On the Interpretability of Quantum Neural Networks
2308.11098
0
0
🧠
Abstract
Interpretability of artificial intelligence (AI) methods, particularly deep neural networks, is of great interest. This heightened focus stems from the widespread use of AI-backed systems. These systems, often relying on intricate neural architectures, can exhibit behavior that is challenging to explain and comprehend. The interpretability of such models is a crucial component of building trusted systems. Many methods exist to approach this problem, but they do not apply straightforwardly to the quantum setting. Here, we explore the interpretability of quantum neural networks using local model-agnostic interpretability measures commonly utilized for classical neural networks. Following this analysis, we generalize a classical technique called LIME, introducing Q-LIME, which produces explanations of quantum neural networks. A feature of our explanations is the delineation of the region in which data samples have been given a random label, likely subjects of inherently random quantum measurements. We view this as a step toward understanding how to build responsible and accountable quantum AI models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Interpretability of AI systems, particularly deep neural networks, is a crucial concern as they become more widely used.
- Quantum neural networks present unique challenges for interpretability that existing methods do not address.
- The paper explores applying local model-agnostic interpretability measures, commonly used for classical neural networks, to quantum neural networks.
- The authors introduce Q-LIME, a quantum-focused adaptation of the LIME interpretability technique.
- Q-LIME can identify regions where data samples are likely subject to inherent quantum randomness, providing insights into quantum AI model behavior.
Plain English Explanation
Understanding how AI models make decisions is important as they become more prevalent. This is especially true for complex models like deep neural networks. With quantum computers on the horizon, researchers are also exploring quantum neural networks - AI systems that use quantum mechanics.
Explaining the inner workings of quantum neural networks is very challenging. Existing interpretability methods designed for classical AI don't apply straightforwardly to the quantum realm. In this paper, the authors tackle this problem by adapting a popular technique called LIME to work with quantum neural networks.
Their new method, called Q-LIME, can identify regions in the data where the quantum neural network is essentially making random guesses. This helps provide insights into how these complex quantum AI models are behaving and makes them more transparent. The authors view this as an important step towards building quantum AI systems that are responsible and accountable.
Technical Explanation
The paper examines the use of local model-agnostic interpretability measures, such as LIME, to analyze the inner workings of quantum neural networks. These techniques are commonly applied to classical neural networks to understand how they make predictions.
The authors first analyze the application of these interpretability methods to quantum neural networks. They find that while some measures can be directly adapted, others require more careful consideration due to the unique properties of quantum systems.
Building on this analysis, the researchers introduce Q-LIME, a quantum-focused adaptation of the LIME technique. Q-LIME produces explanations that highlight regions in the data where the quantum neural network is likely making essentially random predictions, due to the inherent randomness of quantum measurements.
The authors demonstrate the capabilities of Q-LIME through experiments on synthetic and real-world quantum datasets. They show how the method can provide valuable insights into the decision-making process of quantum neural networks, which is a crucial step towards building interpretable graph neural networks for tabular data and other responsible quantum AI systems.
Critical Analysis
The paper makes a valuable contribution by addressing the important challenge of interpretability for quantum neural networks. The authors' adaptation of LIME, a well-established interpretability technique, is a thoughtful approach to this problem.
One potential limitation is the reliance on synthetic data for some of the experiments. While this allows for controlled testing, further evaluation on real-world quantum datasets would be beneficial to validate the method's performance in practical applications.
Additionally, the paper focuses on local interpretability measures, which provide explanations for individual predictions. Exploring global interpretability techniques that can offer a more holistic understanding of quantum neural network behavior could be an interesting avenue for future research.
Overall, the paper represents an important step towards building accountable and responsible quantum AI models. Continued research in this direction will be crucial as quantum computing advances and becomes more widely adopted.
Conclusion
This paper tackles the challenge of interpreting quantum neural networks, which is a critical concern as these systems become more prevalent. By adapting the LIME interpretability technique for the quantum setting, the authors have developed Q-LIME, a method that can identify regions in the data where quantum neural networks are likely making random predictions.
