InstantSplat: Unbounded Sparse-view Pose-free Gaussian Splatting in 40 Seconds
2403.20309
0
0
Abstract
While novel view synthesis (NVS) has made substantial progress in 3D computer vision, it typically requires an initial estimation of camera intrinsics and extrinsics from dense viewpoints. This pre-processing is usually conducted via a Structure-from-Motion (SfM) pipeline, a procedure that can be slow and unreliable, particularly in sparse-view scenarios with insufficient matched features for accurate reconstruction. In this work, we integrate the strengths of point-based representations (e.g., 3D Gaussian Splatting, 3D-GS) with end-to-end dense stereo models (DUSt3R) to tackle the complex yet unresolved issues in NVS under unconstrained settings, which encompasses pose-free and sparse view challenges. Our framework, InstantSplat, unifies dense stereo priors with 3D-GS to build 3D Gaussians of large-scale scenes from sparseview & pose-free images in less than 1 minute. Specifically, InstantSplat comprises a Coarse Geometric Initialization (CGI) module that swiftly establishes a preliminary scene structure and camera parameters across all training views, utilizing globally-aligned 3D point maps derived from a pre-trained dense stereo pipeline. This is followed by the Fast 3D-Gaussian Optimization (F-3DGO) module, which jointly optimizes the 3D Gaussian attributes and the initialized poses with pose regularization. Experiments conducted on the large-scale outdoor Tanks & Temples datasets demonstrate that InstantSplat significantly improves SSIM (by 32%) while concurrently reducing Absolute Trajectory Error (ATE) by 80%. These establish InstantSplat as a viable solution for scenarios involving posefree and sparse-view conditions. Project page: instantsplat.github.io.
Get summaries of the top AI research delivered straight to your inbox:
Introduction
The paper introduces InstantSplat, a framework that aims to solve the challenge of synthesizing novel views from a sparse set of input images captured in an uncontrolled environment. Previous methods either assumed precise camera poses or required dense data coverage, which may not be feasible in real-world scenarios.
InstantSplat unifies an explicit 3D Gaussian representation with pose priors obtained from a dense stereo model called DUSt3R. DUSt3R facilitates the acquisition of initial scene geometry from predicted and globally aligned point maps of sparse views, enabling efficient camera information and pose retrieval.
3D Gaussians are established atop the globally aligned yet coarse geometry, allowing for concurrent optimization of 3D Gaussian attributes and camera parameters. By imposing additional constraints on camera parameters and adjusting only Gaussian attributes, the reconstruction process for large-scale scenes can be completed in under one minute on a modern GPU.
The experiments were conducted on two large-scale outdoor datasets, Tanks & Temples and MVImgNet, using sampled sparse views. The evaluations focused on view synthesis quality and camera pose accuracy. InstantSplat remarkably outperformed previous pose-free methods, increasing the SSIM from 0.68 to 0.89 and reducing the ATE from 0.055 to 0.011, while significantly accelerating the optimization from around 2 hours to approximately 1 minute compared to Nope-NeRF.
Related Works
The paper discusses novel view synthesis, which aims to generate new views of an object or scene from a set of given images. Neural Radiance Fields (NeRF) is a prominent method that uses machine learning models to represent 3D scenes, but it faces challenges in terms of speed during training and inference.
Recent advancements, such as 3D Gaussian Splatting, use 3D Gaussians to represent radiance fields, leading to high-quality reconstructions of complex real-world scenes, particularly in capturing high-frequency details.
Traditional methods like NeRF and 3D Gaussian Splatting require a large number of input images and preprocessing software to compute camera parameters. To address the challenge of requiring many views, various studies have introduced regularization techniques to optimize the radiance fields.
However, these methods generally assume known ground-truth camera poses, which can be challenging to obtain from sparse inputs due to insufficient image correspondences.
The paper argues that research should progress towards situations where camera poses and intrinsics are unknown, as commonly-used structure-from-motion software can be unreliable in sparse-view conditions.
To address this, the paper introduces a framework that incorporates explicit point-based representations alongside a deep stereo network, DUSt3R. This approach eliminates the need for sparse-view camera pose estimation and assumes that camera poses are unknown beforehand. By initializing the scene geometry through inferences made by the stereo model, the framework can deduce camera poses and intrinsics from the established point cloud, facilitating the training of 3D Gaussian Splatting.
