Topological Interpretability for Deep-Learning
2305.08642
0
0
🔮
Abstract
With the growing adoption of AI-based systems across everyday life, the need to understand their decision-making mechanisms is correspondingly increasing. The level at which we can trust the statistical inferences made from AI-based decision systems is an increasing concern, especially in high-risk systems such as criminal justice or medical diagnosis, where incorrect inferences may have tragic consequences. Despite their successes in providing solutions to problems involving real-world data, deep learning (DL) models cannot quantify the certainty of their predictions. These models are frequently quite confident, even when their solutions are incorrect. This work presents a method to infer prominent features in two DL classification models trained on clinical and non-clinical text by employing techniques from topological and geometric data analysis. We create a graph of a model's feature space and cluster the inputs into the graph's vertices by the similarity of features and prediction statistics. We then extract subgraphs demonstrating high-predictive accuracy for a given label. These subgraphs contain a wealth of information about features that the DL model has recognized as relevant to its decisions. We infer these features for a given label using a distance metric between probability measures, and demonstrate the stability of our method compared to the LIME and SHAP interpretability methods. This work establishes that we may gain insights into the decision mechanism of a DL model. This method allows us to ascertain if the model is making its decisions based on information germane to the problem or identifies extraneous patterns within the data.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- As AI-based systems become more prevalent, there is a growing need to understand how they make decisions.
- Deep learning (DL) models are often highly confident in their predictions, even when they are incorrect.
- This paper presents a method to analyze the decision-making mechanisms of DL classification models by using techniques from topological and geometric data analysis.
Plain English Explanation
The paper discusses the growing use of AI-based systems in everyday life and the importance of understanding how these systems make decisions, especially in high-risk areas like criminal justice or medical diagnosis. Deep learning models, which are a type of AI, are often very confident in their predictions, even when they are wrong.
The researchers in this paper developed a method to better understand how deep learning models make decisions. They created a graph of the model's feature space, which is the set of information the model uses to make its predictions. They then grouped the inputs to the model based on the similarity of their features and the model's prediction statistics. This allowed them to identify subgraphs, or smaller parts of the overall graph, where the model was making highly accurate predictions for a particular label or outcome.
By analyzing these subgraphs, the researchers were able to infer the important features that the deep learning model had recognized as relevant to its decisions. This helps to understand if the model is basing its decisions on information that is truly relevant to the problem, or if it is detecting patterns in the data that are not actually important.
The researchers compared their method to other interpretability techniques, such as LIME and SHAP, and found that their method was more stable and reliable.
Technical Explanation
The researchers used techniques from topological and geometric data analysis to create a graph representation of the feature space of two deep learning classification models, one trained on clinical text data and one on non-clinical text data.
They clustered the inputs to the models into the vertices (or nodes) of the graph based on the similarity of their features and the model's prediction statistics. This allowed them to extract subgraphs within the overall graph that demonstrated high predictive accuracy for a given label or outcome.
By analyzing these high-accuracy subgraphs, the researchers were able to infer the prominent features that the deep learning models had recognized as relevant to their decisions. They used a distance metric between probability measures to identify these important features.
The researchers compared their method to other interpretability techniques, such as LIME and SHAP, and found that their method was more stable and reliable in identifying the features that the models had used to make their predictions.
Critical Analysis
The paper presents a novel and promising approach for understanding the decision-making mechanisms of deep learning models. By using techniques from topological and geometric data analysis, the researchers were able to gain insights into the features that the models were recognizing as relevant to their predictions.
However, the paper does not address some potential limitations of the method. For example, it is not clear how well the method would scale to larger and more complex deep learning models, or how it would perform on more diverse types of data, such as images or audio.
Additionally, the paper does not discuss the computational complexity of the method, which could be a concern for real-world applications where models need to make decisions quickly.
Further research could also explore how the insights gained from this method could be used to improve the interpretability and trustworthiness of deep learning models, particularly in high-risk domains like medical diagnosis or criminal justice.
Conclusion
This paper presents a novel method for understanding the decision-making mechanisms of deep learning models by using techniques from topological and geometric data analysis. The researchers were able to infer the prominent features that the models recognized as relevant to their predictions, and they demonstrated the stability and reliability of their method compared to other interpretability techniques.
