Harnessing Knowledge Retrieval with Large Language Models for Clinical Report Error Correction

0
Sign in to get full access
Overview
- This paper explores the use of large language models (LLMs) to assist in correcting errors in clinical reports.
- The researchers developed a system that retrieves relevant medical knowledge from LLMs to help identify and fix errors in clinical documentation.
- The proposed approach aims to improve the accuracy and quality of medical reports, which is crucial for patient care and clinical decision-making.
Plain English Explanation
The paper looks at how we can use powerful language models, known as large language models (LLMs), to help fix mistakes in medical reports. These reports are important because they contain information about patients that doctors and nurses use to make decisions about their care.
The researchers created a system that can pull relevant medical knowledge from LLMs and use that information to identify and correct errors in clinical documentation. For example, if a report states a patient has a certain condition, but the LLM knows that's not accurate based on the patient's symptoms and test results, the system can flag the error and suggest a correction.
This is an important task because accurate clinical reports are essential for providing high-quality patient care. Errors in these reports can lead to misdiagnoses, inappropriate treatments, or other problems. By using powerful language models to help catch and fix these mistakes, the researchers hope to improve the overall quality and reliability of medical documentation.
Technical Explanation
The paper presents a system that leverages retrieval-augmented generation (RAG) techniques to harness the knowledge stored in large language models (LLMs) for the task of clinical report error correction.
The proposed approach consists of two key components:
-
Knowledge Retrieval Module: This module uses a RAG-based model to retrieve relevant medical knowledge from an LLM based on the content of the clinical report. The retrieved information can help identify potential errors or inconsistencies in the report.
-
Error Correction Module: This module takes the original report and the retrieved knowledge to generate a corrected version of the report. The researchers experimented with different language model architectures, including BiomedRAG, to optimize the error correction performance.
The researchers evaluated their system on a dataset of real-world clinical reports, measuring its ability to correctly identify and fix various types of errors, such as factual mistakes, inconsistencies, and missing information. The results demonstrated the effectiveness of the proposed approach in enhancing the accuracy and quality of clinical documentation.
Critical Analysis
The paper presents a promising approach to leveraging LLMs for clinical report error correction, which is an important and practical problem in the healthcare domain. The use of retrieval-augmented generation techniques to incorporate external medical knowledge is a key strength of the proposed system.
However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the system. For example, it would be valuable to understand the types of errors the system struggles with, the impact of the size and quality of the underlying knowledge base, and any potential biases or errors introduced by the LLMs.
Additionally, while the researchers demonstrate the system's effectiveness on a dataset of real-world clinical reports, it would be helpful to see further validation on a larger and more diverse set of reports to assess the generalizability of the approach.
Future research could also explore ways to make the error correction process more transparent and interpretable, allowing clinicians to better understand the reasoning behind the suggested corrections and have more confidence in the system's outputs.
