Probabilistic Dataset Reconstruction from Interpretable Models
2308.15099
0
0
🌐
Abstract
Interpretability is often pointed out as a key requirement for trustworthy machine learning. However, learning and releasing models that are inherently interpretable leaks information regarding the underlying training data. As such disclosure may directly conflict with privacy, a precise quantification of the privacy impact of such breach is a fundamental problem. For instance, previous work have shown that the structure of a decision tree can be leveraged to build a probabilistic reconstruction of its training dataset, with the uncertainty of the reconstruction being a relevant metric for the information leak. In this paper, we propose of a novel framework generalizing these probabilistic reconstructions in the sense that it can handle other forms of interpretable models and more generic types of knowledge. In addition, we demonstrate that under realistic assumptions regarding the interpretable models' structure, the uncertainty of the reconstruction can be computed efficiently. Finally, we illustrate the applicability of our approach on both decision trees and rule lists, by comparing the theoretical information leak associated to either exact or heuristic learning algorithms. Our results suggest that optimal interpretable models are often more compact and leak less information regarding their training data than greedily-built ones, for a given accuracy level.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Interpretability is often seen as a key requirement for trustworthy machine learning, but releasing interpretable models can lead to privacy concerns.
- Previous work has shown that the structure of interpretable models like decision trees can be used to reconstruct the training data, which represents a privacy breach.
- This paper proposes a novel framework to quantify the privacy impact of releasing different types of interpretable models.
- The paper demonstrates that under realistic assumptions, the privacy loss can be computed efficiently for models like decision trees and rule lists.
- The results suggest that "optimal" interpretable models that balance accuracy and interpretability may leak less information about the training data compared to greedily-built models.
Plain English Explanation
Machine learning models are often expected to be "interpretable" - meaning we can understand how they make their predictions. This is important for building trust in the model's decisions. However, releasing an interpretable model can also reveal information about the data used to train it, which can be a privacy concern.
Imagine a hospital wants to use a decision tree model to help diagnose patients. The structure of the decision tree could potentially be used to infer details about the medical histories of the patients in the training data, even though their personal information is not directly included in the model.
This paper tackles the challenge of quantifying that privacy impact. The key insight is that the "uncertainty" in reconstructing the training data from the interpretable model gives us a way to measure how much information is being leaked. The more uncertain the reconstruction, the less information is disclosed.
The researchers developed a general framework to compute this privacy metric for different types of interpretable models, not just decision trees. They show that under realistic assumptions, this privacy loss can be efficiently calculated. Importantly, they find that "optimal" interpretable models that balance accuracy and interpretability tend to leak less information about the training data compared to simpler, greedily-built models.
Technical Explanation
This paper proposes a novel framework for quantifying the privacy impact of releasing interpretable machine learning models. The core idea is to measure the uncertainty in reconstructing the training data from the structure of the interpretable model.
Previous work has demonstrated this reconstruction process for decision trees, where the tree's branching decisions can be leveraged to build a probabilistic model of the original training instances. The uncertainty in this reconstruction, captured through metrics like entropy, provides a way to assess the information leakage.
The key contribution of this paper is generalizing this approach to handle other forms of interpretable models beyond just decision trees. The framework can be applied to models that encode different types of "knowledge," such as rule lists or prototypes.
Additionally, the paper shows that under realistic assumptions about the structure of the interpretable models, the privacy loss can be computed efficiently. This is an important practical consideration, as it makes the privacy analysis tractable.
To demonstrate the approach, the authors apply it to both decision trees and rule lists. They compare the theoretical information leakage for these models when learned using exact vs. heuristic algorithms. The results indicate that "optimal" interpretable models, which balance accuracy and interpretability, often have lower privacy loss than greedily-built models of similar accuracy.
Critical Analysis
The proposed framework represents a valuable contribution to the field of trustworthy machine learning. By providing a principled way to quantify the privacy impact of releasing interpretable models, it helps address an important challenge at the intersection of model transparency and data privacy.
That said, the assumptions and constraints of the analysis should be carefully considered. The efficient computation of the privacy loss relies on specific structural properties of the interpretable models, which may not hold in all real-world scenarios. Further research is needed to understand the robustness of the approach to model variations and alternative reconstruction techniques.
Additionally, the paper focuses on a specific type of privacy breach, where the training data is reconstructed from the model structure. Other forms of information leakage, such as membership inference attacks or model inversion, are not addressed. Exploring the interplay between these different privacy risks would be an important direction for future work.
