An Interpretable Client Decision Tree Aggregation process for Federated Learning
2404.02510
0
0
Abstract
Trustworthy Artificial Intelligence solutions are essential in today's data-driven applications, prioritizing principles such as robustness, safety, transparency, explainability, and privacy among others. This has led to the emergence of Federated Learning as a solution for privacy and distributed machine learning. While decision trees, as self-explanatory models, are ideal for collaborative model training across multiple devices in resource-constrained environments such as federated learning environments for injecting interpretability in these models. Decision tree structure makes the aggregation in a federated learning environment not trivial. They require techniques that can merge their decision paths without introducing bias or overfitting while keeping the aggregated decision trees robust and generalizable. In this paper, we propose an Interpretable Client Decision Tree Aggregation process for Federated Learning scenarios that keeps the interpretability and the precision of the base decision trees used for the aggregation. This model is based on aggregating multiple decision paths of the decision trees and can be used on different decision tree types, such as ID3 and CART. We carry out the experiments within four datasets, and the analysis shows that the tree built with the model improves the local models, and outperforms the state-of-the-art.
Create account to get full access
Overview
- This paper proposes an "Interpretable Client Decision Tree Aggregation" process for Federated Learning, which aims to improve the interpretability and performance of Federated Learning models.
- Federated Learning is a machine learning approach that trains a shared model across multiple decentralized devices or servers, without directly sharing the training data.
- The proposed method aggregates decision trees learned by individual clients in a Federated Learning setting, producing an interpretable global model.
- The authors demonstrate the effectiveness of their approach through experiments on benchmark datasets, showing improvements in model interpretability and performance compared to traditional Federated Learning methods.
Plain English Explanation
Federated Learning is a way for multiple devices or organizations to train a shared machine learning model, without having to share their private data. Instead of sending the data to a central location, each device trains a local model on its own data, and then these local models are combined to create a global model that everyone can use.
The paper introduces a new approach for combining these local models in Federated Learning. Normally, the local models are just averaged together, which can make the final global model difficult to understand and interpret. The authors' method instead aggregates the local models in a way that produces a decision tree-based global model, which is much more interpretable.
Decision trees are a type of machine learning model that are structured like a flowchart, with different branches representing different rules or decisions. By aggregating the local decision trees into a single global decision tree, the authors create a model that is easier for humans to understand and explain.
The authors show through experiments that their interpretable decision tree aggregation method not only produces more understandable models, but also achieves better predictive performance compared to traditional Federated Learning approaches. This suggests that interpretability and performance can go hand-in-hand in Federated Learning, rather than being a tradeoff.
Technical Explanation
The key technical contributions of the paper are:
-
Interpretable Client Decision Tree Aggregation: The authors propose a method to aggregate the decision trees learned by individual clients in a Federated Learning setting. This produces a single, interpretable global decision tree model.
-
Experiment Design: The authors evaluate their approach on benchmark datasets, comparing it to standard Federated Learning techniques as well as a centralized decision tree model. They assess both the interpretability and predictive performance of the models.
-
Insights: The results show that the proposed interpretable aggregation method outperforms standard Federated Learning in terms of both model interpretability and predictive accuracy. This suggests that interpretability and performance can be achieved simultaneously in Federated Learning.
The key technical insight is that by aggregating local decision trees, rather than simply averaging local model parameters, the authors are able to preserve the interpretable structure of the decision trees in the global model. This stands in contrast to traditional Federated Learning, where the global model can become a "black box" that is difficult for humans to understand.
Critical Analysis
The authors acknowledge several limitations and areas for future work:
-
The experiments are conducted on relatively small-scale, tabular datasets. Further evaluation is needed on larger, more complex datasets representative of real-world Federated Learning scenarios.
-
The paper does not address potential privacy and security challenges that can arise in Federated Learning settings. Techniques for preserving client privacy during the aggregation process should be investigated.
-
The proposed aggregation method relies on decision trees as the base learner. Extending the approach to work with other interpretable model types, such as rule-based models or sparse linear models, could further broaden its applicability.
-
The authors do not provide a detailed analysis of the computational and communication costs of their approach compared to standard Federated Learning. This is an important practical consideration for real-world deployments.
Overall, the paper presents a promising direction for improving the interpretability of Federated Learning models without sacrificing predictive performance. However, further research is needed to address the limitations and fully realize the potential of this approach in realistic Federated Learning scenarios.
Conclusion
This paper introduces an "Interpretable Client Decision Tree Aggregation" process for Federated Learning, which aims to produce global models that are both highly accurate and easily interpretable by humans. Through experiments, the authors demonstrate that their approach can outperform standard Federated Learning techniques in terms of both model interpretability and predictive performance.
The key insight is that by aggregating local decision trees, rather than simply averaging model parameters, the interpretable structure of the decision trees can be preserved in the global model. This represents an important step towards making Federated Learning models more transparent and understandable, which is crucial for building trust and enabling real-world deployment.
