Thermodynamics-inspired Explanations of Artificial Intelligence
2206.13475
0
0
👁️
Abstract
In recent years, predictive machine learning methods have gained prominence in various scientific domains. However, due to their black-box nature, it is essential to establish trust in these models before accepting them as accurate. One promising strategy for assigning trust involves employing explanation techniques that elucidate the rationale behind a black-box model's predictions in a manner that humans can understand. However, assessing the degree of human interpretability of the rationale generated by such methods is a nontrivial challenge. In this work, we introduce interpretation entropy as a universal solution for assessing the degree of human interpretability associated with any linear model. Using this concept and drawing inspiration from classical thermodynamics, we present Thermodynamics-inspired Explainable Representations of AI and other black-box Paradigms (TERP), a method for generating accurate, and human-interpretable explanations for black-box predictions in a model-agnostic manner. To demonstrate the wide-ranging applicability of TERP, we successfully employ it to explain various black-box model architectures, including deep learning Autoencoders, Recurrent Neural Networks, and Convolutional Neural Networks, across diverse domains such as molecular simulations, text, and image classification.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Predictive machine learning models have become widely used, but their "black-box" nature makes it challenging to trust their accuracy.
- Explanation techniques that help humans understand the reasoning behind these models' predictions could help build trust.
- Assessing the human interpretability of these explanations is a nontrivial problem.
- This paper introduces a new method called TERP to generate accurate and human-interpretable explanations for black-box models across various domains.
Plain English Explanation
Machine learning models have become very powerful at making predictions, but they can sometimes be like "black boxes" - it's not always clear how they arrive at their conclusions. This can make it hard to trust these models, especially in important applications.
One way to build trust is to use "explanation techniques" that help humans understand the reasoning behind a model's predictions. But figuring out how well these explanations can be understood by people is a tricky challenge.
In this paper, the researchers introduce a new method called TERP that can generate explanations for black-box models that are both accurate and easy for humans to understand. They show how TERP can be used to explain different types of machine learning models, like neural networks and deep learning models, across a variety of fields like molecular simulations, text, and image classification.
Technical Explanation
The researchers introduce a new concept called "interpretation entropy" as a way to measure how easy it is for humans to understand the explanations generated for black-box machine learning models. They then present the TERP (Thermodynamics-inspired Explainable Representations of AI and other black-box Paradigms) method, which uses this interpretation entropy concept to produce accurate and interpretable explanations in a model-agnostic way.
TERP works by first training a separate "explanation model" that tries to mimic the behavior of the original black-box model. This explanation model is designed to be as simple and interpretable as possible, while still making accurate predictions. The researchers then use the interpretation entropy metric to ensure the explanations generated by this model are easy for humans to understand.
To demonstrate the versatility of TERP, the researchers apply it to explain the predictions of various complex machine learning models, including deep learning autoencoders, recurrent neural networks, and convolutional neural networks, across diverse domains like molecular simulations, text, and image classification.
Critical Analysis
The TERP method proposed in this paper represents a promising approach to the challenge of making black-box machine learning models more interpretable and trustworthy. By using an interpretability metric based on thermodynamic principles, the researchers have developed a systematic way to generate human-understandable explanations for complex model predictions.
One potential limitation of the work is that the interpretation entropy metric, while theoretically grounded, may not always align perfectly with human intuitions about interpretability. The researchers acknowledge this and suggest further user studies to validate the approach.
Additionally, while TERP is described as model-agnostic, it's unclear how well the method would scale to extremely large and complex models, such as very deep neural networks or transformer-based language models. The computational overhead of training the separate explanation model may become prohibitive for such architectures.
Overall, this paper makes a valuable contribution to the field of explainable AI, demonstrating a novel and principled approach to the interpretability challenge. The TERP method is an important step forward in building trust and understanding around the increasingly influential role of black-box machine learning models in scientific and real-world applications.
