Decom--CAM: Tell Me What You See, In Details! Feature-Level Interpretation via Decomposition Class Activation Map

0
🗣️
Sign in to get full access
Overview
- Interpreting deep learning models remains a challenging problem
- Existing methods like Class Activation Maps (CAM) fail to provide insight into the salient features used by the model
- Evaluation protocols often overlook the correlation between interpretability performance and model decision quality
- This paper proposes a new two-stage interpretability method called Decomposition Class Activation Map (Decom-CAM) that offers feature-level interpretation of model predictions
- Decom-CAM decomposes intermediate activation maps into orthogonal features using singular value decomposition to generate saliency maps
- The authors introduce a new evaluation protocol that assesses interpretability on subsets based on classification accuracy
Plain English Explanation
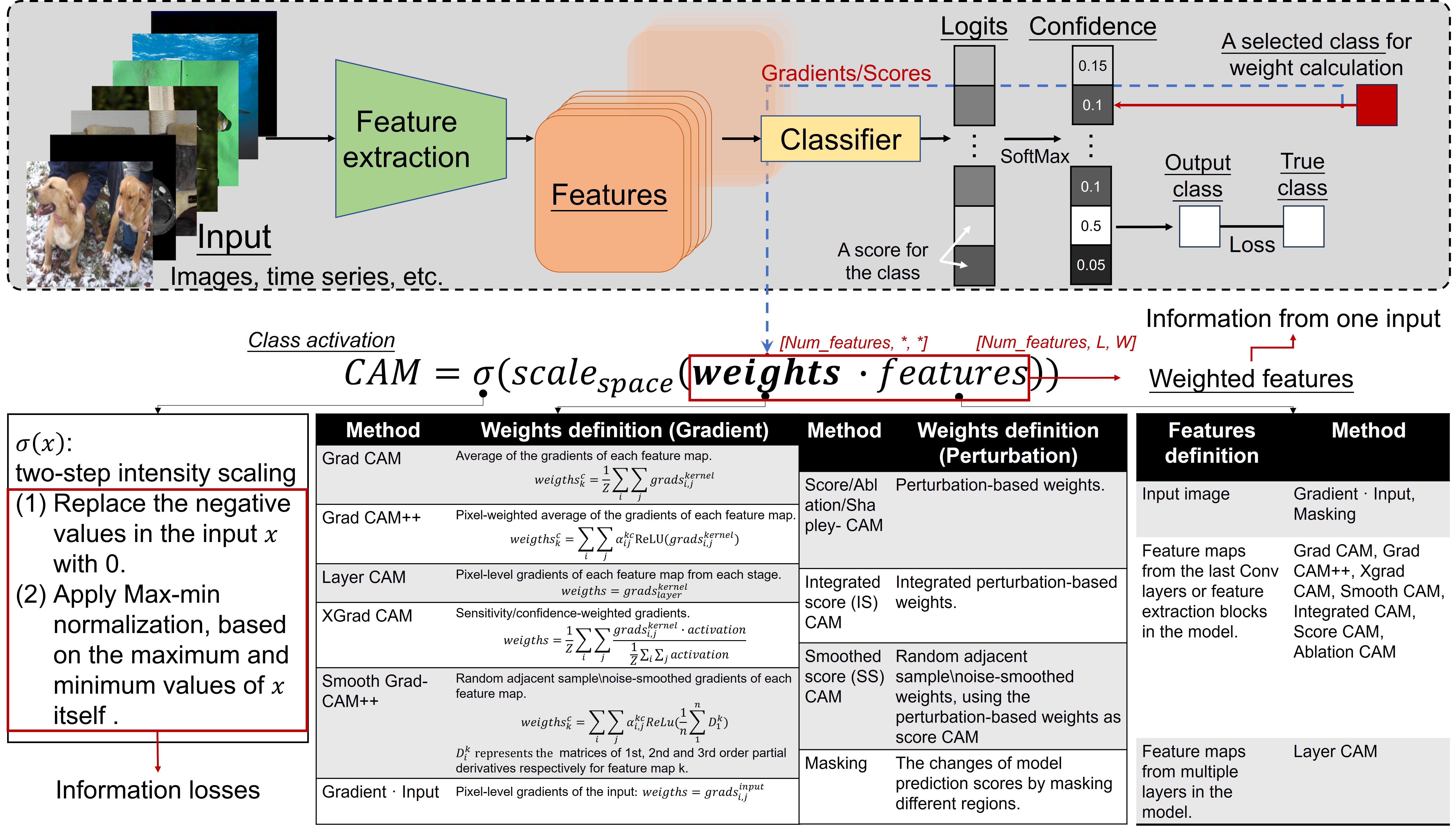
Deep learning models are powerful, but it can be difficult to understand how they make decisions. Existing methods like Class Activation Maps (CAM) can highlight where in an image a model is focusing, but they don't explain the specific features the model is using to make its prediction.