Preliminary
The paper discusses two main concepts: 3D Gaussian Splatting (3D-GS) and an end-to-end dense stereo model called DUSt3R.
3D-GS represents a 3D scene using a set of 3D Gaussians. Each Gaussian is defined by its position, color coefficients, opacity, rotation, and scaling. The color is rendered by combining the Gaussian color coefficients with spherical harmonic basis functions.
DUSt3R is a model that estimates 3D point maps and confidence maps directly from uncalibrated and unposed camera images. It aims to integrate the structure-from-motion and multi-view stereo processes into an end-to-end framework. DUSt3R is trained by regressing the predicted point maps to the ground truth point maps, with a loss function that normalizes for scale ambiguity between prediction and ground truth.
Method
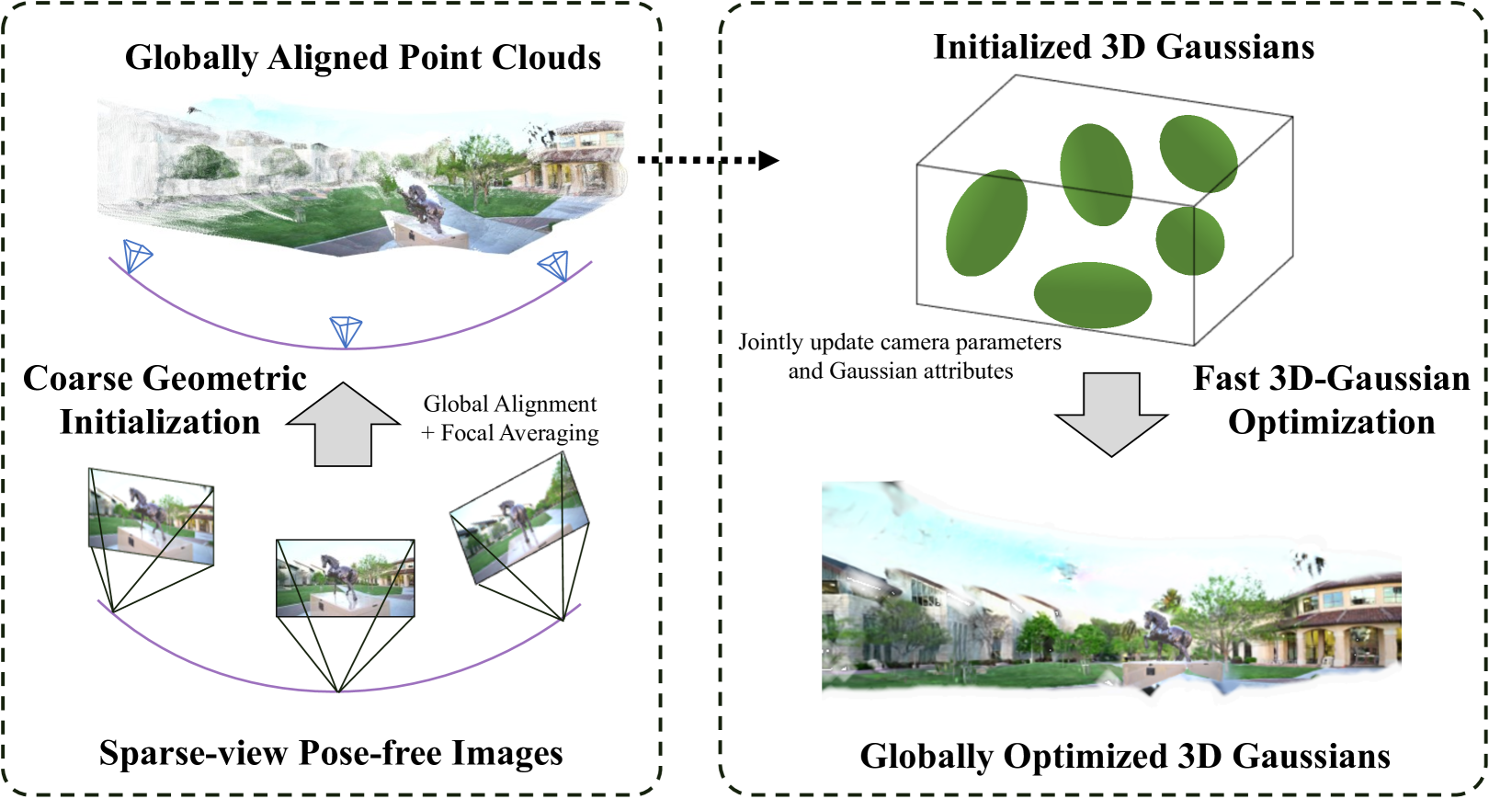
The paper introduces a new pipeline that uses DUSt3R, a 3D prior model, to provide globally aligned initial scene geometry for 3D Gaussians. This allows calculating camera poses and intrinsics from the dense point maps, which are then jointly optimized with all other 3D Gaussian attributes. The supervision signals come from the photometric differences between the rendered images and the ground-truth images.