The insights provided by Q-LIME represent an important step towards building transparent and accountable quantum AI models. As quantum computing continues to progress, research like this will be vital to ensuring these powerful technologies are used responsibly and in a way that engenders public trust.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Feature Importance and Explainability in Quantum Machine Learning
Luke Power, Krishnendu Guha
0
0
Many Machine Learning (ML) models are referred to as black box models, providing no real insights into why a prediction is made. Feature importance and explainability are important for increasing transparency and trust in ML models, particularly in settings such as healthcare and finance. With quantum computing's unique capabilities, such as leveraging quantum mechanical phenomena like superposition, which can be combined with ML techniques to create the field of Quantum Machine Learning (QML), and such techniques may be applied to QML models. This article explores feature importance and explainability insights in QML compared to Classical ML models. Utilizing the widely recognized Iris dataset, classical ML algorithms such as SVM and Random Forests, are compared against hybrid quantum counterparts, implemented via IBM's Qiskit platform: the Variational Quantum Classifier (VQC) and Quantum Support Vector Classifier (QSVC). This article aims to provide a comparison of the insights generated in ML by employing permutation and leave one out feature importance methods, alongside ALE (Accumulated Local Effects) and SHAP (SHapley Additive exPlanations) explainers.
5/16/2024
🧠
Experimental verification of the quantum nature of a neural network
Andrei T. Patrascu
0
0
Neural networks are being used to improve the probing of the state spaces of many particle systems as approximations to wavefunctions and in order to avoid the recurring sign problem of quantum monte-carlo. One may ask whether the usual classical neural networks have some actual hidden quantum properties that make them such suitable tools for a highly coupled quantum problem. I discuss here what makes a system quantum and to what extent we can interpret a neural network as having quantum remnants. I suggest that a system can be quantum both due to its fundamental quantum constituents and due to the rules of its functioning, therefore, we can obtain entanglement both due to the quantum constituents' nature and due to the functioning rules, or, in category theory terms, both due to the quantum nature of the objects of a category and of the maps. From a practical point of view, I suggest a possible experiment that could extract entanglement from the quantum functioning rules (maps) of an otherwise classical (from the point of view of the constituents) neural network.
5/7/2024
🔮
Topological Interpretability for Deep-Learning
Adam Spannaus, Heidi A. Hanson, Lynne Penberthy, Georgia Tourassi
0
0
With the growing adoption of AI-based systems across everyday life, the need to understand their decision-making mechanisms is correspondingly increasing. The level at which we can trust the statistical inferences made from AI-based decision systems is an increasing concern, especially in high-risk systems such as criminal justice or medical diagnosis, where incorrect inferences may have tragic consequences. Despite their successes in providing solutions to problems involving real-world data, deep learning (DL) models cannot quantify the certainty of their predictions. These models are frequently quite confident, even when their solutions are incorrect. This work presents a method to infer prominent features in two DL classification models trained on clinical and non-clinical text by employing techniques from topological and geometric data analysis. We create a graph of a model's feature space and cluster the inputs into the graph's vertices by the similarity of features and prediction statistics. We then extract subgraphs demonstrating high-predictive accuracy for a given label. These subgraphs contain a wealth of information about features that the DL model has recognized as relevant to its decisions. We infer these features for a given label using a distance metric between probability measures, and demonstrate the stability of our method compared to the LIME and SHAP interpretability methods. This work establishes that we may gain insights into the decision mechanism of a DL model. This method allows us to ascertain if the model is making its decisions based on information germane to the problem or identifies extraneous patterns within the data.