Conclusion
This paper presents a novel approach to leveraging large language models and retrieval-augmented generation techniques to improve the accuracy and quality of clinical documentation. By harnessing medical knowledge stored in LLMs, the proposed system can effectively identify and correct various types of errors in clinical reports.
The successful implementation of this technology could have a significant impact on patient care, as accurate and reliable clinical reports are crucial for making informed medical decisions. The researchers have demonstrated the potential of this approach, and further development and validation could lead to valuable tools for healthcare professionals.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Harnessing Knowledge Retrieval with Large Language Models for Clinical Report Error Correction
Jinge Wu, Zhaolong Wu, Ruizhe Li, Abul Hasan, Yunsoo Kim, Jason P. Y. Cheung, Teng Zhang, Honghan Wu
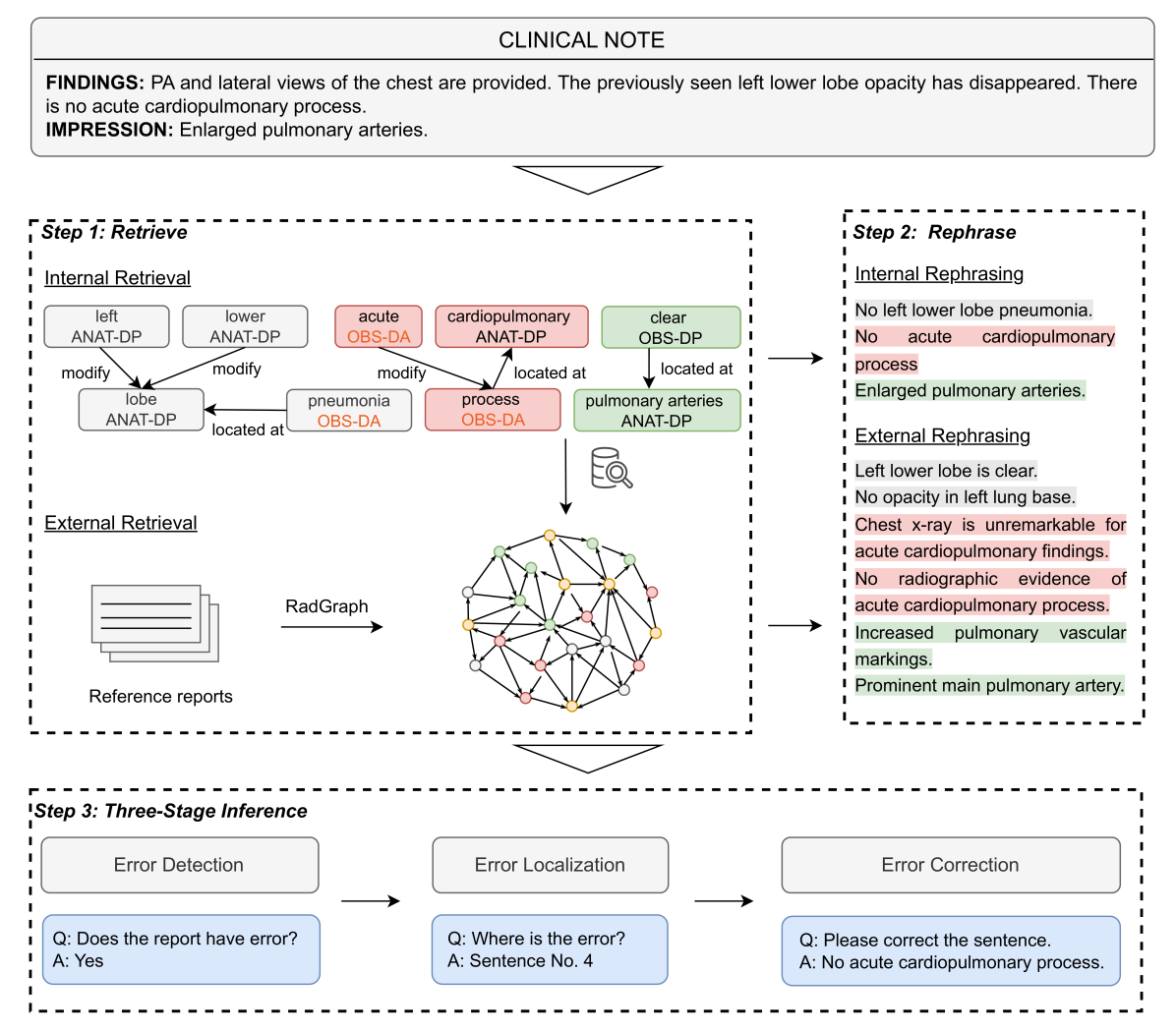
This study proposes an approach for error correction in radiology reports, leveraging large language models (LLMs) and retrieval-augmented generation (RAG) techniques. The proposed framework employs a novel internal+external retrieval mechanism to extract relevant medical entities and relations from the report of interest and an external knowledge source. A three-stage inference process is introduced, decomposing the task into error detection, localization, and correction subtasks, which enhances the explainability and performance of the system. The effectiveness of the approach is evaluated using a benchmark dataset created by corrupting real-world radiology reports with realistic errors, guided by domain experts. Experimental results demonstrate the benefits of the proposed methods, with the combination of internal and external retrieval significantly improving the accuracy of error detection, localization, and correction across various state-of-the-art LLMs. The findings contribute to the development of more robust and reliable error correction systems for clinical documentation.
Read more9/19/2024
0
Tool Calling: Enhancing Medication Consultation via Retrieval-Augmented Large Language Models
Zhongzhen Huang, Kui Xue, Yongqi Fan, Linjie Mu, Ruoyu Liu, Tong Ruan, Shaoting Zhang, Xiaofan Zhang
Large-scale language models (LLMs) have achieved remarkable success across various language tasks but suffer from hallucinations and temporal misalignment. To mitigate these shortcomings, Retrieval-augmented generation (RAG) has been utilized to provide external knowledge to facilitate the answer generation. However, applying such models to the medical domain faces several challenges due to the lack of domain-specific knowledge and the intricacy of real-world scenarios. In this study, we explore LLMs with RAG framework for knowledge-intensive tasks in the medical field. To evaluate the capabilities of LLMs, we introduce MedicineQA, a multi-round dialogue benchmark that simulates the real-world medication consultation scenario and requires LLMs to answer with retrieved evidence from the medicine database. MedicineQA contains 300 multi-round question-answering pairs, each embedded within a detailed dialogue history, highlighting the challenge posed by this knowledge-intensive task to current LLMs. We further propose a new textit{Distill-Retrieve-Read} framework instead of the previous textit{Retrieve-then-Read}. Specifically, the distillation and retrieval process utilizes a tool calling mechanism to formulate search queries that emulate the keyword-based inquiries used by search engines. With experimental results, we show that our framework brings notable performance improvements and surpasses the previous counterparts in the evidence retrieval process in terms of evidence retrieval accuracy. This advancement sheds light on applying RAG to the medical domain.
