A Construct-Optimize Approach to Sparse View Synthesis without Camera Pose
2405.03659
0
0
🏋️
Abstract
Novel view synthesis from a sparse set of input images is a challenging problem of great practical interest, especially when camera poses are absent or inaccurate. Direct optimization of camera poses and usage of estimated depths in neural radiance field algorithms usually do not produce good results because of the coupling between poses and depths, and inaccuracies in monocular depth estimation. In this paper, we leverage the recent 3D Gaussian splatting method to develop a novel construct-and-optimize method for sparse view synthesis without camera poses. Specifically, we construct a solution progressively by using monocular depth and projecting pixels back into the 3D world. During construction, we optimize the solution by detecting 2D correspondences between training views and the corresponding rendered images. We develop a unified differentiable pipeline for camera registration and adjustment of both camera poses and depths, followed by back-projection. We also introduce a novel notion of an expected surface in Gaussian splatting, which is critical to our optimization. These steps enable a coarse solution, which can then be low-pass filtered and refined using standard optimization methods. We demonstrate results on the Tanks and Temples and Static Hikes datasets with as few as three widely-spaced views, showing significantly better quality than competing methods, including those with approximate camera pose information. Moreover, our results improve with more views and outperform previous InstantNGP and Gaussian Splatting algorithms even when using half the dataset.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel method for sparse view synthesis, which is the task of generating new images from a small set of input images without accurate camera poses.
- The key idea is to use monocular depth estimation and a Gaussian splatting approach to construct and optimize a 3D representation of the scene.
- The method does not require precise camera poses, which is a significant advantage over previous approaches that relied on accurate pose estimation or depth information.
Plain English Explanation
Imagine you have a handful of photos taken from different angles of a 3D scene, but you don't know the exact positions of the camera when each photo was taken. This makes it challenging to generate new images of the scene from perspectives not captured in the original photos.
The researchers in this paper developed a new technique to solve this problem. They start by estimating the depth (distance from the camera) of objects in the scene using a method called monocular depth estimation. Then, they use a technique called Gaussian splatting to construct a 3D representation of the scene by projecting the pixels from the input photos back into 3D space.
Critically, this 3D representation does not depend on having accurate camera poses (the positions and orientations of the cameras when the photos were taken). Instead, the researchers optimize the 3D model by detecting 2D correspondences between the input photos and the rendered images, adjusting both the camera poses and the depth estimates in the process.
This allows the method to produce high-quality new images of the scene, even when the camera poses are unknown or inaccurate. The researchers show that their approach outperforms previous methods, especially when only a small number of input photos are available.
Technical Explanation
The core of the researchers' approach is a construct-and-optimize method for sparse view synthesis. First, they use monocular depth estimation to obtain a coarse 3D representation of the scene by projecting pixels from the input photos back into 3D space using a Gaussian splatting technique.
This initial 3D representation is then optimized by detecting 2D correspondences between the input photos and the rendered images. The researchers develop a unified differentiable pipeline that jointly optimizes the camera poses and the depth estimates, leveraging a novel concept of an "expected surface" in the Gaussian splatting approach.
The optimized 3D representation can then be further refined using standard optimization methods, such as low-pass filtering. The researchers demonstrate that this approach outperforms previous methods, including those that use approximate camera pose information, on the Tanks and Temples and Static Hikes datasets.
Notably, the researchers also show that their method improves as more input views are added, and it outperforms previous InstantNGP and Gaussian Splatting algorithms even when using only half the dataset.
Critical Analysis
The researchers have presented a promising approach for sparse view synthesis without accurate camera poses, which is a significant challenge in the field. The key strengths of their method are the use of monocular depth estimation and a Gaussian splatting-based optimization process that can jointly optimize the camera poses and depth estimates.
However, the researchers do acknowledge some limitations of their approach. For example, they note that their method may struggle with scenes that contain fine details or highly reflective surfaces, as these can be difficult to reconstruct accurately using monocular depth estimation. Additionally, the optimization process may be sensitive to initialization and could potentially get stuck in local minima.
It would be interesting to see further research exploring ways to address these limitations, such as incorporating additional cues or constraints to improve the depth estimation or develop more robust optimization strategies. The researchers could also investigate the performance of their method on a wider range of datasets and application scenarios to better understand its strengths and weaknesses.
Overall, this paper presents a valuable contribution to the field of sparse view synthesis, demonstrating the potential of leveraging monocular depth estimation and Gaussian splatting techniques to produce high-quality novel views without requiring accurate camera poses.
