EffiVED:Efficient Video Editing via Text-instruction Diffusion Models

0
Sign in to get full access
Overview
• The paper introduces EffiVED, a novel text-instruction diffusion model for efficient video editing. • EffiVED allows users to edit videos by providing natural language instructions, without the need for complex video editing software or skills. • The model leverages the power of diffusion models to generate and manipulate video content based on text prompts, enabling a more intuitive and accessible video editing experience.
Plain English Explanation
The paper describes a new technology called EffiVED that makes video editing easier and more accessible for everyone. Traditional video editing can be complex and require specialized software and skills. EffiVED uses a machine learning technique called "diffusion modeling" to allow people to edit videos simply by typing instructions in plain language.
For example, with EffiVED, you could type something like "Make the person in the video jump higher and change the background to a sunny field." The system would then automatically edit the video to match your instructions, without you needing to learn complicated video editing tools.
This makes video editing much more approachable for people who don't have advanced technical skills. It could enable more creative expression and storytelling through video, as well as make it easier for businesses and individuals to produce high-quality video content. Overall, EffiVED represents an important step towards democratizing and simplifying the video editing process.
Technical Explanation
The core of EffiVED is a text-to-video diffusion model that generates and manipulates video content based on natural language instructions. The model is trained on a large dataset of video-text pairs, allowing it to learn the relationship between textual descriptions and corresponding video edits.
During inference, users provide a text prompt describing the desired edits, and the diffusion model iteratively refines the input video to match the prompt. This process leverages the powerful generative capabilities of diffusion models to synthesize new video content and seamlessly blend it with the original footage.
Key technical innovations in EffiVED include:
- A hierarchical diffusion architecture that operates at multiple spatial and temporal scales to efficiently generate high-resolution, coherent video outputs.
- Novel training and inference techniques to ensure the generated videos are visually realistic and temporally consistent.
- Strategies for effectively incorporating user feedback and iterative refinement into the editing process.
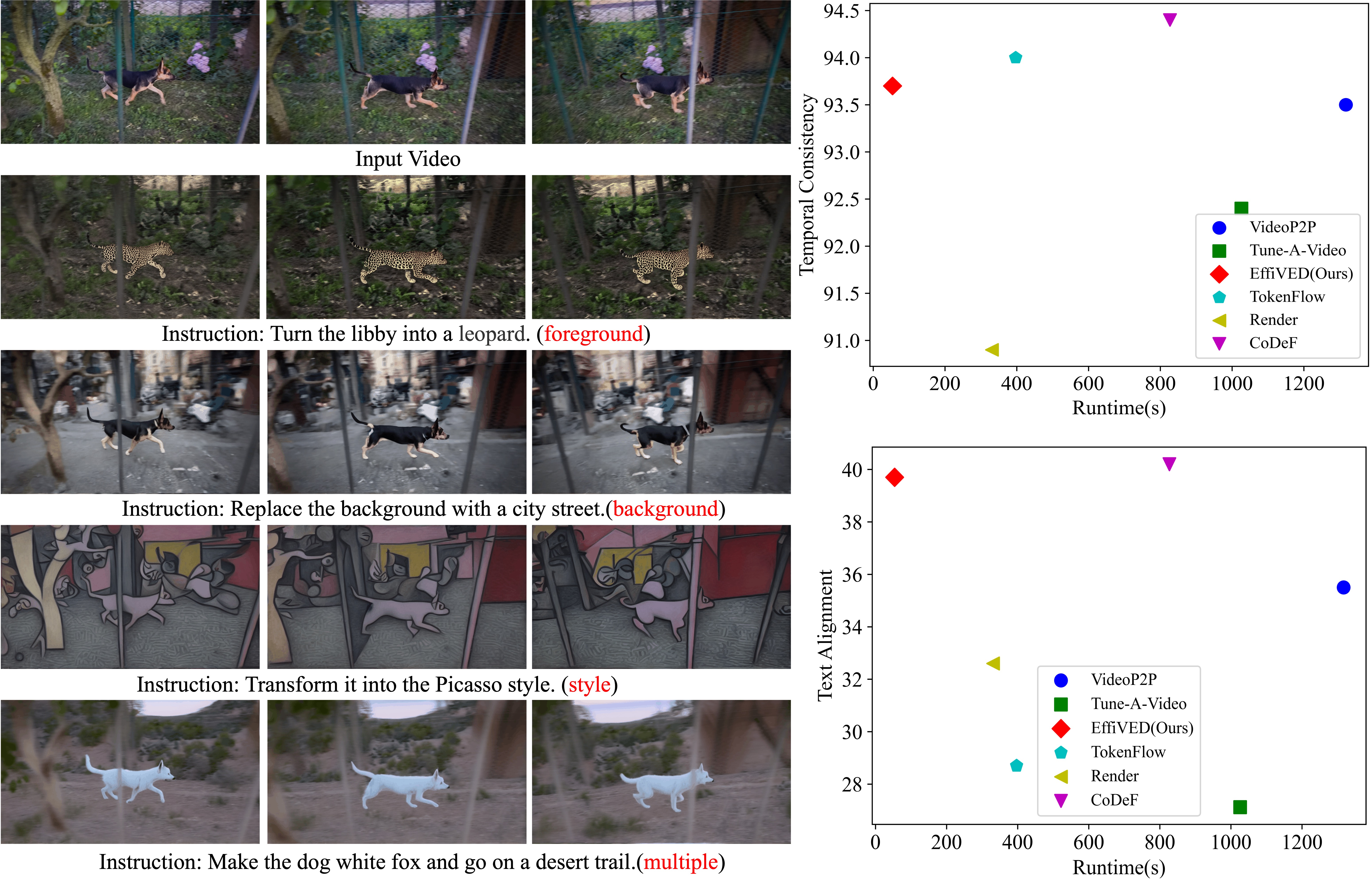
The paper presents extensive experiments demonstrating EffiVED's ability to perform a wide range of video editing tasks, from simple object insertions to complex scene transformations, all driven by natural language instructions. The model achieves state-of-the-art performance on several video editing benchmarks, showcasing its potential to revolutionize the way people create and edit video content.
Critical Analysis
The EffiVED paper presents an impressive and innovative approach to video editing, but it's important to consider some potential limitations and areas for further research:
One key challenge is ensuring the generated video outputs are always visually coherent and temporally consistent, especially for complex editing tasks. While the paper describes techniques to address these issues, there may still be room for improvement in terms of video quality and editing fidelity.
Additionally, the current EffiVED model is limited to editing pre-existing video content. Expanding the system to support the generation of entirely new video sequences from text instructions could further enhance its creative potential and real-world applicability.
Finally, as with any AI-powered system, there are potential concerns around the responsible development and deployment of EffiVED, such as ensuring fairness, transparency, and ethical use. These considerations should be carefully explored as the technology matures.
Overall, EffiVED represents an exciting step forward in making video editing more accessible and intuitive. By continuing to refine the technical capabilities and addressing potential limitations, the researchers have the opportunity to unlock new avenues for creative expression and storytelling through video.
Conclusion
The EffiVED paper introduces a novel text-instruction diffusion model for efficient video editing, which has the potential to revolutionize the way people create and manipulate video content. By leveraging the power of diffusion models, EffiVED allows users to edit videos simply by providing natural language instructions, without the need for complex video editing software or specialized skills.
The technical innovations in EffiVED, such as its hierarchical diffusion architecture and strategies for incorporating user feedback, have enabled the model to achieve state-of-the-art performance on video editing benchmarks. This breakthrough could significantly democratize the video editing process, empowering a wider range of individuals and organizations to produce high-quality video content.
As the technology continues to evolve, addressing potential limitations and exploring new avenues for creative expression will be crucial. With the right development and deployment strategies, EffiVED and similar text-to-video editing systems could become invaluable tools for content creators, businesses, and everyday users alike, transforming the way we interact with and manipulate video in the digital age.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EffiVED:Efficient Video Editing via Text-instruction Diffusion Models
Zhenghao Zhang, Zuozhuo Dai, Long Qin, Weizhi Wang
Large-scale text-to-video models have shown remarkable abilities, but their direct application in video editing remains challenging due to limited available datasets. Current video editing methods commonly require per-video fine-tuning of diffusion models or specific inversion optimization to ensure high-fidelity edits. In this paper, we introduce EffiVED, an efficient diffusion-based model that directly supports instruction-guided video editing. To achieve this, we present two efficient workflows to gather video editing pairs, utilizing augmentation and fundamental vision-language techniques. These workflows transform vast image editing datasets and open-world videos into a high-quality dataset for training EffiVED. Experimental results reveal that EffiVED not only generates high-quality editing videos but also executes rapidly. Finally, we demonstrate that our data collection method significantly improves editing performance and can potentially tackle the scarcity of video editing data. Code can be found at https://github.com/alibaba/EffiVED.
Read more6/6/2024

