Inter-Series Transformer: Attending to Products in Time Series Forecasting

0
🔮
Sign in to get full access
Overview
- This paper presents a new approach for modeling and forecasting time series data.
- The proposed method addresses the challenges of capturing both inter-series and intra-series relationships in time series data.
- The research introduces a novel neural network architecture and training strategy to effectively model these complex temporal dependencies.
- Experiments on real-world datasets demonstrate the superior performance of the proposed method compared to existing time series forecasting techniques.
Plain English Explanation
The paper tackles the problem of forecasting time series data, which is data that changes over time, such as stock prices, weather patterns, or product sales. Accurately predicting future values in time series data is challenging because there can be complex relationships both within a single time series (intra-series) and between multiple time series (inter-series).
The researchers developed a new neural network architecture and training approach to better capture these intricate temporal dependencies. The key idea is to use a specialized network structure and learning strategy that can simultaneously model the unique patterns within each time series as well as the interactions between related time series.
By leveraging 2D information in the time series data, the proposed method is able to outperform existing forecasting techniques on real-world datasets. This means the new approach is better at predicting future values compared to other state-of-the-art time series models.
Technical Explanation
The paper introduces a novel neural network architecture called "UnitST" that is designed to effectively model both inter-series and intra-series relationships in time series data.
The key components of UnitST include:
- A Transformer-based encoder that captures inter-series dependencies
- A series-specific recurrent module that models intra-series patterns
- A novel training strategy that jointly optimizes the encoder and recurrent components
Through extensive experiments on diverse time series datasets, the authors demonstrate that UnitST outperforms state-of-the-art time series forecasting methods, including those that leverage 2D information or use multiple resolution tokenization.
Critical Analysis
The paper provides a thorough evaluation of the proposed UnitST model, including comparisons to a wide range of baselines on multiple real-world time series datasets. This gives confidence in the robustness and generalizability of the results.
However, the paper does not discuss potential limitations or caveats of the UnitST approach. For example, it's unclear how the method would perform on time series with abrupt changes or irregular patterns, or how sensitive the model is to hyperparameter settings.
Additionally, while the authors claim their approach outperforms existing methods, the magnitude of the performance improvements is not always clearly quantified. Further analysis of the statistical significance and practical relevance of the reported gains would strengthen the conclusions.
Overall, the research represents a valuable contribution to the field of time series forecasting, but additional investigation into the model's limitations and edge cases would help provide a more comprehensive understanding of its strengths and weaknesses.
Conclusion
This paper presents a novel neural network architecture called UnitST that can effectively model both inter-series and intra-series relationships in time series data. Through rigorous experimentation, the authors demonstrate that UnitST outperforms state-of-the-art time series forecasting methods on a variety of real-world datasets.
The proposed approach represents an important advance in the field, as it addresses a key challenge in time series modeling - capturing the complex dependencies both within and across individual time series. The superior performance of UnitST suggests it could have significant practical implications for applications that rely on accurate time series forecasting, such as supply chain management or financial planning.
While the paper provides a solid technical foundation, further research is needed to fully understand the limitations and edge cases of the UnitST model. Nevertheless, this work marks an important step forward in the development of advanced time series forecasting techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Inter-Series Transformer: Attending to Products in Time Series Forecasting
Rares Cristian, Pavithra Harsha, Clemente Ocejo, Georgia Perakis, Brian Quanz, Ioannis Spantidakis, Hamza Zerhouni
Time series forecasting is an important task in many fields ranging from supply chain management to weather forecasting. Recently, Transformer neural network architectures have shown promising results in forecasting on common time series benchmark datasets. However, application to supply chain demand forecasting, which can have challenging characteristics such as sparsity and cross-series effects, has been limited. In this work, we explore the application of Transformer-based models to supply chain demand forecasting. In particular, we develop a new Transformer-based forecasting approach using a shared, multi-task per-time series network with an initial component applying attention across time series, to capture interactions and help address sparsity. We provide a case study applying our approach to successfully improve demand prediction for a medical device manufacturing company. To further validate our approach, we also apply it to public demand forecasting datasets as well and demonstrate competitive to superior performance compared to a variety of baseline and state-of-the-art forecast methods across the private and public datasets.