Conclusion
This paper presents a novel method for sparse view synthesis that does not require accurate camera pose information. By using monocular depth estimation and a construct-and-optimize approach based on Gaussian splatting, the researchers have developed a technique that can generate high-quality new images from a small set of input photos, even when the camera positions are unknown or inaccurate.
The key innovations of this work include the use of Gaussian splatting to construct a 3D representation of the scene, the joint optimization of camera poses and depth estimates, and the introduction of the concept of an "expected surface" in the Gaussian splatting process. These advances have allowed the researchers to outperform previous methods, including those that rely on approximate camera pose information.
The researchers' work has significant practical implications, as it enables novel view synthesis in scenarios where accurate camera pose data is not available, such as in consumer photography or in applications with low-cost camera systems. Further research building on this approach could lead to even more robust and flexible tools for 3D scene reconstruction and image generation from sparse input data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
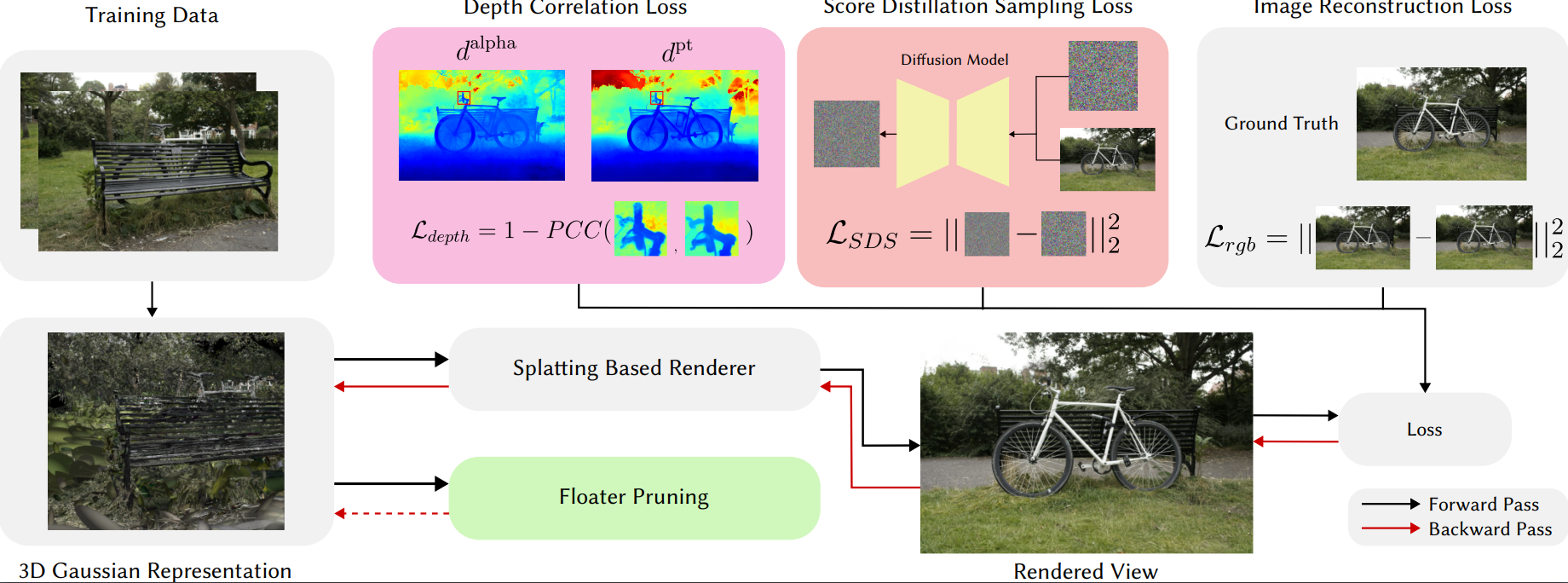
SparseGS: Real-Time 360{deg} Sparse View Synthesis using Gaussian Splatting
Haolin Xiong, Sairisheek Muttukuru, Rishi Upadhyay, Pradyumna Chari, Achuta Kadambi
0
0
The problem of novel view synthesis has grown significantly in popularity recently with the introduction of Neural Radiance Fields (NeRFs) and other implicit scene representation methods. A recent advance, 3D Gaussian Splatting (3DGS), leverages an explicit representation to achieve real-time rendering with high-quality results. However, 3DGS still requires an abundance of training views to generate a coherent scene representation. In few shot settings, similar to NeRF, 3DGS tends to overfit to training views, causing background collapse and excessive floaters, especially as the number of training views are reduced. We propose a method to enable training coherent 3DGS-based radiance fields of 360-degree scenes from sparse training views. We integrate depth priors with generative and explicit constraints to reduce background collapse, remove floaters, and enhance consistency from unseen viewpoints. Experiments show that our method outperforms base 3DGS by 6.4% in LPIPS and by 12.2% in PSNR, and NeRF-based methods by at least 17.6% in LPIPS on the MipNeRF-360 dataset with substantially less training and inference cost.
