Integrated feature analysis for deep learning interpretation and class activation maps

0
Sign in to get full access
Overview
- This paper presents an integrated feature analysis technique to improve the interpretability of deep learning models and generate more informative class activation maps.
- The method combines multiple feature analysis techniques, including layer-wise relevance propagation, activation maximization, and gradient-based saliency, to provide a comprehensive understanding of the features used by the model.
- The resulting class activation maps are more detailed and informative, helping to uncover the reasoning behind the model's predictions.
Plain English Explanation
The paper describes a technique to make deep learning models more interpretable, which means helping us understand how the models arrive at their predictions. The key idea is to combine several different feature analysis methods to get a more complete picture of what the model is "looking at" when it makes a decision.
DecomCAM: Advancing Beyond Saliency Maps Through Decomposition and FM-G-CAM: A Holistic Approach to Explainable AI are two related techniques that also aim to improve the interpretability of deep learning models through feature analysis.
The authors use a combination of techniques like layer-wise relevance propagation, activation maximization, and gradient-based saliency. These methods each provide a different perspective on the features the model is focusing on. By putting these together, the resulting "class activation maps" are more detailed and informative, giving us a better understanding of the model's reasoning.
This is important because deep learning models can be very powerful, but they are also often "black boxes" - it's not always clear how they arrive at their predictions. Techniques like the one described in this paper can help make the models more transparent and trustworthy, which is crucial as they are increasingly used in high-stakes applications like healthcare and finance.
Technical Explanation
The authors propose an "Integrated Feature Analysis" (IFA) technique to enhance the interpretability of deep learning models and generate more informative class activation maps. The method combines multiple feature analysis techniques, including:
-
Layer-Wise Relevance Propagation (LRP): This method traces the relevance of each input feature back through the layers of the neural network to understand which features were most important for the model's prediction.
-
Activation Maximization: This approach finds the input that maximizes the activation of a particular neuron or feature in the model, revealing the ideal "trigger" for that feature.
-
Gradient-Based Saliency: This technique uses the gradients of the model's output with respect to the input to identify the most salient, or important, input features.
By integrating these complementary feature analysis methods, the authors aim to provide a more comprehensive understanding of the features used by the deep learning model. The resulting class activation maps highlight the most relevant regions of the input for a given prediction, helping to explain the model's reasoning.
The authors evaluate their IFA technique on several computer vision tasks, including image classification and object detection. They demonstrate that the integrated approach leads to more detailed and informative class activation maps compared to using individual feature analysis methods alone.
CAPE-CAM: Class Activation Maps as a Probabilistic Ensemble and Reliable or Deceptive? Investigating Gated Features for Smooth Saliency Maps are two other papers that explore different techniques for generating more reliable and interpretable class activation maps.
Critical Analysis
The authors present a compelling approach for enhancing the interpretability of deep learning models through integrated feature analysis. By combining multiple complementary techniques, they are able to generate more informative class activation maps that provide a richer understanding of the model's decision-making process.
One potential limitation of the study is the focus on computer vision tasks. It would be interesting to see how the IFA technique performs on other domains, such as natural language processing or time series analysis, where the feature characteristics and model architectures may differ.
Additionally, the authors mention that the integrated feature analysis can be computationally intensive, particularly for larger models. This could be a practical concern when applying the technique in real-world settings with strict latency requirements.
Further research could also explore ways to make the IFA method more efficient or to develop automated techniques for selecting the optimal combination of feature analysis methods for a given task and model architecture.
Overall, the paper presents a promising approach for enhancing the interpretability of deep learning models, which is a crucial step towards building more trustworthy and accountable AI systems.
Conclusion
The paper introduces an "Integrated Feature Analysis" (IFA) technique that combines multiple feature analysis methods to provide a more comprehensive understanding of the features used by deep learning models. By integrating techniques like layer-wise relevance propagation, activation maximization, and gradient-based saliency, the authors are able to generate more detailed and informative class activation maps.
This is an important contribution to the field of explainable AI, as it helps address the "black box" nature of deep learning models and makes their decision-making process more transparent. As deep learning continues to be applied in high-stakes domains, techniques like IFA will be crucial for building trust and accountability in these AI systems.