Conclusion
This paper introduces a new method called TERP that can generate accurate and human-interpretable explanations for the predictions of black-box machine learning models. By using a thermodynamics-inspired concept called "interpretation entropy," TERP is able to produce explanations that are easy for humans to understand, while still capturing the essential reasoning of the original complex models.
The researchers demonstrate the broad applicability of TERP by using it to explain the predictions of various types of neural networks across diverse domains, from molecular simulations to text and image classification. This work represents an important step forward in building trust and transparency around the growing use of powerful but opaque machine learning techniques in high-stakes applications.
As machine learning continues to have an ever-greater impact on scientific research and real-world decision-making, methods like TERP will become increasingly crucial for ensuring these models are not treated as black boxes, but are understood and accepted by the humans who rely on their outputs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
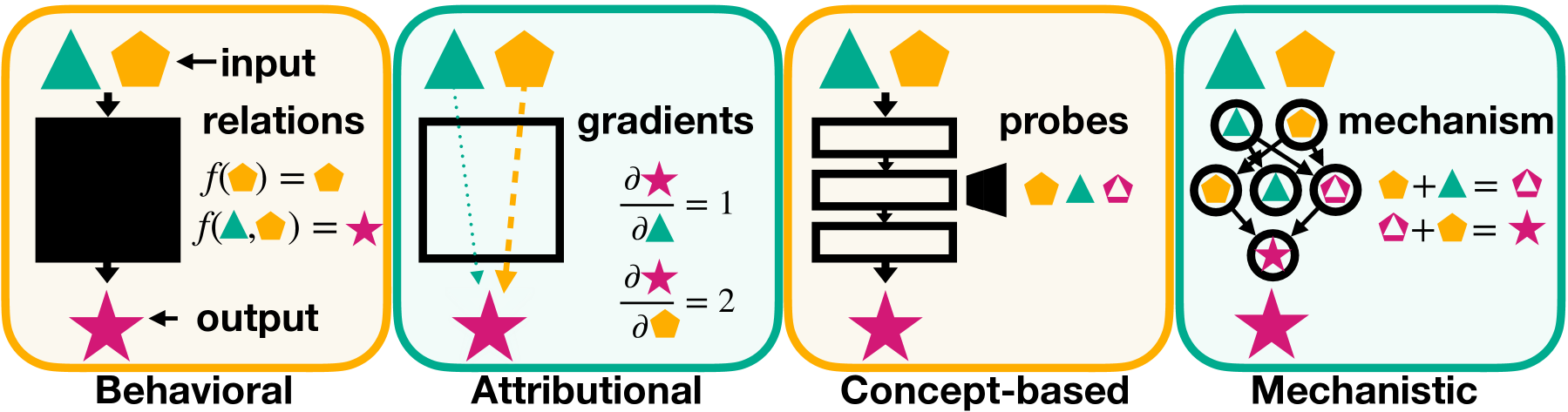
Mechanistic Interpretability for AI Safety -- A Review
Leonard Bereska, Efstratios Gavves
0
0
Understanding AI systems' inner workings is critical for ensuring value alignment and safety. This review explores mechanistic interpretability: reverse-engineering the computational mechanisms and representations learned by neural networks into human-understandable algorithms and concepts to provide a granular, causal understanding. We establish foundational concepts such as features encoding knowledge within neural activations and hypotheses about their representation and computation. We survey methodologies for causally dissecting model behaviors and assess the relevance of mechanistic interpretability to AI safety. We investigate challenges surrounding scalability, automation, and comprehensive interpretation. We advocate for clarifying concepts, setting standards, and scaling techniques to handle complex models and behaviors and expand to domains such as vision and reinforcement learning. Mechanistic interpretability could help prevent catastrophic outcomes as AI systems become more powerful and inscrutable.