5/14/2024
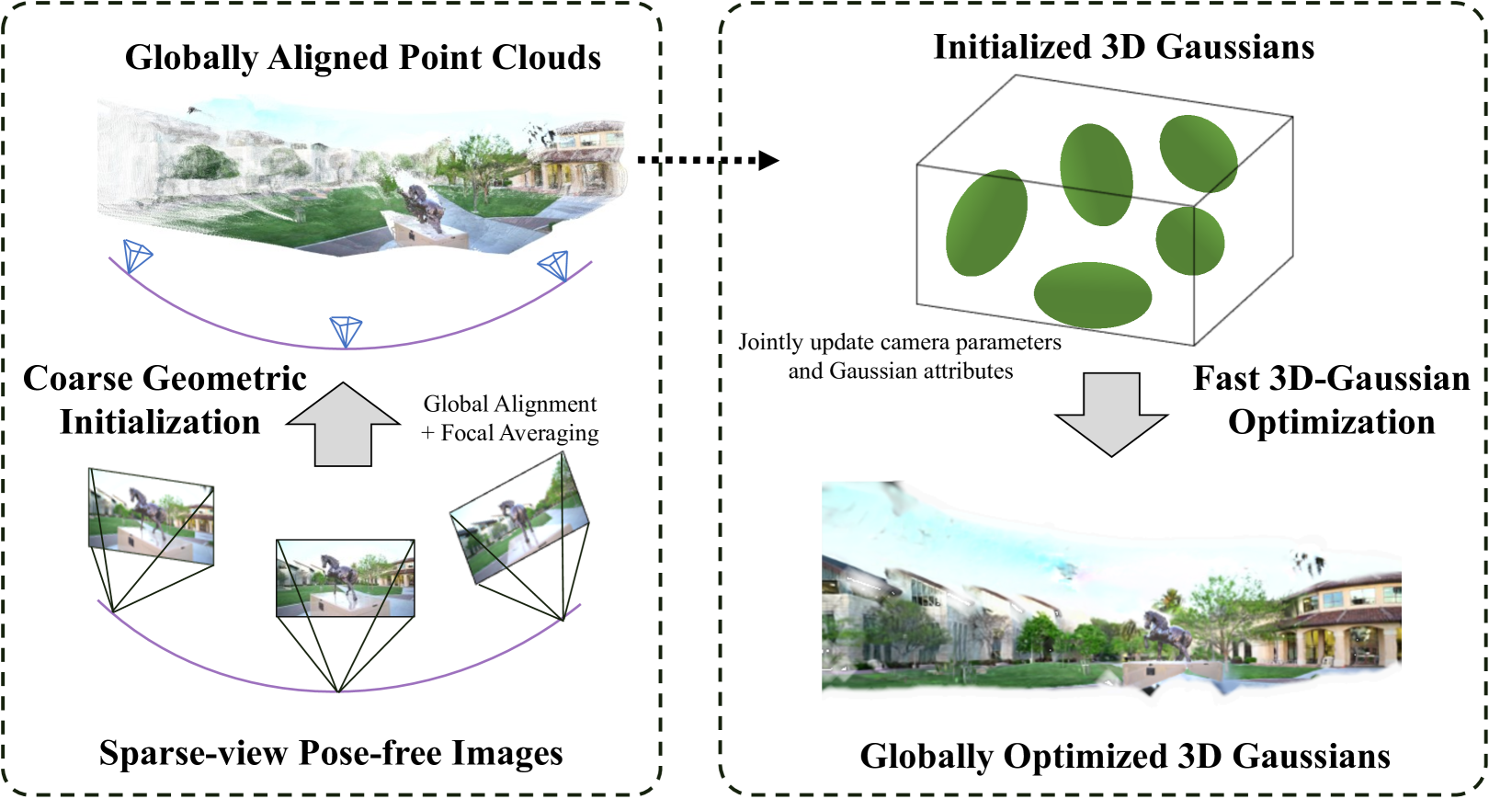
InstantSplat: Unbounded Sparse-view Pose-free Gaussian Splatting in 40 Seconds
Zhiwen Fan, Wenyan Cong, Kairun Wen, Kevin Wang, Jian Zhang, Xinghao Ding, Danfei Xu, Boris Ivanovic, Marco Pavone, Georgios Pavlakos, Zhangyang Wang, Yue Wang
0
0
While novel view synthesis (NVS) has made substantial progress in 3D computer vision, it typically requires an initial estimation of camera intrinsics and extrinsics from dense viewpoints. This pre-processing is usually conducted via a Structure-from-Motion (SfM) pipeline, a procedure that can be slow and unreliable, particularly in sparse-view scenarios with insufficient matched features for accurate reconstruction. In this work, we integrate the strengths of point-based representations (e.g., 3D Gaussian Splatting, 3D-GS) with end-to-end dense stereo models (DUSt3R) to tackle the complex yet unresolved issues in NVS under unconstrained settings, which encompasses pose-free and sparse view challenges. Our framework, InstantSplat, unifies dense stereo priors with 3D-GS to build 3D Gaussians of large-scale scenes from sparseview & pose-free images in less than 1 minute. Specifically, InstantSplat comprises a Coarse Geometric Initialization (CGI) module that swiftly establishes a preliminary scene structure and camera parameters across all training views, utilizing globally-aligned 3D point maps derived from a pre-trained dense stereo pipeline. This is followed by the Fast 3D-Gaussian Optimization (F-3DGO) module, which jointly optimizes the 3D Gaussian attributes and the initialized poses with pose regularization. Experiments conducted on the large-scale outdoor Tanks & Temples datasets demonstrate that InstantSplat significantly improves SSIM (by 32%) while concurrently reducing Absolute Trajectory Error (ATE) by 80%. These establish InstantSplat as a viable solution for scenarios involving posefree and sparse-view conditions. Project page: instantsplat.github.io.