The authors demonstrate the effectiveness of their approach on computer vision tasks, but further research could explore its applicability to other domains and ways to optimize the computational efficiency of the method. Overall, this paper represents a significant step forward in making deep learning models more interpretable and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Integrated feature analysis for deep learning interpretation and class activation maps
Yanli Li, Tahereh Hassanzadeh, Denis P. Shamonin, Monique Reijnierse, Annette H. M. van der Helm-van Mil, Berend C. Stoel
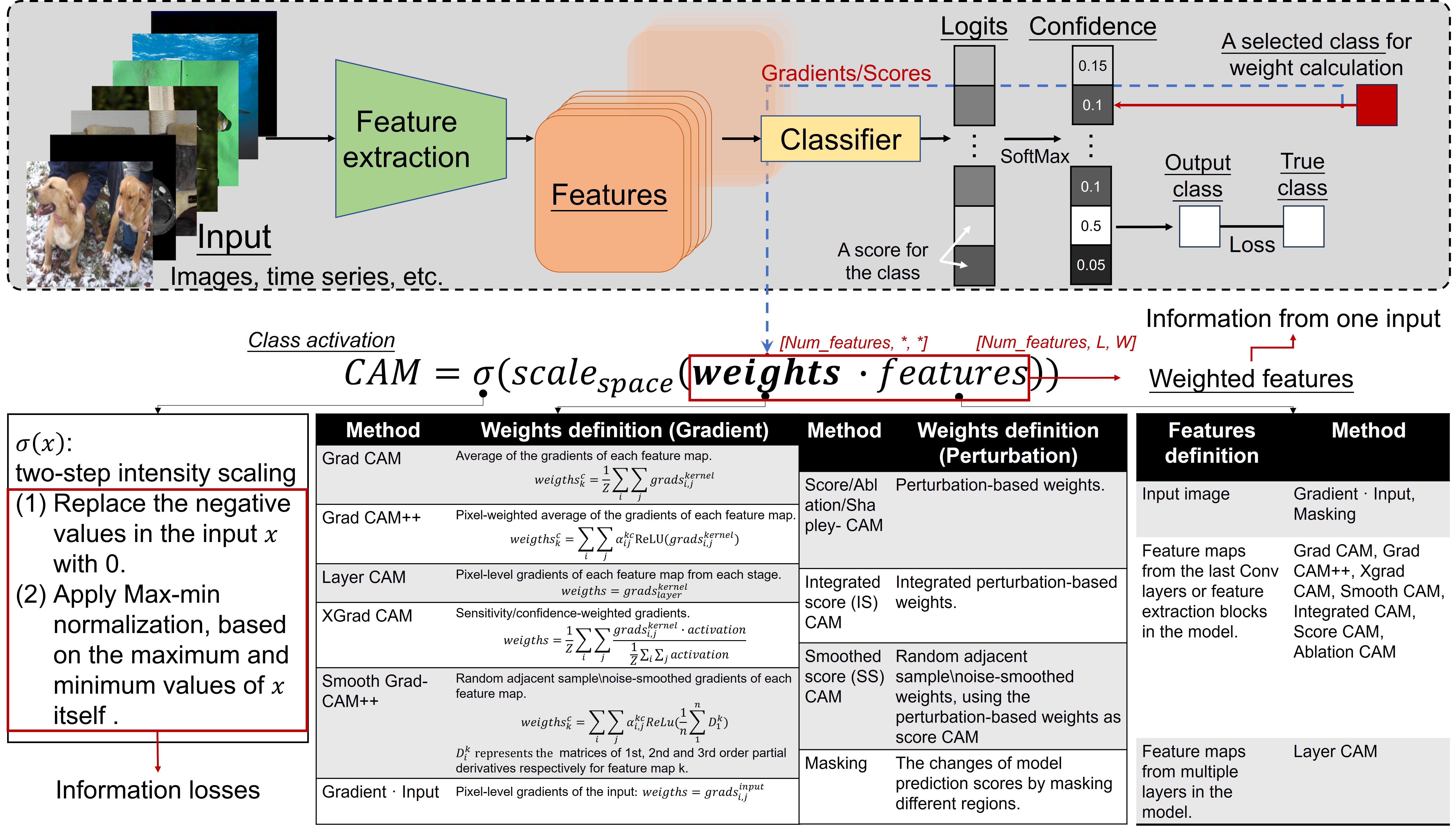
Understanding the decisions of deep learning (DL) models is essential for the acceptance of DL to risk-sensitive applications. Although methods, like class activation maps (CAMs), give a glimpse into the black box, they do miss some crucial information, thereby limiting its interpretability and merely providing the considered locations of objects. To provide more insight into the models and the influence of datasets, we propose an integrated feature analysis method, which consists of feature distribution analysis and feature decomposition, to look closer into the intermediate features extracted by DL models. This integrated feature analysis could provide information on overfitting, confounders, outliers in datasets, model redundancies and principal features extracted by the models, and provide distribution information to form a common intensity scale, which are missing in current CAM algorithms. The integrated feature analysis was applied to eight different datasets for general validation: photographs of handwritten digits, two datasets of natural images and five medical datasets, including skin photography, ultrasound, CT, X-rays and MRIs. The method was evaluated by calculating the consistency between the CAMs average class activation levels and the logits of the model. Based on the eight datasets, the correlation coefficients through our method were all very close to 100%, and based on the feature decomposition, 5%-25% of features could generate equally informative saliency maps and obtain the same model performances as using all features. This proves the reliability of the integrated feature analysis. As the proposed methods rely on very few assumptions, this is a step towards better model interpretation and a useful extension to existing CAM algorithms. Codes: https://github.com/YanliLi27/IFA
Read more7/2/2024
🗣️
0
Decom--CAM: Tell Me What You See, In Details! Feature-Level Interpretation via Decomposition Class Activation Map
Yuguang Yang, Runtang Guo, Sheng Wu, Yimi Wang, Juan Zhang, Xuan Gong, Baochang Zhang
Interpretation of deep learning remains a very challenging problem. Although the Class Activation Map (CAM) is widely used to interpret deep model predictions by highlighting object location, it fails to provide insight into the salient features used by the model to make decisions. Furthermore, existing evaluation protocols often overlook the correlation between interpretability performance and the model's decision quality, which presents a more fundamental issue. This paper proposes a new two-stage interpretability method called the Decomposition Class Activation Map (Decom-CAM), which offers a feature-level interpretation of the model's prediction. Decom-CAM decomposes intermediate activation maps into orthogonal features using singular value decomposition and generates saliency maps by integrating them. The orthogonality of features enables CAM to capture local features and can be