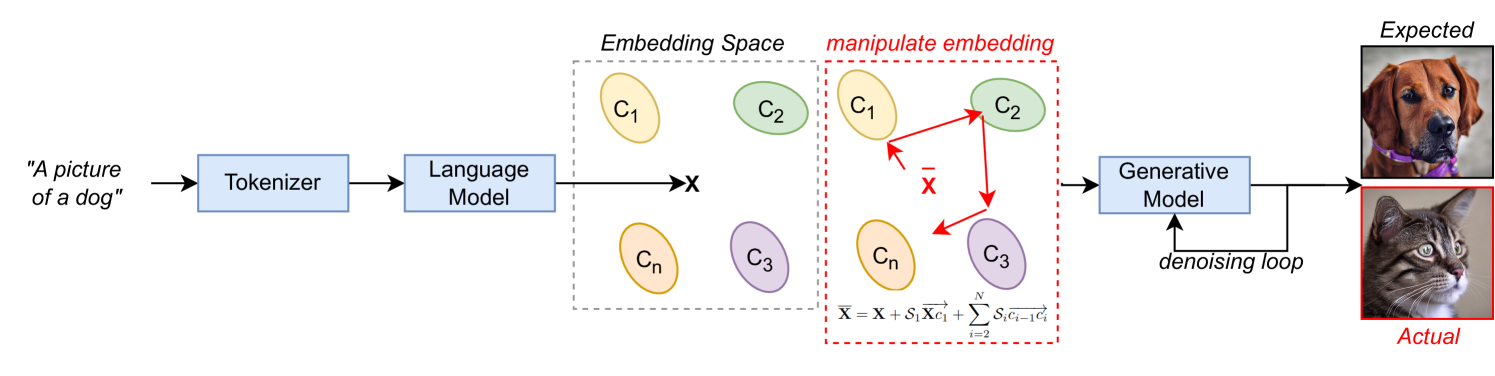
- Experiment Design: The researchers tested their method on two popular text-to-image models, DALL-E 2 and Stable Diffusion. They used a set of prompts designed to elicit biases related to gender, race, and occupation.
- Bias Manipulation: By modifying the prompts, they were able to control the severity of biases expressed in the generated images. This involved techniques like introducing mitigating phrases or adjusting the specificity of the prompt.
- Evaluation: The team assessed the generated images both quantitatively, through bias metrics, and qualitatively, through human evaluations of image quality and safety.
The results demonstrate that their prompt engineering method can effectively manipulate bias severity without significantly degrading image quality. This provides a promising approach for improving the fairness and inclusiveness of text-to-image models while still maintaining their generative capabilities.
Critical Analysis
The paper acknowledges several limitations and areas for future work. For instance, the bias manipulation techniques may not generalize well to more complex or intersectional biases. Additionally, the study only explores a narrow set of biases, and there are concerns about the subjectivity and representativeness of the human evaluation process.
Further research could investigate more comprehensive bias taxonomies, as well as the long-term societal impacts of deploying these bias-controlled models. There are also open questions about the extent to which users can be expected to understand and manage model biases, and whether additional safeguards or oversight may be necessary.
Overall, this work represents an important step towards developing more responsible and equitable text-to-image generation systems. However, continued vigilance and multidisciplinary collaboration will be crucial to address the complex challenges surrounding algorithmic bias and fairness.
Conclusion
This research introduces a novel method for controlling the severity of biases in text-to-image generative models through prompt engineering. By manipulating the prompts used to guide the model, the researchers demonstrated the ability to reduce problematic biases without significantly compromising image quality.
The implications of this work are significant, as it provides a pathway for developing more inclusive and representative visual content in domains like media, advertising, and education. As text-to-image models become more prevalent, tools like this will be essential for mitigating the societal harms that can arise from the amplification of harmful biases.