The researchers in this paper developed a new approach called Decomposition Class Activation Map (Decom-CAM) that can break down the model's decision-making process into individual features. Decom-CAM takes the intermediate activations inside the model and uses a mathematical technique called singular value decomposition to identify the key components, or features, the model is relying on.
This feature-level interpretation is more informative than just highlighting image regions. It can pinpoint semantic components like eyes, noses, and faces that the model is using to make its classification. The researchers also introduce a new way to evaluate interpretability methods, looking at how well they perform across different levels of model accuracy.
Through their experiments, the authors show that Decom-CAM outperforms existing approaches, generating more precise saliency maps across all accuracy levels. This work could lead to better ways of understanding and explaining the inner workings of deep neural networks.
Technical Explanation
The paper proposes a new two-stage interpretability method called Decomposition Class Activation Map (Decom-CAM) that provides feature-level interpretation of deep model predictions.
In the first stage, Decom-CAM decomposes the intermediate activation maps inside the model using singular value decomposition (SVD). This allows the method to identify the key orthogonal features the model is using to make its decision.
In the second stage, Decom-CAM generates saliency maps by integrating these orthogonal features. The orthogonality of the features enables the method to capture local semantic components like eyes, noses, and faces in the input image, providing more detailed insights compared to existing approaches like CAM.
To thoroughly evaluate interpretability performance, the authors introduce a new protocol that divides the dataset into subsets based on the model's classification accuracy. This allows them to assess how well the interpretability methods perform at different accuracy levels, addressing the issue that existing protocols often overlook the correlation between interpretability and decision quality.
The experimental results demonstrate that Decom-CAM significantly outperforms state-of-the-art methods like FM-G-CAM, Reliable or Deceptive, and LLM-based Hierarchical Concept Decomposition in generating precise saliency maps across all accuracy levels.
Critical Analysis
The paper presents a novel and promising approach to interpreting deep learning models, but there are a few potential limitations and areas for further research:
-
Generalizability: The experiments in the paper focus on image classification tasks, so it's unclear how well Decom-CAM would perform on other types of deep learning problems, such as natural language processing or reinforcement learning.
-
Computational Complexity: The singular value decomposition step in Decom-CAM may add computational overhead, especially for larger models or higher-resolution images. The authors should investigate ways to improve the efficiency of the method.
-
Robustness: The paper does not explore how Decom-CAM's interpretability performance might be affected by common challenges in deep learning, such as adversarial examples or dataset bias. Evaluating the method's robustness in these scenarios would be an important next step.
-
User Studies: While the paper introduces a new evaluation protocol based on classification accuracy, it would also be valuable to conduct user studies to understand how human experts interpret the saliency maps generated by Decom-CAM and other interpretability methods.
Overall, the Decomposition Class Activation Map (Decom-CAM) approach represents an important advancement in the field of deep learning interpretability. By providing feature-level insights, it has the potential to help researchers and practitioners better understand the decision-making process of deep neural networks.
Conclusion
This paper proposes a new interpretability method called Decomposition Class Activation Map (Decom-CAM) that can provide detailed, feature-level explanations of deep model predictions. By decomposing intermediate activations into orthogonal features using singular value decomposition, Decom-CAM generates saliency maps that can pinpoint semantic components in the input.
The authors also introduce a novel evaluation protocol that assesses interpretability performance across different levels of model accuracy, addressing a key limitation of existing protocols. Experimental results show that Decom-CAM significantly outperforms state-of-the-art interpretability methods, suggesting it could be a valuable tool for understanding the decision-making process of deep neural networks.
While the paper presents a promising approach, there are still opportunities for further research to explore the method's generalizability, computational complexity, robustness, and human interpretability. Overall, this work represents an important step forward in the field of deep learning interpretability and could pave the way for more transparent and explainable artificial intelligence systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Decom--CAM: Tell Me What You See, In Details! Feature-Level Interpretation via Decomposition Class Activation Map
Yuguang Yang, Runtang Guo, Sheng Wu, Yimi Wang, Juan Zhang, Xuan Gong, Baochang Zhang
Interpretation of deep learning remains a very challenging problem. Although the Class Activation Map (CAM) is widely used to interpret deep model predictions by highlighting object location, it fails to provide insight into the salient features used by the model to make decisions. Furthermore, existing evaluation protocols often overlook the correlation between interpretability performance and the model's decision quality, which presents a more fundamental issue. This paper proposes a new two-stage interpretability method called the Decomposition Class Activation Map (Decom-CAM), which offers a feature-level interpretation of the model's prediction. Decom-CAM decomposes intermediate activation maps into orthogonal features using singular value decomposition and generates saliency maps by integrating them. The orthogonality of features enables CAM to capture local features and can be used to pinpoint semantic components such as eyes, noses, and faces in the input image, making it more beneficial for deep model interpretation. To ensure a comprehensive comparison, we introduce a new evaluation protocol by dividing the dataset into subsets based on classification accuracy results and evaluating the interpretability performance on each subset separately. Our experiments demonstrate that the proposed Decom-CAM outperforms current state-of-the-art methods significantly by generating more precise saliency maps across all levels of classification accuracy. Combined with our feature-level interpretability approach, this paper could pave the way for a new direction for understanding the decision-making process of deep neural networks.