Read more8/9/2024

0
UniTST: Effectively Modeling Inter-Series and Intra-Series Dependencies for Multivariate Time Series Forecasting
Juncheng Liu, Chenghao Liu, Gerald Woo, Yiwei Wang, Bryan Hooi, Caiming Xiong, Doyen Sahoo
Transformer-based models have emerged as powerful tools for multivariate time series forecasting (MTSF). However, existing Transformer models often fall short of capturing both intricate dependencies across variate and temporal dimensions in MTS data. Some recent models are proposed to separately capture variate and temporal dependencies through either two sequential or parallel attention mechanisms. However, these methods cannot directly and explicitly learn the intricate inter-series and intra-series dependencies. In this work, we first demonstrate that these dependencies are very important as they usually exist in real-world data. To directly model these dependencies, we propose a transformer-based model UniTST containing a unified attention mechanism on the flattened patch tokens. Additionally, we add a dispatcher module which reduces the complexity and makes the model feasible for a potentially large number of variates. Although our proposed model employs a simple architecture, it offers compelling performance as shown in our extensive experiments on several datasets for time series forecasting.
Read more6/10/2024
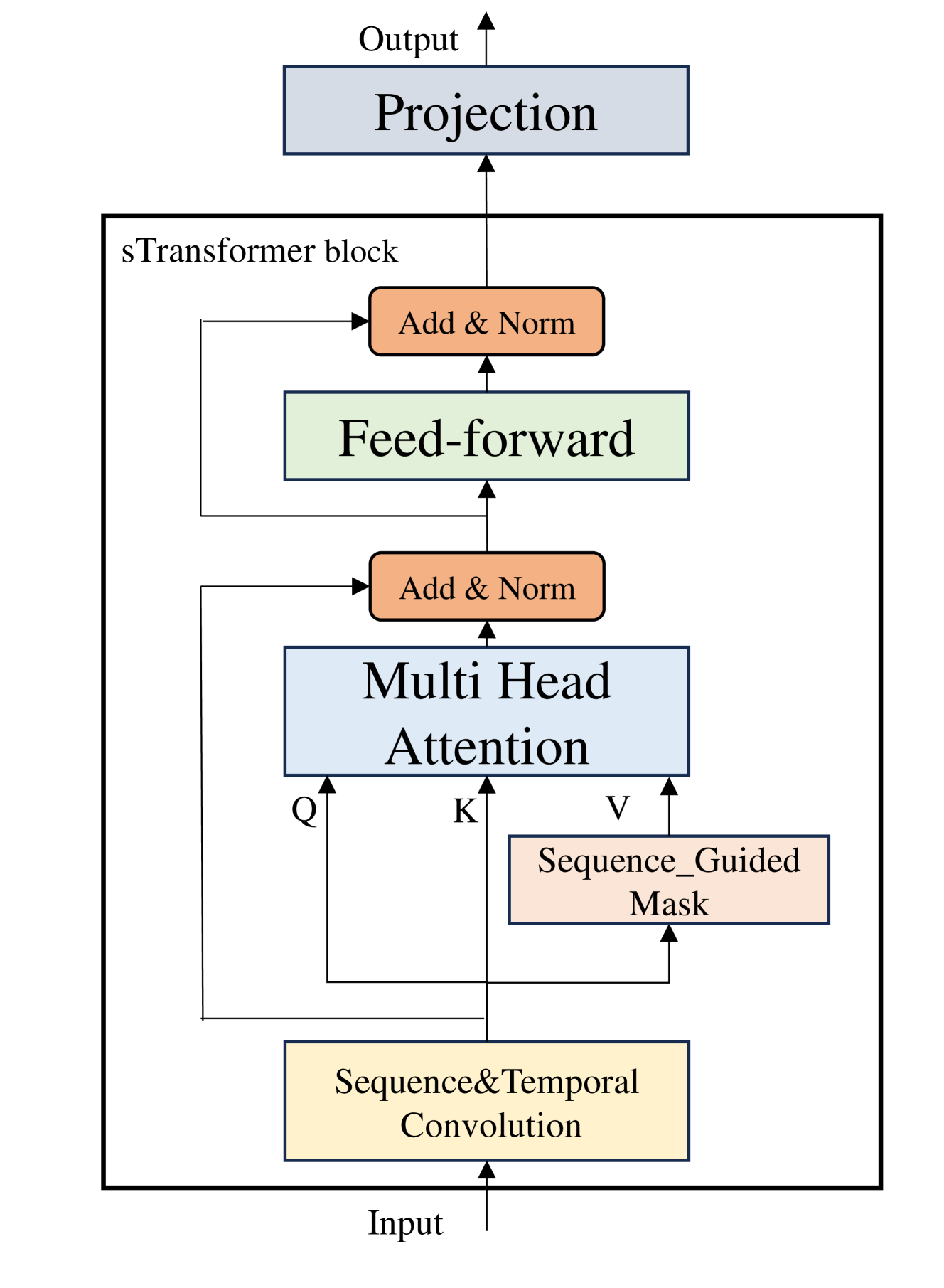
0
sTransformer: A Modular Approach for Extracting Inter-Sequential and Temporal Information for Time-Series Forecasting
Jiaheng Yin, Zhengxin Shi, Jianshen Zhang, Xiaomin Lin, Yulin Huang, Yongzhi Qi, Wei Qi
In recent years, numerous Transformer-based models have been applied to long-term time-series forecasting (LTSF) tasks. However, recent studies with linear models have questioned their effectiveness, demonstrating that simple linear layers can outperform sophisticated Transformer-based models. In this work, we review and categorize existing Transformer-based models into two main types: (1) modifications to the model structure and (2) modifications to the input data. The former offers scalability but falls short in capturing inter-sequential information, while the latter preprocesses time-series data but is challenging to use as a scalable module. We propose $textbf{sTransformer}$, which introduces the Sequence and Temporal Convolutional Network (STCN) to fully capture both sequential and temporal information. Additionally, we introduce a Sequence-guided Mask Attention mechanism to capture