sTransformer: A Modular Approach for Extracting Inter-Sequential and Temporal Information for Time-Series Forecasting

0
Sign in to get full access
Overview
- The paper proposes a modular Transformer-based architecture called sTransformer for time-series forecasting.
- sTransformer aims to extract both inter-sequential and temporal information from time series data.
- The model leverages a multi-head self-attention mechanism to capture long-range dependencies in the data.
Plain English Explanation
The paper introduces a new machine learning model called sTransformer that is designed to work well with time-series data, which is data that changes over time. Time-series data is commonly used in applications like stock price prediction, weather forecasting, and demand planning.
The key idea behind sTransformer is that it uses a special type of neural network called a Transformer to extract two important types of information from the time-series data:
-
Inter-sequential information: This refers to the relationships and patterns between different sequences of data, such as how stock prices for different companies tend to move together.
-
Temporal information: This refers to how the data changes over time, capturing trends, cycles, and other temporal dynamics.
By using a multi-head self-attention mechanism, sTransformer is able to identify long-range dependencies in the time-series data that can be important for accurate forecasting. This makes the model more powerful and flexible compared to traditional time-series forecasting techniques.
The modular design of sTransformer also allows the model to be customized and adapted to different types of time-series data and forecasting tasks.
Technical Explanation
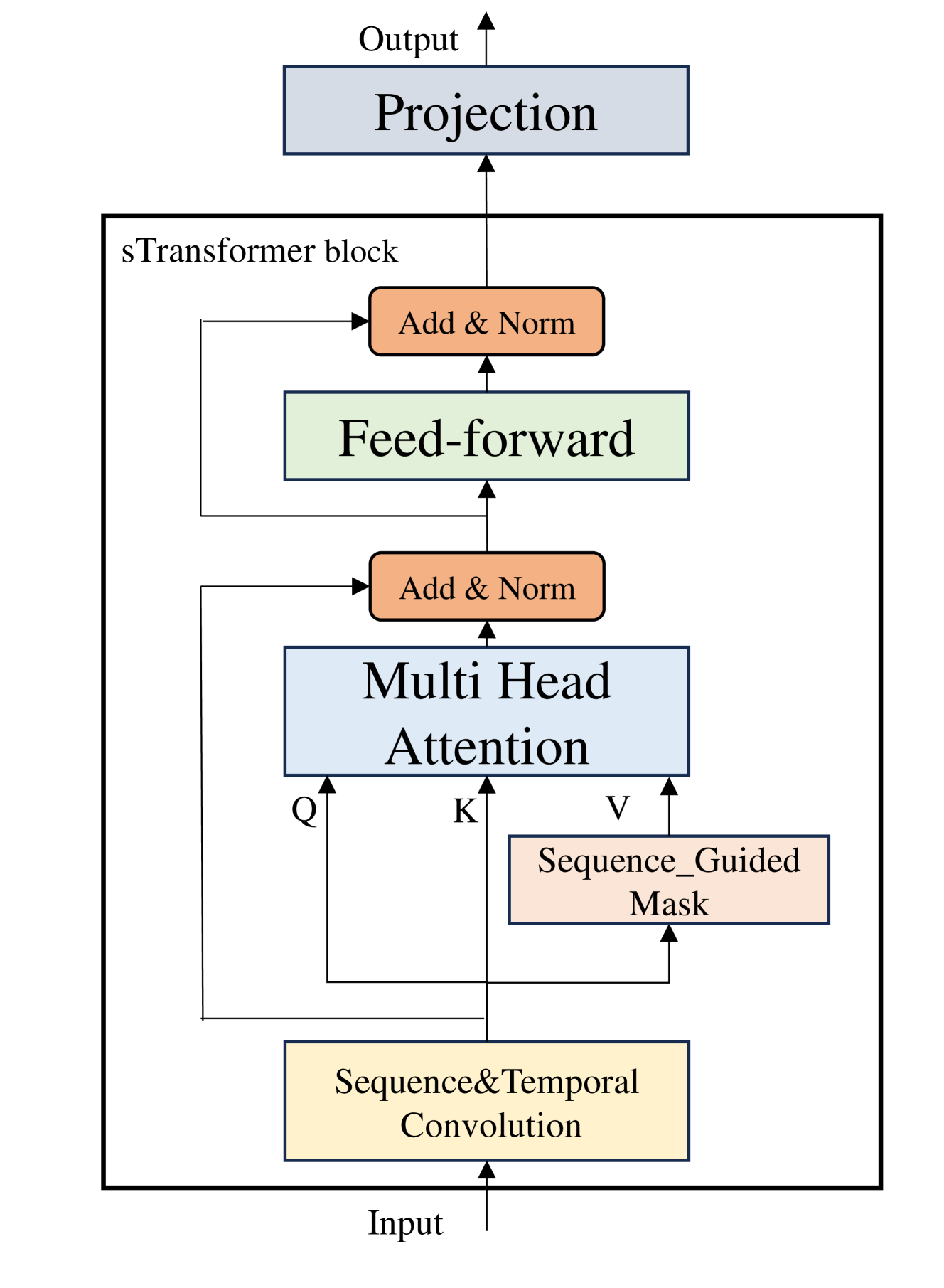
The key technical components of the sTransformer model include:
-
Encoder-Decoder Architecture: sTransformer follows an encoder-decoder structure, where the encoder processes the input time-series data and the decoder generates the forecasted outputs.