While the current evaluation is limited to smaller-scale datasets, the results suggest that interpretability and performance can go hand-in-hand in Federated Learning, rather than being a tradeoff. Further research is needed to address the identified limitations and explore the broader applicability of this approach in more realistic Federated Learning scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Pursuing Overall Welfare in Federated Learning through Sequential Decision Making
Seok-Ju Hahn, Gi-Soo Kim, Junghye Lee
0
0
In traditional federated learning, a single global model cannot perform equally well for all clients. Therefore, the need to achieve the client-level fairness in federated system has been emphasized, which can be realized by modifying the static aggregation scheme for updating the global model to an adaptive one, in response to the local signals of the participating clients. Our work reveals that existing fairness-aware aggregation strategies can be unified into an online convex optimization framework, in other words, a central server's sequential decision making process. To enhance the decision making capability, we propose simple and intuitive improvements for suboptimal designs within existing methods, presenting AAggFF. Considering practical requirements, we further subdivide our method tailored for the cross-device and the cross-silo settings, respectively. Theoretical analyses guarantee sublinear regret upper bounds for both settings: $mathcal{O}(sqrt{T log{K}})$ for the cross-device setting, and $mathcal{O}(K log{T})$ for the cross-silo setting, with $K$ clients and $T$ federation rounds. Extensive experiments demonstrate that the federated system equipped with AAggFF achieves better degree of client-level fairness than existing methods in both practical settings. Code is available at https://github.com/vaseline555/AAggFF
6/3/2024

Learning accurate and interpretable decision trees
Maria-Florina Balcan, Dravyansh Sharma
0
0
Decision trees are a popular tool in machine learning and yield easy-to-understand models. Several techniques have been proposed in the literature for learning a decision tree classifier, with different techniques working well for data from different domains. In this work, we develop approaches to design decision tree learning algorithms given repeated access to data from the same domain. We propose novel parameterized classes of node splitting criteria in top-down algorithms, which interpolate between popularly used entropy and Gini impurity based criteria, and provide theoretical bounds on the number of samples needed to learn the splitting function appropriate for the data at hand. We also study the sample complexity of tuning prior parameters in Bayesian decision tree learning, and extend our results to decision tree regression. We further consider the problem of tuning hyperparameters in pruning the decision tree for classical pruning algorithms including min-cost complexity pruning. We also study the interpretability of the learned decision trees and introduce a data-driven approach for optimizing the explainability versus accuracy trade-off using decision trees. Finally, we demonstrate the significance of our approach on real world datasets by learning data-specific decision trees which are simultaneously more accurate and interpretable.
5/28/2024
🌐
Probabilistic Dataset Reconstruction from Interpretable Models
Julien Ferry (LAAS-ROC), Ulrich Aivodji (ETS), S'ebastien Gambs (UQAM), Marie-Jos'e Huguet (LAAS-ROC), Mohamed Siala (LAAS-ROC)
0
0
Interpretability is often pointed out as a key requirement for trustworthy machine learning. However, learning and releasing models that are inherently interpretable leaks information regarding the underlying training data. As such disclosure may directly conflict with privacy, a precise quantification of the privacy impact of such breach is a fundamental problem. For instance, previous work have shown that the structure of a decision tree can be leveraged to build a probabilistic reconstruction of its training dataset, with the uncertainty of the reconstruction being a relevant metric for the information leak. In this paper, we propose of a novel framework generalizing these probabilistic reconstructions in the sense that it can handle other forms of interpretable models and more generic types of knowledge. In addition, we demonstrate that under realistic assumptions regarding the interpretable models' structure, the uncertainty of the reconstruction can be computed efficiently. Finally, we illustrate the applicability of our approach on both decision trees and rule lists, by comparing the theoretical information leak associated to either exact or heuristic learning algorithms. Our results suggest that optimal interpretable models are often more compact and leak less information regarding their training data than greedily-built ones, for a given accuracy level.
4/4/2024
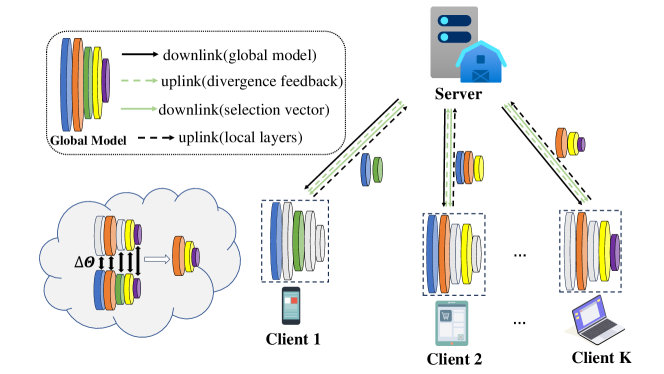
Communication-Efficient Model Aggregation with Layer Divergence Feedback in Federated Learning
Liwei Wang, Jun Li, Wen Chen, Qingqing Wu, Ming Ding
0
0
Federated Learning (FL) facilitates collaborative machine learning by training models on local datasets, and subsequently aggregating these local models at a central server. However, the frequent exchange of model parameters between clients and the central server can result in significant communication overhead during the FL training process. To solve this problem, this paper proposes a novel FL framework, the Model Aggregation with Layer Divergence Feedback mechanism (FedLDF). Specifically, we calculate model divergence between the local model and the global model from the previous round. Then through model layer divergence feedback, the distinct layers of each client are uploaded and the amount of data transferred is reduced effectively. Moreover, the convergence bound reveals that the access ratio of clients has a positive correlation with model performance. Simulation results show that our algorithm uploads local models with reduced communication overhead while upholding a superior global model performance.
4/15/2024