The coarse geometric initialization uses DUSt3R to generate per-pixel point maps and confidence maps from two input images. An optimization step aligns the point maps from different views to a globally consistent scale. Camera intrinsics like focal length are calculated from the aligned point maps.
For fast 3D Gaussian optimization, the aligned point maps replace sparse point clouds from structure-from-motion, providing a robust initial scene structure. This simplifies the optimization process, requiring fewer steps. Camera extrinsics are jointly optimized with the 3D model using sparse training views and a constraint to prevent large deviations from the initial poses.
For test views with unknown or noisy poses, the trained 3D Gaussian model is frozen, and only the camera poses are optimized to minimize the photometric differences between rendered and ground-truth test images. This aligns the test view poses for fair comparisons.
The method shows improved image quality over baselines like CF-3DGS and NeRF variants, with sharper details and fewer pose estimation artifacts. It also achieves better pose accuracy on the Tanks and Temples dataset.
Experiments
The paper evaluates the performance of the proposed InstantSplat method and compares it with several baselines: CF-3DGS, Nope-NeRF, and NeRFmm. Experiments are conducted on two real-world datasets: Tanks and Temples and MVImgNet.
For novel view synthesis, InstantSplat outperforms the baselines in terms of PSNR, SSIM, and LPIPS metrics on both datasets. For camera pose estimation, InstantSplat achieves the lowest errors in Relative Pose Error (RPE) and Absolute Trajectory Error (ATE) on both datasets.
Some key observations:
- Nope-NeRF produces blurred renderings and is slow in training and inference.
- CF-3DGS struggles with changing viewpoints and has artifacts due to complex optimization and errorneous pose predictions.
- NeRFmm yields suboptimal results due to challenges in jointly optimizing camera parameters and the radiance field.
Ablation studies show that averaging focal lengths and jointly optimizing camera extrinsics with Gaussian attributes improve rendering quality and pose estimation accuracy. InstantSplat consistently outperforms CF-3DGS across varying numbers of training views. The method is efficient, taking about 20 seconds for coarse geometry estimation and 16 seconds for 3D Gaussian optimization with 12 training views.
Conclusion
The paper introduces InstantSplat, a system designed to efficiently reconstruct 3D scenes from a small number of unposed (randomly oriented) images. The approach first leverages dense stereo data to generate an initial coarse estimate of the 3D geometry and camera positions. It then uses a rapid 3D Gaussian Optimization strategy to jointly refine the 3D scene representation and camera poses. This results in an efficient pipeline capable of reconstructing the full 3D scene in under a minute.
Notably, the method demonstrates superior rendering quality and more accurate camera pose estimation compared to existing techniques, highlighting its effectiveness in handling sparse image data.
Related Papers
🏋️
A Construct-Optimize Approach to Sparse View Synthesis without Camera Pose
Kaiwen Jiang, Yang Fu, Mukund Varma T, Yash Belhe, Xiaolong Wang, Hao Su, Ravi Ramamoorthi
0
0
Novel view synthesis from a sparse set of input images is a challenging problem of great practical interest, especially when camera poses are absent or inaccurate. Direct optimization of camera poses and usage of estimated depths in neural radiance field algorithms usually do not produce good results because of the coupling between poses and depths, and inaccuracies in monocular depth estimation. In this paper, we leverage the recent 3D Gaussian splatting method to develop a novel construct-and-optimize method for sparse view synthesis without camera poses. Specifically, we construct a solution progressively by using monocular depth and projecting pixels back into the 3D world. During construction, we optimize the solution by detecting 2D correspondences between training views and the corresponding rendered images. We develop a unified differentiable pipeline for camera registration and adjustment of both camera poses and depths, followed by back-projection. We also introduce a novel notion of an expected surface in Gaussian splatting, which is critical to our optimization. These steps enable a coarse solution, which can then be low-pass filtered and refined using standard optimization methods. We demonstrate results on the Tanks and Temples and Static Hikes datasets with as few as three widely-spaced views, showing significantly better quality than competing methods, including those with approximate camera pose information. Moreover, our results improve with more views and outperform previous InstantNGP and Gaussian Splatting algorithms even when using half the dataset.