4/15/2024
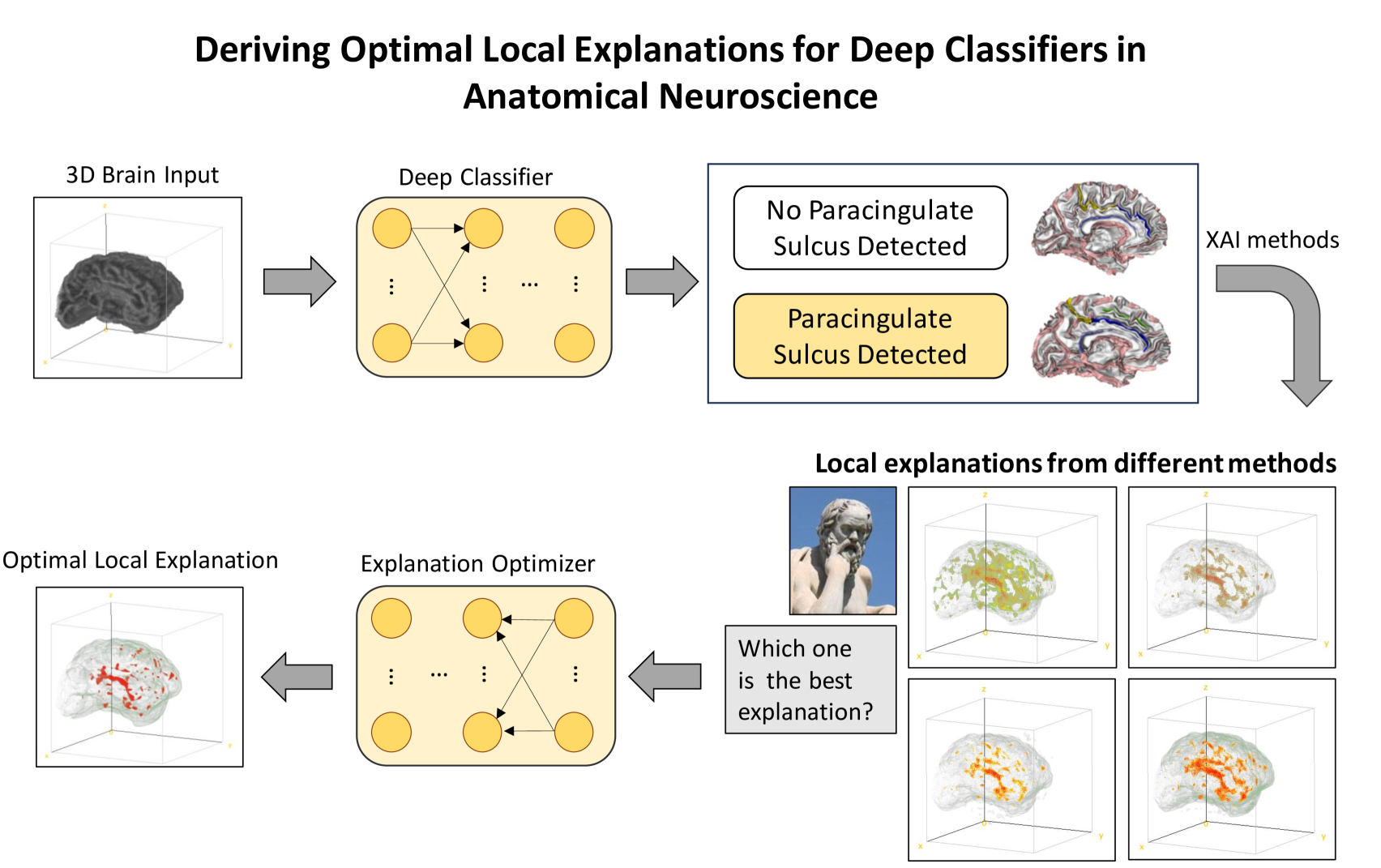
New!Solving the enigma: Deriving optimal explanations of deep networks
Michail Mamalakis, Antonios Mamalakis, Ingrid Agartz, Lynn Egeland M{o}rch-Johnsen, Graham Murray, John Suckling, Pietro Lio
0
0
The accelerated progress of artificial intelligence (AI) has popularized deep learning models across domains, yet their inherent opacity poses challenges, notably in critical fields like healthcare, medicine and the geosciences. Explainable AI (XAI) has emerged to shed light on these black box models, helping decipher their decision making process. Nevertheless, different XAI methods yield highly different explanations. This inter-method variability increases uncertainty and lowers trust in deep networks' predictions. In this study, for the first time, we propose a novel framework designed to enhance the explainability of deep networks, by maximizing both the accuracy and the comprehensibility of the explanations. Our framework integrates various explanations from established XAI methods and employs a non-linear explanation optimizer to construct a unique and optimal explanation. Through experiments on multi-class and binary classification tasks in 2D object and 3D neuroscience imaging, we validate the efficacy of our approach. Our explanation optimizer achieved superior faithfulness scores, averaging 155% and 63% higher than the best performing XAI method in the 3D and 2D applications, respectively. Additionally, our approach yielded lower complexity, increasing comprehensibility. Our results suggest that optimal explanations based on specific criteria are derivable and address the issue of inter-method variability in the current XAI literature.
5/17/2024