I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
2405.16537
0
1

Abstract
The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
Create account to get full access
Overview
- Presents a novel video editing technique called I2VEdit that leverages image-to-video diffusion models
- Allows users to edit videos by providing a first frame and target image, with the model generating the edited video
- Addresses the challenge of video editing, which is typically more complex than image editing due to the temporal dimension
Plain English Explanation
The paper introduces a new way to edit videos called I2VEdit. Traditionally, editing videos can be quite complicated because you have to work with multiple frames over time. However, this new technique makes it much easier.
With I2VEdit, you start by providing a single first frame of the video you want to edit. You also provide a target image that shows how you want the video to look. The model then uses a special kind of AI called an "image-to-video diffusion model" to generate the edited video for you, based on those two inputs.
This is a significant advance, as it allows users to edit videos in a much more intuitive and easy-to-use way, compared to traditional video editing tools. Instead of having to manually adjust each frame, you can simply provide a starting point and a target, and let the AI do the rest.
The key innovation here is leveraging these powerful "diffusion models" that are great at generating video from just a few inputs. This makes video editing much more accessible and user-friendly for a wide range of people.
Technical Explanation
The core innovation of the I2VEdit technique is the use of image-to-video diffusion models to enable first-frame-guided video editing. Diffusion models are a type of generative AI that can create new content from scratch or based on limited inputs.
In this case, the authors leverage a diffusion model that can take a single "first frame" of a video and a target image, and then generate the full edited video sequence. This addresses the challenge that video editing is inherently more complex than image editing due to the temporal dimension.
The researchers demonstrate that their I2VEdit approach outperforms other [zero-shot video editing techniques](https://aimodels.fyi/papers/arxiv/slicedit-zero-shot-video-editing-text-to, https://aimodels.fyi/papers/arxiv/videdit-zero-shot-spatially-aware-text-driven) in terms of both efficiency and visual quality of the edited videos. This highlights the power of diffusion models for general-purpose video generation.
Critical Analysis
One potential limitation of the I2VEdit approach is that it relies on the quality and capabilities of the underlying image-to-video diffusion model. If the diffusion model struggles with certain types of content or editing operations, this could impact the effectiveness of the I2VEdit technique.
Additionally, the paper does not explore the limits of the approach in terms of the complexity of edits that can be performed. It's possible that I2VEdit may work well for simpler edits, but struggle with more intricate or large-scale changes to a video.
Further research could investigate the robustness of I2VEdit to different types of input data, as well as expanding its capabilities to handle more sophisticated video editing tasks. Exploring ways to make the approach more interpretable and controllable for users could also be a valuable direction.
Conclusion
The I2VEdit technique presented in this paper represents an exciting advance in the field of video editing. By leveraging powerful image-to-video diffusion models, it enables a more intuitive and accessible approach to editing videos, where users can simply provide a starting frame and a target image, and let the AI handle the rest.