0
I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
Wenqi Ouyang, Yi Dong, Lei Yang, Jianlou Si, Xingang Pan
The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
Read more5/28/2024

0
Streaming Video Diffusion: Online Video Editing with Diffusion Models
Feng Chen, Zhen Yang, Bohan Zhuang, Qi Wu
We present a novel task called online video editing, which is designed to edit textbf{streaming} frames while maintaining temporal consistency. Unlike existing offline video editing assuming all frames are pre-established and accessible, online video editing is tailored to real-life applications such as live streaming and online chat, requiring (1) fast continual step inference, (2) long-term temporal modeling, and (3) zero-shot video editing capability. To solve these issues, we propose Streaming Video Diffusion (SVDiff), which incorporates the compact spatial-aware temporal recurrence into off-the-shelf Stable Diffusion and is trained with the segment-level scheme on large-scale long videos. This simple yet effective setup allows us to obtain a single model that is capable of executing a broad range of videos and editing each streaming frame with temporal coherence. Our experiments indicate that our model can edit long, high-quality videos with remarkable results, achieving a real-time inference speed of 15.2 FPS at a resolution of 512x512.
Read more5/31/2024
🌿
0
InstructVid2Vid: Controllable Video Editing with Natural Language Instructions
Bosheng Qin, Juncheng Li, Siliang Tang, Tat-Seng Chua, Yueting Zhuang
We introduce InstructVid2Vid, an end-to-end diffusion-based methodology for video editing guided by human language instructions. Our approach empowers video manipulation guided by natural language directives, eliminating the need for per-example fine-tuning or inversion. The proposed InstructVid2Vid model modifies a pretrained image generation model, Stable Diffusion, to generate a time-dependent sequence of video frames. By harnessing the collective intelligence of disparate models, we engineer a training dataset rich in video-instruction triplets, which is a more cost-efficient alternative to collecting data in real-world scenarios. To enhance the coherence between successive frames within the generated videos, we propose the Inter-Frames Consistency Loss and incorporate it during the training process. With multimodal classifier-free guidance during the inference stage, the generated videos is able to resonate with both the input video and the accompanying instructions. Experimental results demonstrate that InstructVid2Vid is capable of generating high-quality, temporally coherent videos and performing diverse edits, including attribute editing, background changes, and style transfer. These results underscore the versatility and effectiveness of our proposed method.
Read more5/30/2024