-
Temporal Embeddings: sTransformer incorporates temporal information by adding positional embeddings to the input data, which encode the timestamp of each data point.
-
Multi-Head Self-Attention: The Transformer blocks in sTransformer's encoder and decoder utilize a multi-head self-attention mechanism to capture long-range dependencies in the time-series data.
-
Inter-Sequence Attention: sTransformer includes an additional attention mechanism to model the relationships between different time-series sequences (e.g., stock prices of different companies).
-
Modular Design: The architecture of sTransformer is designed to be modular, allowing researchers and practitioners to easily customize and experiment with different components of the model.
The paper evaluates sTransformer on several time-series forecasting benchmarks and demonstrates its superior performance compared to other state-of-the-art models.
Critical Analysis
The paper provides a thorough technical explanation of the sTransformer model and its key components. The modular design is a particularly noteworthy aspect, as it allows the model to be easily adapted to different time-series forecasting tasks and datasets.
One potential limitation of the research is the lack of a deeper analysis of the specific types of time-series patterns and dependencies that sTransformer is able to capture. The paper could have provided more insights into the model's strengths and weaknesses in handling different types of time-series data.
Additionally, the paper could have discussed potential challenges or edge cases where sTransformer may not perform as well, such as handling missing data, dealing with high-frequency time-series, or accounting for exogenous factors that influence the time-series.
Overall, the sTransformer model presents a promising approach to time-series forecasting, and the paper's detailed technical explanation and experimental results provide a solid foundation for further research and development in this area.
Conclusion
The sTransformer paper introduces a novel Transformer-based architecture for time-series forecasting that can effectively extract both inter-sequential and temporal information from the data. The modular design of the model allows for customization and adaptation to different forecasting tasks and datasets.
The paper's technical explanation and experimental results demonstrate the potential of sTransformer to outperform other state-of-the-art time-series forecasting models. While the research could benefit from a deeper analysis of the model's strengths and limitations, the sTransformer approach represents a significant contribution to the field of time-series analysis and forecasting.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
sTransformer: A Modular Approach for Extracting Inter-Sequential and Temporal Information for Time-Series Forecasting
Jiaheng Yin, Zhengxin Shi, Jianshen Zhang, Xiaomin Lin, Yulin Huang, Yongzhi Qi, Wei Qi
In recent years, numerous Transformer-based models have been applied to long-term time-series forecasting (LTSF) tasks. However, recent studies with linear models have questioned their effectiveness, demonstrating that simple linear layers can outperform sophisticated Transformer-based models. In this work, we review and categorize existing Transformer-based models into two main types: (1) modifications to the model structure and (2) modifications to the input data. The former offers scalability but falls short in capturing inter-sequential information, while the latter preprocesses time-series data but is challenging to use as a scalable module. We propose $textbf{sTransformer}$, which introduces the Sequence and Temporal Convolutional Network (STCN) to fully capture both sequential and temporal information. Additionally, we introduce a Sequence-guided Mask Attention mechanism to capture global feature information. Our approach ensures the capture of inter-sequential information while maintaining module scalability. We compare our model with linear models and existing forecasting models on long-term time-series forecasting, achieving new state-of-the-art results. We also conducted experiments on other time-series tasks, achieving strong performance. These demonstrate that Transformer-based structures remain effective and our model can serve as a viable baseline for time-series tasks.