This has the potential to democratize video editing, making it possible for a wider range of people to create and manipulate video content. As diffusion models continue to improve, we may see even more impressive and user-friendly video editing capabilities emerge in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
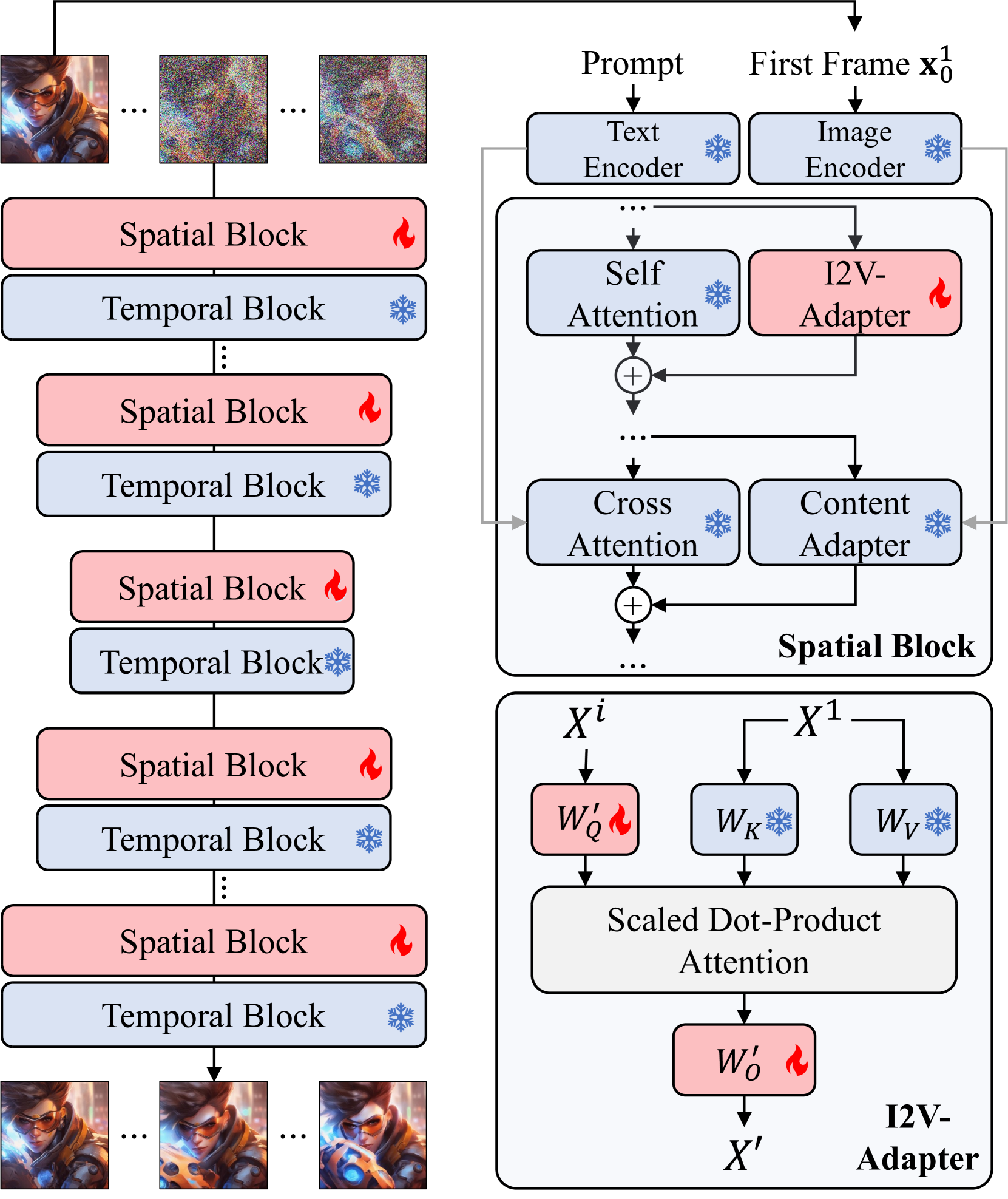
I2V-Adapter: A General Image-to-Video Adapter for Diffusion Models
Xun Guo, Mingwu Zheng, Liang Hou, Yuan Gao, Yufan Deng, Pengfei Wan, Di Zhang, Yufan Liu, Weiming Hu, Zhengjun Zha, Haibin Huang, Chongyang Ma
0
0
Text-guided image-to-video (I2V) generation aims to generate a coherent video that preserves the identity of the input image and semantically aligns with the input prompt. Existing methods typically augment pretrained text-to-video (T2V) models by either concatenating the image with noised video frames channel-wise before being fed into the model or injecting the image embedding produced by pretrained image encoders in cross-attention modules. However, the former approach often necessitates altering the fundamental weights of pretrained T2V models, thus restricting the model's compatibility within the open-source communities and disrupting the model's prior knowledge. Meanwhile, the latter typically fails to preserve the identity of the input image. We present I2V-Adapter to overcome such limitations. I2V-Adapter adeptly propagates the unnoised input image to subsequent noised frames through a cross-frame attention mechanism, maintaining the identity of the input image without any changes to the pretrained T2V model. Notably, I2V-Adapter only introduces a few trainable parameters, significantly alleviating the training cost and also ensures compatibility with existing community-driven personalized models and control tools. Moreover, we propose a novel Frame Similarity Prior to balance the motion amplitude and the stability of generated videos through two adjustable control coefficients. Our experimental results demonstrate that I2V-Adapter is capable of producing high-quality videos. This performance, coupled with its agility and adaptability, represents a substantial advancement in the field of I2V, particularly for personalized and controllable applications.