4/1/2024
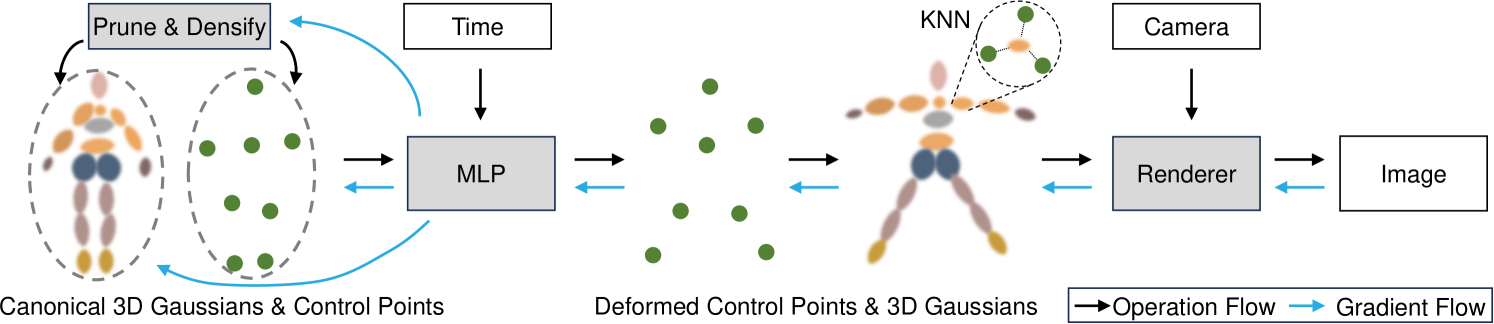
SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes
Yi-Hua Huang, Yang-Tian Sun, Ziyi Yang, Xiaoyang Lyu, Yan-Pei Cao, Xiaojuan Qi
0
0
Novel view synthesis for dynamic scenes is still a challenging problem in computer vision and graphics. Recently, Gaussian splatting has emerged as a robust technique to represent static scenes and enable high-quality and real-time novel view synthesis. Building upon this technique, we propose a new representation that explicitly decomposes the motion and appearance of dynamic scenes into sparse control points and dense Gaussians, respectively. Our key idea is to use sparse control points, significantly fewer in number than the Gaussians, to learn compact 6 DoF transformation bases, which can be locally interpolated through learned interpolation weights to yield the motion field of 3D Gaussians. We employ a deformation MLP to predict time-varying 6 DoF transformations for each control point, which reduces learning complexities, enhances learning abilities, and facilitates obtaining temporal and spatial coherent motion patterns. Then, we jointly learn the 3D Gaussians, the canonical space locations of control points, and the deformation MLP to reconstruct the appearance, geometry, and dynamics of 3D scenes. During learning, the location and number of control points are adaptively adjusted to accommodate varying motion complexities in different regions, and an ARAP loss following the principle of as rigid as possible is developed to enforce spatial continuity and local rigidity of learned motions. Finally, thanks to the explicit sparse motion representation and its decomposition from appearance, our method can enable user-controlled motion editing while retaining high-fidelity appearances. Extensive experiments demonstrate that our approach outperforms existing approaches on novel view synthesis with a high rendering speed and enables novel appearance-preserved motion editing applications. Project page: https://yihua7.github.io/SC-GS-web/