used to pinpoint semantic components such as eyes, noses, and faces in the input image, making it more beneficial for deep model interpretation. To ensure a comprehensive comparison, we introduce a new evaluation protocol by dividing the dataset into subsets based on classification accuracy results and evaluating the interpretability performance on each subset separately. Our experiments demonstrate that the proposed Decom-CAM outperforms current state-of-the-art methods significantly by generating more precise saliency maps across all levels of classification accuracy. Combined with our feature-level interpretability approach, this paper could pave the way for a new direction for understanding the decision-making process of deep neural networks.
Read more5/30/2024

0
DecomCAM: Advancing Beyond Saliency Maps through Decomposition and Integration
Yuguang Yang, Runtang Guo, Sheng Wu, Yimi Wang, Linlin Yang, Bo Fan, Jilong Zhong, Juan Zhang, Baochang Zhang
Interpreting complex deep networks, notably pre-trained vision-language models (VLMs), is a formidable challenge. Current Class Activation Map (CAM) methods highlight regions revealing the model's decision-making basis but lack clear saliency maps and detailed interpretability. To bridge this gap, we propose DecomCAM, a novel decomposition-and-integration method that distills shared patterns from channel activation maps. Utilizing singular value decomposition, DecomCAM decomposes class-discriminative activation maps into orthogonal sub-saliency maps (OSSMs), which are then integrated together based on their contribution to the target concept. Extensive experiments on six benchmarks reveal that DecomCAM not only excels in locating accuracy but also achieves an optimizing balance between interpretability and computational efficiency. Further analysis unveils that OSSMs correlate with discernible object components, facilitating a granular understanding of the model's reasoning. This positions DecomCAM as a potential tool for fine-grained interpretation of advanced deep learning models. The code is avaible at https://github.com/CapricornGuang/DecomCAM.
Read more5/30/2024
0
FM-G-CAM: A Holistic Approach for Explainable AI in Computer Vision
Ravidu Suien Rammuni Silva, Jordan J. Bird
Explainability is an aspect of modern AI that is vital for impact and usability in the real world. The main objective of this paper is to emphasise the need to understand the predictions of Computer Vision models, specifically Convolutional Neural Network (CNN) based models. Existing methods of explaining CNN predictions are mostly based on Gradient-weighted Class Activation Maps (Grad-CAM) and solely focus on a single target class. We show that from the point of the target class selection, we make an assumption on the prediction process, hence neglecting a large portion of the predictor CNN model's thinking process. In this paper, we present an exhaustive methodology called Fused Multi-class Gradient-weighted Class Activation Map (FM-G-CAM) that considers multiple top predicted classes, which provides a holistic explanation of the predictor CNN's thinking rationale. We also provide a detailed and comprehensive mathematical and algorithmic description of our method. Furthermore, along with a concise comparison of existing methods, we compare FM-G-CAM with Grad-CAM, highlighting its benefits through real-world practical use cases. Finally, we present an open-source Python library with FM-G-CAM implementation to conveniently generate saliency maps for CNN-based model predictions.
Read more4/16/2024