4/23/2024
🔍
Distance-Restricted Explanations: Theoretical Underpinnings & Efficient Implementation
Yacine Izza, Xuanxiang Huang, Antonio Morgado, Jordi Planes, Alexey Ignatiev, Joao Marques-Silva
0
0
The uses of machine learning (ML) have snowballed in recent years. In many cases, ML models are highly complex, and their operation is beyond the understanding of human decision-makers. Nevertheless, some uses of ML models involve high-stakes and safety-critical applications. Explainable artificial intelligence (XAI) aims to help human decision-makers in understanding the operation of such complex ML models, thus eliciting trust in their operation. Unfortunately, the majority of past XAI work is based on informal approaches, that offer no guarantees of rigor. Unsurprisingly, there exists comprehensive experimental and theoretical evidence confirming that informal methods of XAI can provide human-decision makers with erroneous information. Logic-based XAI represents a rigorous approach to explainability; it is model-based and offers the strongest guarantees of rigor of computed explanations. However, a well-known drawback of logic-based XAI is the complexity of logic reasoning, especially for highly complex ML models. Recent work proposed distance-restricted explanations, i.e. explanations that are rigorous provided the distance to a given input is small enough. Distance-restricted explainability is tightly related with adversarial robustness, and it has been shown to scale for moderately complex ML models, but the number of inputs still represents a key limiting factor. This paper investigates novel algorithms for scaling up the performance of logic-based explainers when computing and enumerating ML model explanations with a large number of inputs.
5/15/2024
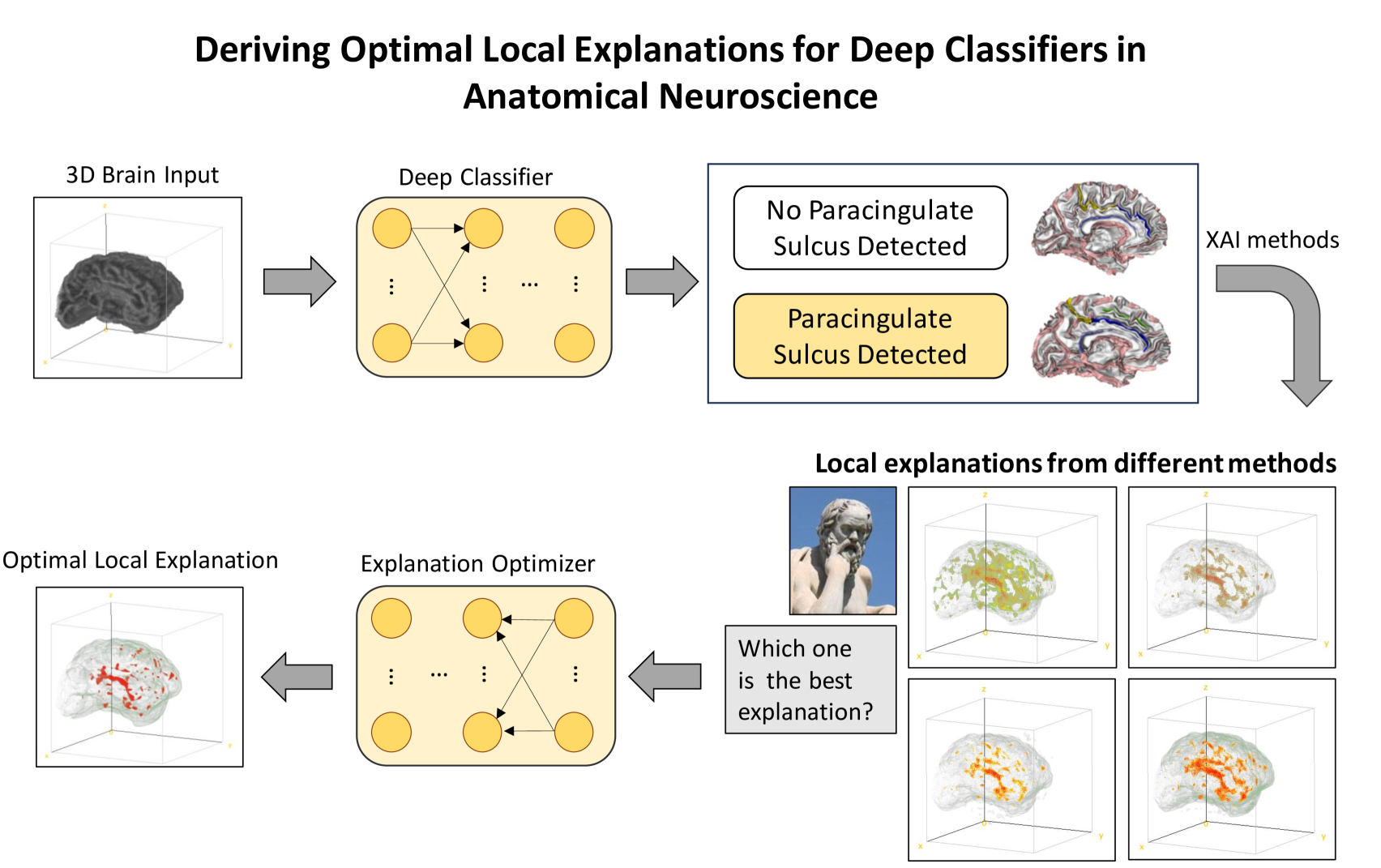
New!Solving the enigma: Deriving optimal explanations of deep networks
Michail Mamalakis, Antonios Mamalakis, Ingrid Agartz, Lynn Egeland M{o}rch-Johnsen, Graham Murray, John Suckling, Pietro Lio
0
0
The accelerated progress of artificial intelligence (AI) has popularized deep learning models across domains, yet their inherent opacity poses challenges, notably in critical fields like healthcare, medicine and the geosciences. Explainable AI (XAI) has emerged to shed light on these black box models, helping decipher their decision making process. Nevertheless, different XAI methods yield highly different explanations. This inter-method variability increases uncertainty and lowers trust in deep networks' predictions. In this study, for the first time, we propose a novel framework designed to enhance the explainability of deep networks, by maximizing