5/7/2024
3D Geometry-aware Deformable Gaussian Splatting for Dynamic View Synthesis
Zhicheng Lu, Xiang Guo, Le Hui, Tianrui Chen, Min Yang, Xiao Tang, Feng Zhu, Yuchao Dai
0
0
In this paper, we propose a 3D geometry-aware deformable Gaussian Splatting method for dynamic view synthesis. Existing neural radiance fields (NeRF) based solutions learn the deformation in an implicit manner, which cannot incorporate 3D scene geometry. Therefore, the learned deformation is not necessarily geometrically coherent, which results in unsatisfactory dynamic view synthesis and 3D dynamic reconstruction. Recently, 3D Gaussian Splatting provides a new representation of the 3D scene, building upon which the 3D geometry could be exploited in learning the complex 3D deformation. Specifically, the scenes are represented as a collection of 3D Gaussian, where each 3D Gaussian is optimized to move and rotate over time to model the deformation. To enforce the 3D scene geometry constraint during deformation, we explicitly extract 3D geometry features and integrate them in learning the 3D deformation. In this way, our solution achieves 3D geometry-aware deformation modeling, which enables improved dynamic view synthesis and 3D dynamic reconstruction. Extensive experimental results on both synthetic and real datasets prove the superiority of our solution, which achieves new state-of-the-art performance. The project is available at https://npucvr.github.io/GaGS/
4/16/2024
Surface Reconstruction from Gaussian Splatting via Novel Stereo Views
Yaniv Wolf, Amit Bracha, Ron Kimmel
0
0
The Gaussian splatting for radiance field rendering method has recently emerged as an efficient approach for accurate scene representation. It optimizes the location, size, color, and shape of a cloud of 3D Gaussian elements to visually match, after projection, or splatting, a set of given images taken from various viewing directions. And yet, despite the proximity of Gaussian elements to the shape boundaries, direct surface reconstruction of objects in the scene is a challenge. We propose a novel approach for surface reconstruction from Gaussian splatting models. Rather than relying on the Gaussian elements' locations as a prior for surface reconstruction, we leverage the superior novel-view synthesis capabilities of 3DGS. To that end, we use the Gaussian splatting model to render pairs of stereo-calibrated novel views from which we extract depth profiles using a stereo matching method. We then combine the extracted RGB-D images into a geometrically consistent surface. The resulting reconstruction is more accurate and shows finer details when compared to other methods for surface reconstruction from Gaussian splatting models, while requiring significantly less compute time compared to other surface reconstruction methods. We performed extensive testing of the proposed method on in-the-wild scenes, taken by a smartphone, showcasing its superior reconstruction abilities. Additionally, we tested the proposed method on the Tanks and Temples benchmark, and it has surpassed the current leading method for surface reconstruction from Gaussian splatting models. Project page: https://gs2mesh.github.io/.
4/3/2024
🗣️
GS-SLAM: Dense Visual SLAM with 3D Gaussian Splatting
Chi Yan, Delin Qu, Dan Xu, Bin Zhao, Zhigang Wang, Dong Wang, Xuelong Li
0
0
In this paper, we introduce textbf{GS-SLAM} that first utilizes 3D Gaussian representation in the Simultaneous Localization and Mapping (SLAM) system. It facilitates a better balance between efficiency and accuracy. Compared to recent SLAM methods employing neural implicit representations, our method utilizes a real-time differentiable splatting rendering pipeline that offers significant speedup to map optimization and RGB-D rendering. Specifically, we propose an adaptive expansion strategy that adds new or deletes noisy 3D Gaussians in order to efficiently reconstruct new observed scene geometry and improve the mapping of previously observed areas. This strategy is essential to extend 3D Gaussian representation to reconstruct the whole scene rather than synthesize a static object in existing methods. Moreover, in the pose tracking process, an effective coarse-to-fine technique is designed to select reliable 3D Gaussian representations to optimize camera pose, resulting in runtime reduction and robust estimation. Our method achieves competitive performance compared with existing state-of-the-art real-time methods on the Replica, TUM-RGBD datasets. Project page: https://gs-slam.github.io/.
4/9/2024