5/15/2024
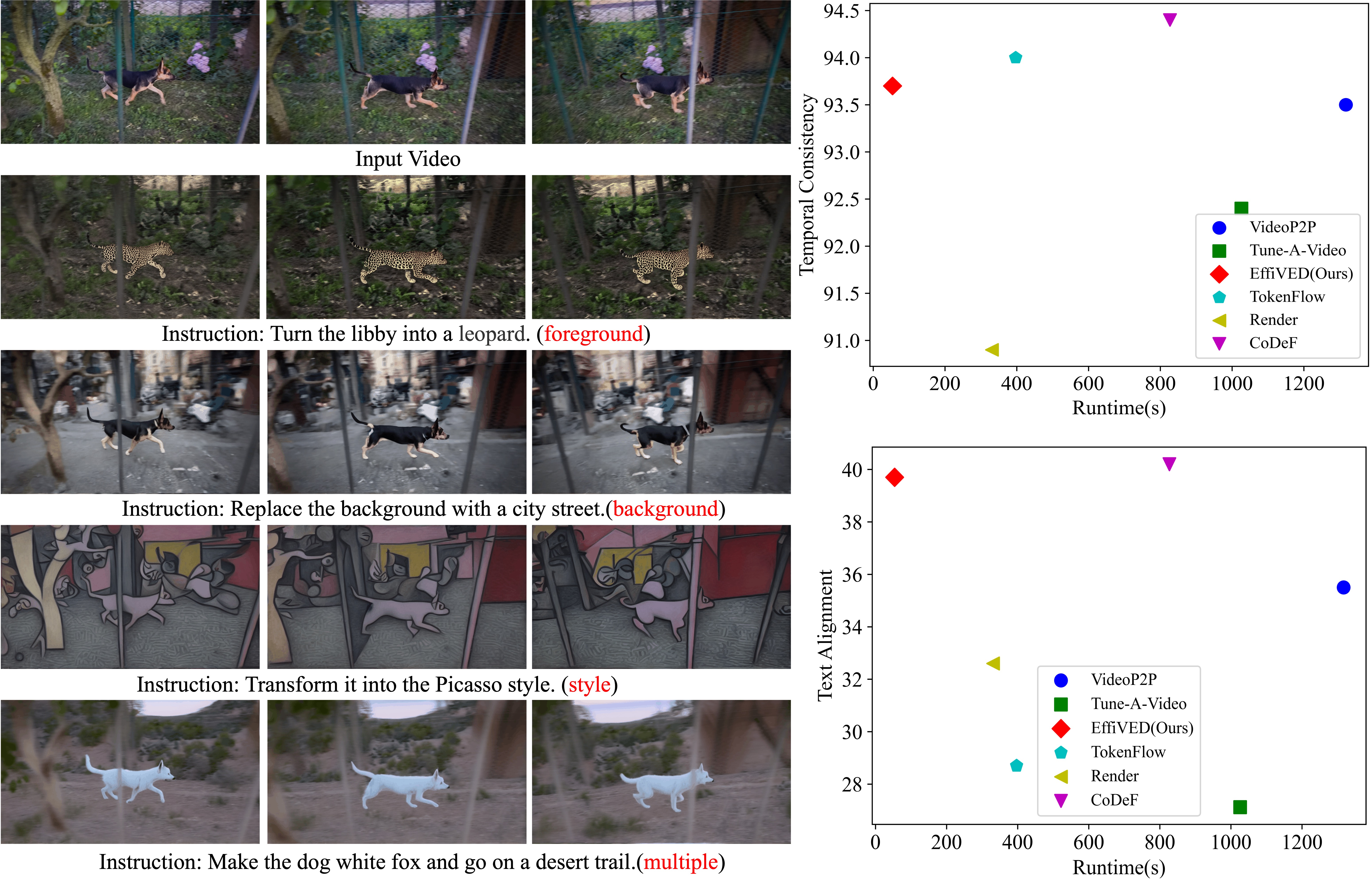
EffiVED:Efficient Video Editing via Text-instruction Diffusion Models
Zhenghao Zhang, Zuozhuo Dai, Long Qin, Weizhi Wang
0
0
Large-scale text-to-video models have shown remarkable abilities, but their direct application in video editing remains challenging due to limited available datasets. Current video editing methods commonly require per-video fine-tuning of diffusion models or specific inversion optimization to ensure high-fidelity edits. In this paper, we introduce EffiVED, an efficient diffusion-based model that directly supports instruction-guided video editing. To achieve this, we present two efficient workflows to gather video editing pairs, utilizing augmentation and fundamental vision-language techniques. These workflows transform vast image editing datasets and open-world videos into a high-quality dataset for training EffiVED. Experimental results reveal that EffiVED not only generates high-quality editing videos but also executes rapidly. Finally, we demonstrate that our data collection method significantly improves editing performance and can potentially tackle the scarcity of video editing data. Code can be found at https://github.com/alibaba/EffiVED.
6/6/2024
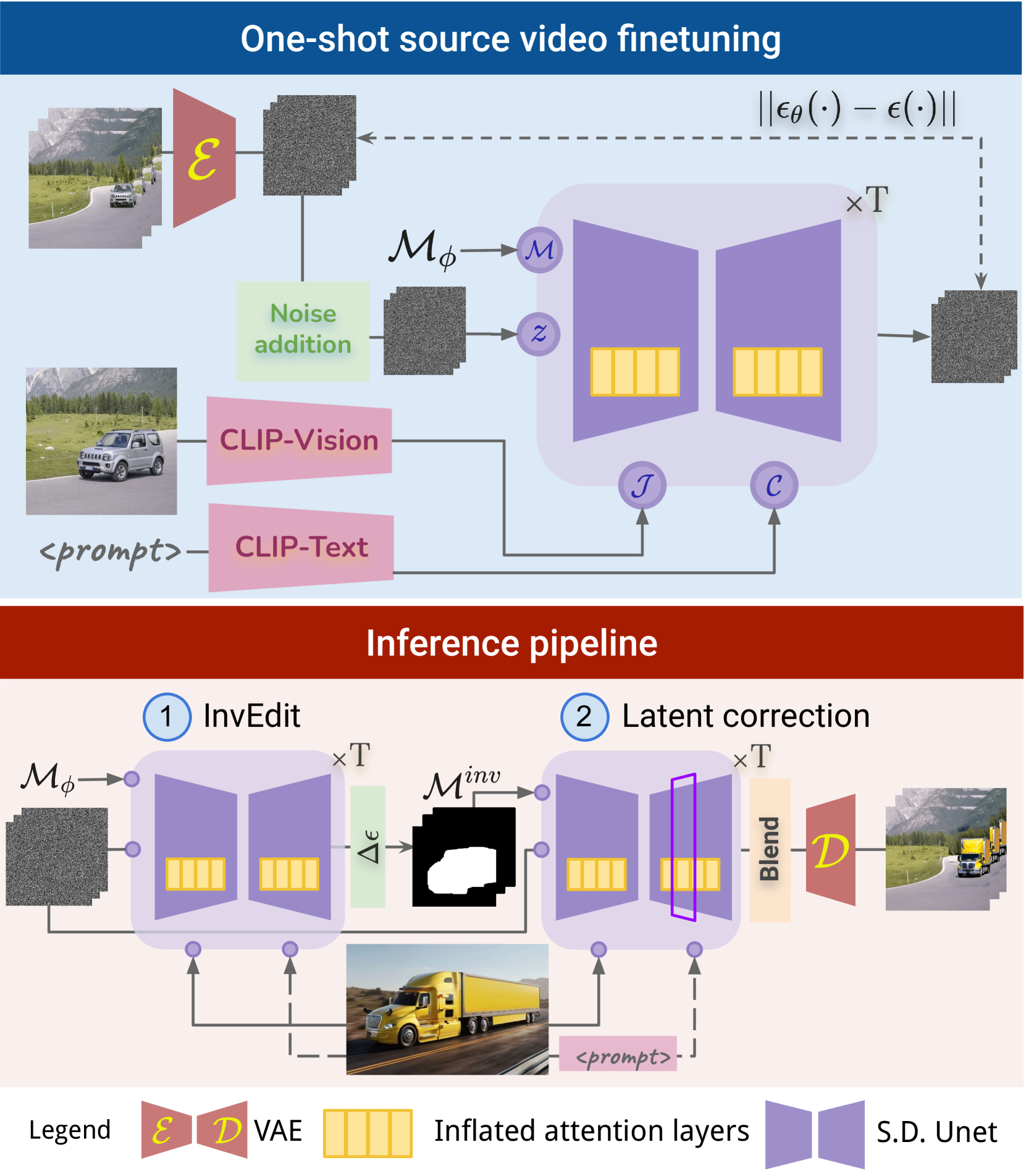
GenVideo: One-shot Target-image and Shape Aware Video Editing using T2I Diffusion Models