The insights gained from this research could be valuable for improving the transparency and trustworthiness of deep learning models, particularly in high-risk domains where the consequences of incorrect decisions can be severe. Further research is needed to explore the scalability and generalizability of the method, as well as its potential applications for enhancing the interpretability of AI-based systems.
Related Papers
🧠
On the Interpretability of Quantum Neural Networks
Lirande Pira, Chris Ferrie
0
0
Interpretability of artificial intelligence (AI) methods, particularly deep neural networks, is of great interest. This heightened focus stems from the widespread use of AI-backed systems. These systems, often relying on intricate neural architectures, can exhibit behavior that is challenging to explain and comprehend. The interpretability of such models is a crucial component of building trusted systems. Many methods exist to approach this problem, but they do not apply straightforwardly to the quantum setting. Here, we explore the interpretability of quantum neural networks using local model-agnostic interpretability measures commonly utilized for classical neural networks. Following this analysis, we generalize a classical technique called LIME, introducing Q-LIME, which produces explanations of quantum neural networks. A feature of our explanations is the delineation of the region in which data samples have been given a random label, likely subjects of inherently random quantum measurements. We view this as a step toward understanding how to build responsible and accountable quantum AI models.
4/22/2024
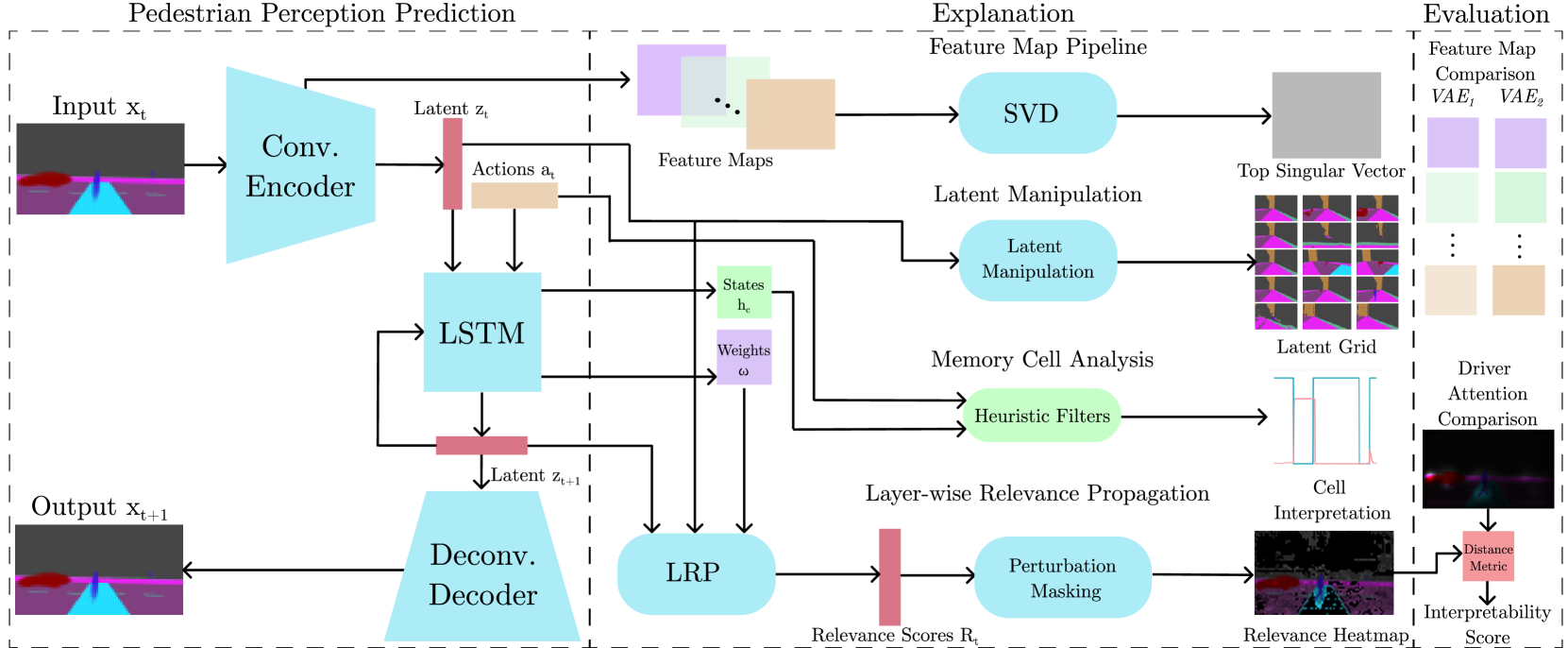
On the Road to Clarity: Exploring Explainable AI for World Models in a Driver Assistance System
Mohamed Roshdi, Julian Petzold, Mostafa Wahby, Hussein Ebrahim, Mladen Berekovic, Heiko Hamann
0
0
In Autonomous Driving (AD) transparency and safety are paramount, as mistakes are costly. However, neural networks used in AD systems are generally considered black boxes. As a countermeasure, we have methods of explainable AI (XAI), such as feature relevance estimation and dimensionality reduction. Coarse graining techniques can also help reduce dimensionality and find interpretable global patterns. A specific coarse graining method is Renormalization Groups from statistical physics. It has previously been applied to Restricted Boltzmann Machines (RBMs) to interpret unsupervised learning. We refine this technique by building a transparent backbone model for convolutional variational autoencoders (VAE) that allows mapping latent values to input features and has performance comparable to trained black box VAEs. Moreover, we propose a custom feature map visualization technique to analyze the internal convolutional layers in the VAE to explain internal causes of poor reconstruction that may lead to dangerous traffic scenarios in AD applications. In a second key contribution, we propose explanation and evaluation techniques for the internal dynamics and feature relevance of prediction networks. We test a long short-term memory (LSTM) network in the computer vision domain to evaluate the predictability and in future applications potentially safety of prediction models. We showcase our methods by analyzing a VAE-LSTM world model that predicts pedestrian perception in an urban traffic situation.