global feature information. Our approach ensures the capture of inter-sequential information while maintaining module scalability. We compare our model with linear models and existing forecasting models on long-term time-series forecasting, achieving new state-of-the-art results. We also conducted experiments on other time-series tasks, achieving strong performance. These demonstrate that Transformer-based structures remain effective and our model can serve as a viable baseline for time-series tasks.
Read more8/20/2024
🔎
0
Leveraging 2D Information for Long-term Time Series Forecasting with Vanilla Transformers
Xin Cheng, Xiuying Chen, Shuqi Li, Di Luo, Xun Wang, Dongyan Zhao, Rui Yan
Time series prediction is crucial for understanding and forecasting complex dynamics in various domains, ranging from finance and economics to climate and healthcare. Based on Transformer architecture, one approach involves encoding multiple variables from the same timestamp into a single temporal token to model global dependencies. In contrast, another approach embeds the time points of individual series into separate variate tokens. The former method faces challenges in learning variate-centric representations, while the latter risks missing essential temporal information critical for accurate forecasting. In our work, we introduce GridTST, a model that combines the benefits of two approaches using innovative multi-directional attentions based on a vanilla Transformer. We regard the input time series data as a grid, where the $x$-axis represents the time steps and the $y$-axis represents the variates. A vertical slicing of this grid combines the variates at each time step into a textit{time token}, while a horizontal slicing embeds the individual series across all time steps into a textit{variate token}. Correspondingly, a textit{horizontal attention mechanism} focuses on time tokens to comprehend the correlations between data at various time steps, while a textit{vertical}, variate-aware textit{attention} is employed to grasp multivariate correlations. This combination enables efficient processing of information across both time and variate dimensions, thereby enhancing the model's analytical strength. % We also integrate the patch technique, segmenting time tokens into subseries-level patches, ensuring that local semantic information is retained in the embedding. The GridTST model consistently delivers state-of-the-art performance across various real-world datasets.
Read more5/24/2024