Sai Sree Harsha, Ambareesh Revanur, Dhwanit Agarwal, Shradha Agrawal
0
0
Video editing methods based on diffusion models that rely solely on a text prompt for the edit are hindered by the limited expressive power of text prompts. Thus, incorporating a reference target image as a visual guide becomes desirable for precise control over edit. Also, most existing methods struggle to accurately edit a video when the shape and size of the object in the target image differ from the source object. To address these challenges, we propose GenVideo for editing videos leveraging target-image aware T2I models. Our approach handles edits with target objects of varying shapes and sizes while maintaining the temporal consistency of the edit using our novel target and shape aware InvEdit masks. Further, we propose a novel target-image aware latent noise correction strategy during inference to improve the temporal consistency of the edits. Experimental analyses indicate that GenVideo can effectively handle edits with objects of varying shapes, where existing approaches fail.
4/22/2024

Slicedit: Zero-Shot Video Editing With Text-to-Image Diffusion Models Using Spatio-Temporal Slices
Nathaniel Cohen, Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, Tomer Michaeli
0
0
Text-to-image (T2I) diffusion models achieve state-of-the-art results in image synthesis and editing. However, leveraging such pretrained models for video editing is considered a major challenge. Many existing works attempt to enforce temporal consistency in the edited video through explicit correspondence mechanisms, either in pixel space or between deep features. These methods, however, struggle with strong nonrigid motion. In this paper, we introduce a fundamentally different approach, which is based on the observation that spatiotemporal slices of natural videos exhibit similar characteristics to natural images. Thus, the same T2I diffusion model that is normally used only as a prior on video frames, can also serve as a strong prior for enhancing temporal consistency by applying it on spatiotemporal slices. Based on this observation, we present Slicedit, a method for text-based video editing that utilizes a pretrained T2I diffusion model to process both spatial and spatiotemporal slices. Our method generates videos that retain the structure and motion of the original video while adhering to the target text. Through extensive experiments, we demonstrate Slicedit's ability to edit a wide range of real-world videos, confirming its clear advantages compared to existing competing methods. Webpage: https://matankleiner.github.io/slicedit/
5/21/2024