4/29/2024
Characterizing the Influence of Topology on Graph Learning Tasks
Kailong Wu, Yule Xie, Jiaxin Ding, Yuxiang Ren, Luoyi Fu, Xinbing Wang, Chenghu Zhou
0
0
Graph neural networks (GNN) have achieved remarkable success in a wide range of tasks by encoding features combined with topology to create effective representations. However, the fundamental problem of understanding and analyzing how graph topology influences the performance of learning models on downstream tasks has not yet been well understood. In this paper, we propose a metric, TopoInf, which characterizes the influence of graph topology by measuring the level of compatibility between the topological information of graph data and downstream task objectives. We provide analysis based on the decoupled GNNs on the contextual stochastic block model to demonstrate the effectiveness of the metric. Through extensive experiments, we demonstrate that TopoInf is an effective metric for measuring topological influence on corresponding tasks and can be further leveraged to enhance graph learning.
4/12/2024
🌐
Probabilistic Dataset Reconstruction from Interpretable Models
Julien Ferry (LAAS-ROC), Ulrich Aivodji (ETS), S'ebastien Gambs (UQAM), Marie-Jos'e Huguet (LAAS-ROC), Mohamed Siala (LAAS-ROC)
0
0
Interpretability is often pointed out as a key requirement for trustworthy machine learning. However, learning and releasing models that are inherently interpretable leaks information regarding the underlying training data. As such disclosure may directly conflict with privacy, a precise quantification of the privacy impact of such breach is a fundamental problem. For instance, previous work have shown that the structure of a decision tree can be leveraged to build a probabilistic reconstruction of its training dataset, with the uncertainty of the reconstruction being a relevant metric for the information leak. In this paper, we propose of a novel framework generalizing these probabilistic reconstructions in the sense that it can handle other forms of interpretable models and more generic types of knowledge. In addition, we demonstrate that under realistic assumptions regarding the interpretable models' structure, the uncertainty of the reconstruction can be computed efficiently. Finally, we illustrate the applicability of our approach on both decision trees and rule lists, by comparing the theoretical information leak associated to either exact or heuristic learning algorithms. Our results suggest that optimal interpretable models are often more compact and leak less information regarding their training data than greedily-built ones, for a given accuracy level.
4/4/2024