4/15/2024
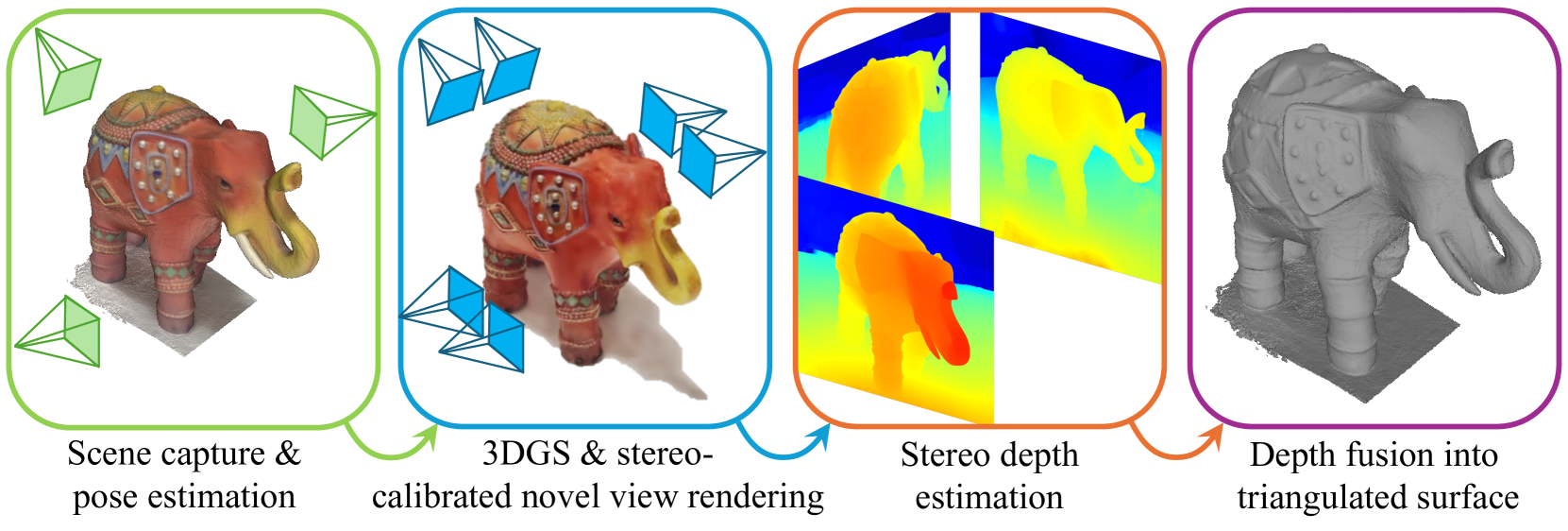
Surface Reconstruction from Gaussian Splatting via Novel Stereo Views
Yaniv Wolf, Amit Bracha, Ron Kimmel
0
0
The Gaussian splatting for radiance field rendering method has recently emerged as an efficient approach for accurate scene representation. It optimizes the location, size, color, and shape of a cloud of 3D Gaussian elements to visually match, after projection, or splatting, a set of given images taken from various viewing directions. And yet, despite the proximity of Gaussian elements to the shape boundaries, direct surface reconstruction of objects in the scene is a challenge. We propose a novel approach for surface reconstruction from Gaussian splatting models. Rather than relying on the Gaussian elements' locations as a prior for surface reconstruction, we leverage the superior novel-view synthesis capabilities of 3DGS. To that end, we use the Gaussian splatting model to render pairs of stereo-calibrated novel views from which we extract depth profiles using a stereo matching method. We then combine the extracted RGB-D images into a geometrically consistent surface. The resulting reconstruction is more accurate and shows finer details when compared to other methods for surface reconstruction from Gaussian splatting models, while requiring significantly less compute time compared to other surface reconstruction methods. We performed extensive testing of the proposed method on in-the-wild scenes, taken by a smartphone, showcasing its superior reconstruction abilities. Additionally, we tested the proposed method on the Tanks and Temples benchmark, and it has surpassed the current leading method for surface reconstruction from Gaussian splatting models. Project page: https://gs2mesh.github.io/.
4/3/2024