Read more4/30/2024
💬
0
New!Language Models and Retrieval Augmented Generation for Automated Structured Data Extraction from Diagnostic Reports
Mohamed Sobhi Jabal, Pranav Warman, Jikai Zhang, Kartikeye Gupta, Ayush Jain, Maciej Mazurowski, Walter Wiggins, Kirti Magudia, Evan Calabrese
Purpose: To develop and evaluate an automated system for extracting structured clinical information from unstructured radiology and pathology reports using open-weights large language models (LMs) and retrieval augmented generation (RAG), and to assess the effects of model configuration variables on extraction performance. Methods and Materials: The study utilized two datasets: 7,294 radiology reports annotated for Brain Tumor Reporting and Data System (BT-RADS) scores and 2,154 pathology reports annotated for isocitrate dehydrogenase (IDH) mutation status. An automated pipeline was developed to benchmark the performance of various LMs and RAG configurations. The impact of model size, quantization, prompting strategies, output formatting, and inference parameters was systematically evaluated. Results: The best performing models achieved over 98% accuracy in extracting BT-RADS scores from radiology reports and over 90% for IDH mutation status extraction from pathology reports. The top model being medical fine-tuned llama3. Larger, newer, and domain fine-tuned models consistently outperformed older and smaller models. Model quantization had minimal impact on performance. Few-shot prompting significantly improved accuracy. RAG improved performance for complex pathology reports but not for shorter radiology reports. Conclusions: Open LMs demonstrate significant potential for automated extraction of structured clinical data from unstructured clinical reports with local privacy-preserving application. Careful model selection, prompt engineering, and semi-automated optimization using annotated data are critical for optimal performance. These approaches could be reliable enough for practical use in research workflows, highlighting the potential for human-machine collaboration in healthcare data extraction.
Read more9/19/2024
💬
0
RadioRAG: Factual Large Language Models for Enhanced Diagnostics in Radiology Using Dynamic Retrieval Augmented Generation
Soroosh Tayebi Arasteh, Mahshad Lotfinia, Keno Bressem, Robert Siepmann, Dyke Ferber, Christiane Kuhl, Jakob Nikolas Kather, Sven Nebelung, Daniel Truhn
Large language models (LLMs) have advanced the field of artificial intelligence (AI) in medicine. However LLMs often generate outdated or inaccurate information based on static training datasets. Retrieval augmented generation (RAG) mitigates this by integrating outside data sources. While previous RAG systems used pre-assembled, fixed databases with limited flexibility, we have developed Radiology RAG (RadioRAG) as an end-to-end framework that retrieves data from authoritative radiologic online sources in real-time. RadioRAG is evaluated using a dedicated radiologic question-and-answer dataset (RadioQA). We evaluate the diagnostic accuracy of various LLMs when answering radiology-specific questions with and without access to additional online information via RAG. Using 80 questions from RSNA Case Collection across radiologic subspecialties and 24 additional expert-curated questions, for which the correct gold-standard answers were available, LLMs (GPT-3.5-turbo, GPT-4, Mistral-7B, Mixtral-8x7B, and Llama3 [8B and 70B]) were prompted with and without RadioRAG. RadioRAG retrieved context-specific information from www.radiopaedia.org in real-time and incorporated them into its reply. RadioRAG consistently improved diagnostic accuracy across all LLMs, with relative improvements ranging from 2% to 54%. It matched or exceeded question answering without RAG across radiologic subspecialties, particularly in breast imaging and emergency radiology. However, degree of improvement varied among models; GPT-3.5-turbo and Mixtral-8x7B-instruct-v0.1 saw notable gains, while Mistral-7B-instruct-v0.2 showed no improvement, highlighting variability in its effectiveness. LLMs benefit when provided access to domain-specific data beyond their training data. For radiology, RadioRAG establishes a robust framework that substantially improves diagnostic accuracy and factuality in radiological question answering.
Read more7/23/2024