Read more5/30/2024

0
DecomCAM: Advancing Beyond Saliency Maps through Decomposition and Integration
Yuguang Yang, Runtang Guo, Sheng Wu, Yimi Wang, Linlin Yang, Bo Fan, Jilong Zhong, Juan Zhang, Baochang Zhang
Interpreting complex deep networks, notably pre-trained vision-language models (VLMs), is a formidable challenge. Current Class Activation Map (CAM) methods highlight regions revealing the model's decision-making basis but lack clear saliency maps and detailed interpretability. To bridge this gap, we propose DecomCAM, a novel decomposition-and-integration method that distills shared patterns from channel activation maps. Utilizing singular value decomposition, DecomCAM decomposes class-discriminative activation maps into orthogonal sub-saliency maps (OSSMs), which are then integrated together based on their contribution to the target concept. Extensive experiments on six benchmarks reveal that DecomCAM not only excels in locating accuracy but also achieves an optimizing balance between interpretability and computational efficiency. Further analysis unveils that OSSMs correlate with discernible object components, facilitating a granular understanding of the model's reasoning. This positions DecomCAM as a potential tool for fine-grained interpretation of advanced deep learning models. The code is avaible at https://github.com/CapricornGuang/DecomCAM.
Read more5/30/2024
0
Integrated feature analysis for deep learning interpretation and class activation maps
Yanli Li, Tahereh Hassanzadeh, Denis P. Shamonin, Monique Reijnierse, Annette H. M. van der Helm-van Mil, Berend C. Stoel
Understanding the decisions of deep learning (DL) models is essential for the acceptance of DL to risk-sensitive applications. Although methods, like class activation maps (CAMs), give a glimpse into the black box, they do miss some crucial information, thereby limiting its interpretability and merely providing the considered locations of objects. To provide more insight into the models and the influence of datasets, we propose an integrated feature analysis method, which consists of feature distribution analysis and feature decomposition, to look closer into the intermediate features extracted by DL models. This integrated feature analysis could provide information on overfitting, confounders, outliers in datasets, model redundancies and principal features extracted by the models, and provide distribution information to form a common intensity scale, which are missing in current CAM algorithms. The integrated feature analysis was applied to eight different datasets for general validation: photographs of handwritten digits, two datasets of natural images and five medical datasets, including skin photography, ultrasound, CT, X-rays and MRIs. The method was evaluated by calculating the consistency between the CAMs average class activation levels and the logits of the model. Based on the eight datasets, the correlation coefficients through our method were all very close to 100%, and based on the feature decomposition, 5%-25% of features could generate equally informative saliency maps and obtain the same model performances as using all features. This proves the reliability of the integrated feature analysis. As the proposed methods rely on very few assumptions, this is a step towards better model interpretation and a useful extension to existing CAM algorithms. Codes: https://github.com/YanliLi27/IFA
Read more7/2/2024
🏷️
0
Opti-CAM: Optimizing saliency maps for interpretability
Hanwei Zhang, Felipe Torres, Ronan Sicre, Yannis Avrithis, Stephane Ayache
Methods based on class activation maps (CAM) provide a simple mechanism to interpret predictions of convolutional neural networks by using linear combinations of feature maps as saliency maps. By contrast, masking-based methods optimize a saliency map directly in the image space or learn it by training another network on additional data. In this work we introduce Opti-CAM, combining ideas from CAM-based and masking-based approaches. Our saliency map is a linear combination of feature maps, where weights are optimized per image such that the logit of the masked image for a given class is maximized. We also fix a fundamental flaw in two of the most common evaluation metrics of attribution methods. On several datasets, Opti-CAM largely outperforms other CAM-based approaches according to the most relevant classification metrics. We provide empirical evidence supporting that localization and classifier interpretability are not necessarily aligned.
Read more4/8/2024