Read more8/20/2024
⛏️
628
xLSTMTime : Long-term Time Series Forecasting With xLSTM
Musleh Alharthi, Ausif Mahmood
In recent years, transformer-based models have gained prominence in multivariate long-term time series forecasting (LTSF), demonstrating significant advancements despite facing challenges such as high computational demands, difficulty in capturing temporal dynamics, and managing long-term dependencies. The emergence of LTSF-Linear, with its straightforward linear architecture, has notably outperformed transformer-based counterparts, prompting a reevaluation of the transformer's utility in time series forecasting. In response, this paper presents an adaptation of a recent architecture termed extended LSTM (xLSTM) for LTSF. xLSTM incorporates exponential gating and a revised memory structure with higher capacity that has good potential for LTSF. Our adopted architecture for LTSF termed as xLSTMTime surpasses current approaches. We compare xLSTMTime's performance against various state-of-the-art models across multiple real-world da-tasets, demonstrating superior forecasting capabilities. Our findings suggest that refined recurrent architectures can offer competitive alternatives to transformer-based models in LTSF tasks, po-tentially redefining the landscape of time series forecasting.
Read more8/13/2024
🔎
0
Leveraging 2D Information for Long-term Time Series Forecasting with Vanilla Transformers
Xin Cheng, Xiuying Chen, Shuqi Li, Di Luo, Xun Wang, Dongyan Zhao, Rui Yan
Time series prediction is crucial for understanding and forecasting complex dynamics in various domains, ranging from finance and economics to climate and healthcare. Based on Transformer architecture, one approach involves encoding multiple variables from the same timestamp into a single temporal token to model global dependencies. In contrast, another approach embeds the time points of individual series into separate variate tokens. The former method faces challenges in learning variate-centric representations, while the latter risks missing essential temporal information critical for accurate forecasting. In our work, we introduce GridTST, a model that combines the benefits of two approaches using innovative multi-directional attentions based on a vanilla Transformer. We regard the input time series data as a grid, where the $x$-axis represents the time steps and the $y$-axis represents the variates. A vertical slicing of this grid combines the variates at each time step into a textit{time token}, while a horizontal slicing embeds the individual series across all time steps into a textit{variate token}. Correspondingly, a textit{horizontal attention mechanism} focuses on time tokens to comprehend the correlations between data at various time steps, while a textit{vertical}, variate-aware textit{attention} is employed to grasp multivariate correlations. This combination enables efficient processing of information across both time and variate dimensions, thereby enhancing the model's analytical strength. % We also integrate the patch technique, segmenting time tokens into subseries-level patches, ensuring that local semantic information is retained in the embedding. The GridTST model consistently delivers state-of-the-art performance across various real-world datasets.
Read more5/24/2024

0
UniTST: Effectively Modeling Inter-Series and Intra-Series Dependencies for Multivariate Time Series Forecasting
Juncheng Liu, Chenghao Liu, Gerald Woo, Yiwei Wang, Bryan Hooi, Caiming Xiong, Doyen Sahoo
Transformer-based models have emerged as powerful tools for multivariate time series forecasting (MTSF). However, existing Transformer models often fall short of capturing both intricate dependencies across variate and temporal dimensions in MTS data. Some recent models are proposed to separately capture variate and temporal dependencies through either two sequential or parallel attention mechanisms. However, these methods cannot directly and explicitly learn the intricate inter-series and intra-series dependencies. In this work, we first demonstrate that these dependencies are very important as they usually exist in real-world data. To directly model these dependencies, we propose a transformer-based model UniTST containing a unified attention mechanism on the flattened patch tokens. Additionally, we add a dispatcher module which reduces the complexity and makes the model feasible for a potentially large number of variates. Although our proposed model employs a simple architecture, it offers compelling performance as shown in our extensive experiments on several datasets for time series forecasting.
Read more6/10/2024