both the accuracy and the comprehensibility of the explanations. Our framework integrates various explanations from established XAI methods and employs a non-linear explanation optimizer to construct a unique and optimal explanation. Through experiments on multi-class and binary classification tasks in 2D object and 3D neuroscience imaging, we validate the efficacy of our approach. Our explanation optimizer achieved superior faithfulness scores, averaging 155% and 63% higher than the best performing XAI method in the 3D and 2D applications, respectively. Additionally, our approach yielded lower complexity, increasing comprehensibility. Our results suggest that optimal explanations based on specific criteria are derivable and address the issue of inter-method variability in the current XAI literature.
5/17/2024
👁️
Interpretable Representations in Explainable AI: From Theory to Practice
Kacper Sokol, Peter Flach
0
0
Interpretable representations are the backbone of many explainers that target black-box predictive systems based on artificial intelligence and machine learning algorithms. They translate the low-level data representation necessary for good predictive performance into high-level human-intelligible concepts used to convey the explanatory insights. Notably, the explanation type and its cognitive complexity are directly controlled by the interpretable representation, tweaking which allows to target a particular audience and use case. However, many explainers built upon interpretable representations overlook their merit and fall back on default solutions that often carry implicit assumptions, thereby degrading the explanatory power and reliability of such techniques. To address this problem, we study properties of interpretable representations that encode presence and absence of human-comprehensible concepts. We demonstrate how they are operationalised for tabular, image and text data; discuss their assumptions, strengths and weaknesses; identify their core building blocks; and scrutinise their configuration and parameterisation. In particular, this in-depth analysis allows us to pinpoint their explanatory properties, desiderata and scope for (malicious) manipulation in the context of tabular data where a linear model is used to quantify the influence of interpretable concepts on a black-box prediction. Our findings lead to a range of recommendations for designing trustworthy interpretable representations; specifically, the benefits of class-aware (supervised) discretisation of tabular data, e.g., with decision trees, and sensitivity of image interpretable representations to segmentation granularity and occlusion colour.
4/29/2024