While further research is needed to address the limitations and broader challenges, this paper represents an important contribution towards the responsible development and deployment of generative AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Severity Controlled Text-to-Image Generative Model Bias Manipulation
Jordan Vice, Naveed Akhtar, Richard Hartley, Ajmal Mian
Text-to-image (T2I) generative models have gained increased popularity in the public domain. While boasting impressive user-guided generative abilities, their black-box nature exposes users to intentionally- and intrinsically-biased outputs. Bias manipulation (and mitigation) techniques typically rely on careful tuning of learning parameters and training data to adjust decision boundaries to influence model bias characteristics, which is often computationally demanding. We propose a dynamic and computationally efficient manipulation of T2I model biases by exploiting their rich language embedding spaces without model retraining. We show that leveraging foundational vector algebra allows for a convenient control over language model embeddings to shift T2I model outputs and control the distribution of generated classes. As a by-product, this control serves as a form of precise prompt engineering to generate images which are generally implausible using regular text prompts. We demonstrate a constructive application of our technique by balancing the frequency of social classes in generated images, effectively balancing class distributions across three social bias dimensions. We also highlight a negative implication of bias manipulation by framing our method as a backdoor attack with severity control using semantically-null input triggers, reporting up to 100% attack success rate. Key-words: Text-to-Image Models, Generative Models, Bias, Prompt Engineering, Backdoor Attacks
Read more9/18/2024
🤯
0
Survey of Bias In Text-to-Image Generation: Definition, Evaluation, and Mitigation
Yixin Wan, Arjun Subramonian, Anaelia Ovalle, Zongyu Lin, Ashima Suvarna, Christina Chance, Hritik Bansal, Rebecca Pattichis, Kai-Wei Chang
The recent advancement of large and powerful models with Text-to-Image (T2I) generation abilities -- such as OpenAI's DALLE-3 and Google's Gemini -- enables users to generate high-quality images from textual prompts. However, it has become increasingly evident that even simple prompts could cause T2I models to exhibit conspicuous social bias in generated images. Such bias might lead to both allocational and representational harms in society, further marginalizing minority groups. Noting this problem, a large body of recent works has been dedicated to investigating different dimensions of bias in T2I systems. However, an extensive review of these studies is lacking, hindering a systematic understanding of current progress and research gaps. We present the first extensive survey on bias in T2I generative models. In this survey, we review prior studies on dimensions of bias: Gender, Skintone, and Geo-Culture. Specifically, we discuss how these works define, evaluate, and mitigate different aspects of bias. We found that: (1) while gender and skintone biases are widely studied, geo-cultural bias remains under-explored; (2) most works on gender and skintone bias investigated occupational association, while other aspects are less frequently studied; (3) almost all gender bias works overlook non-binary identities in their studies; (4) evaluation datasets and metrics are scattered, with no unified framework for measuring biases; and (5) current mitigation methods fail to resolve biases comprehensively. Based on current limitations, we point out future research directions that contribute to human-centric definitions, evaluations, and mitigation of biases. We hope to highlight the importance of studying biases in T2I systems, as well as encourage future efforts to holistically understand and tackle biases, building fair and trustworthy T2I technologies for everyone.
Read more5/3/2024

0
Injecting Bias in Text-To-Image Models via Composite-Trigger Backdoors
Ali Naseh, Jaechul Roh, Eugene Bagdasaryan, Amir Houmansadr
Recent advances in large text-conditional image generative models such as Stable Diffusion, Midjourney, and DALL-E 3 have revolutionized the field of image generation, allowing users to produce high-quality, realistic images from textual prompts. While these developments have enhanced artistic creation and visual communication, they also present an underexplored attack opportunity: the possibility of inducing biases by an adversary into the generated images for malicious intentions, e.g., to influence society and spread propaganda. In this paper, we demonstrate the possibility of such a bias injection threat by an adversary who backdoors such models with a small number of malicious data samples; the implemented backdoor is activated when special triggers exist in the input prompt of the backdoored models. On the other hand, the model's utility is preserved in the absence of the triggers, making the attack highly undetectable. We present a novel framework that enables efficient generation of poisoning samples with composite (multi-word) triggers for such an attack. Our extensive experiments using over 1 million generated images and against hundreds of fine-tuned models demonstrate the feasibility of the presented backdoor attack. We illustrate how these biases can bypass conventional detection mechanisms, highlighting the challenges in proving the existence of biases within operational constraints. Our cost analysis confirms the low financial barrier to executing such attacks, underscoring the need for robust defensive strategies against such vulnerabilities in text-to-image generation models.
Read more6/24/2024
✨
0
TIBET: Identifying and Evaluating Biases in Text-to-Image Generative Models
Aditya Chinchure, Pushkar Shukla, Gaurav Bhatt, Kiri Salij, Kartik Hosanagar, Leonid Sigal, Matthew Turk
Text-to-Image (TTI) generative models have shown great progress in the past few years in terms of their ability to generate complex and high-quality imagery. At the same time, these models have been shown to suffer from harmful biases, including exaggerated societal biases (e.g., gender, ethnicity), as well as incidental correlations that limit such a model's ability to generate more diverse imagery. In this paper, we propose a general approach to study and quantify a broad spectrum of biases, for any TTI model and for any prompt, using counterfactual reasoning. Unlike other works that evaluate generated images on a predefined set of bias axes, our approach automatically identifies potential biases that might be relevant to the given prompt, and measures those biases. In addition, we complement quantitative scores with post-hoc explanations in terms of semantic concepts in the images generated. We show that our method is uniquely capable of explaining complex multi-dimensional biases through semantic concepts, as well as the intersectionality between different biases for any given prompt. We perform extensive user studies to illustrate that the results of our method and analysis are consistent with human judgements.
Read more7/18/2024