Finally, while the results suggest "optimal" interpretable models may have lower privacy loss, the authors do not provide guidance on how to actually find such models in practice. Developing model selection or regularization techniques to balance interpretability, accuracy, and privacy would be a valuable next step.
Conclusion
This paper tackles an important challenge in trustworthy machine learning by proposing a framework to quantify the privacy impact of releasing interpretable models. By measuring the uncertainty in reconstructing training data from model structure, the approach provides a principled way to assess information leakage.
The efficient computation of this privacy metric, as well as the insights about the relative privacy of "optimal" interpretable models, represent significant technical advances. However, the assumptions and scope of the analysis suggest the need for further research to broaden the applicability and robustness of the approach.
Nonetheless, this work contributes valuable foundations for developing interpretable machine learning systems that can balance transparency and privacy - a critical requirement for the responsible deployment of these technologies in sensitive domains like healthcare and finance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Interpretable Representations in Explainable AI: From Theory to Practice
Kacper Sokol, Peter Flach
0
0
Interpretable representations are the backbone of many explainers that target black-box predictive systems based on artificial intelligence and machine learning algorithms. They translate the low-level data representation necessary for good predictive performance into high-level human-intelligible concepts used to convey the explanatory insights. Notably, the explanation type and its cognitive complexity are directly controlled by the interpretable representation, tweaking which allows to target a particular audience and use case. However, many explainers built upon interpretable representations overlook their merit and fall back on default solutions that often carry implicit assumptions, thereby degrading the explanatory power and reliability of such techniques. To address this problem, we study properties of interpretable representations that encode presence and absence of human-comprehensible concepts. We demonstrate how they are operationalised for tabular, image and text data; discuss their assumptions, strengths and weaknesses; identify their core building blocks; and scrutinise their configuration and parameterisation. In particular, this in-depth analysis allows us to pinpoint their explanatory properties, desiderata and scope for (malicious) manipulation in the context of tabular data where a linear model is used to quantify the influence of interpretable concepts on a black-box prediction. Our findings lead to a range of recommendations for designing trustworthy interpretable representations; specifically, the benefits of class-aware (supervised) discretisation of tabular data, e.g., with decision trees, and sensitivity of image interpretable representations to segmentation granularity and occlusion colour.
4/29/2024
New!Data Science Principles for Interpretable and Explainable AI
Kris Sankaran
0
0
Society's capacity for algorithmic problem-solving has never been greater. Artificial Intelligence is now applied across more domains than ever, a consequence of powerful abstractions, abundant data, and accessible software. As capabilities have expanded, so have risks, with models often deployed without fully understanding their potential impacts. Interpretable and interactive machine learning aims to make complex models more transparent and controllable, enhancing user agency. This review synthesizes key principles from the growing literature in this field. We first introduce precise vocabulary for discussing interpretability, like the distinction between glass box and explainable algorithms. We then explore connections to classical statistical and design principles, like parsimony and the gulfs of interaction. Basic explainability techniques -- including learned embeddings, integrated gradients, and concept bottlenecks -- are illustrated with a simple case study. We also review criteria for objectively evaluating interpretability approaches. Throughout, we underscore the importance of considering audience goals when designing interactive algorithmic systems. Finally, we outline open challenges and discuss the potential role of data science in addressing them. Code to reproduce all examples can be found at https://go.wisc.edu/3k1ewe.
5/20/2024
🔮
Topological Interpretability for Deep-Learning
Adam Spannaus, Heidi A. Hanson, Lynne Penberthy, Georgia Tourassi
0
0
With the growing adoption of AI-based systems across everyday life, the need to understand their decision-making mechanisms is correspondingly increasing. The level at which we can trust the statistical inferences made from AI-based decision systems is an increasing concern, especially in high-risk systems such as criminal justice or medical diagnosis, where incorrect inferences may have tragic consequences. Despite their successes in providing solutions to problems involving real-world data, deep learning (DL) models cannot quantify the certainty of their predictions. These models are frequently quite confident, even when their solutions are incorrect. This work presents a method to infer prominent features in two DL classification models trained on clinical and non-clinical text by employing techniques from topological and geometric data analysis. We create a graph of a model's feature space and cluster the inputs into the graph's vertices by the similarity of features and prediction statistics. We then extract subgraphs demonstrating high-predictive accuracy for a given label. These subgraphs contain a wealth of information about features that the DL model has recognized as relevant to its decisions. We infer these features for a given label using a distance metric between probability measures, and demonstrate the stability of our method compared to the LIME and SHAP interpretability methods. This work establishes that we may gain insights into the decision mechanism of a DL model. This method allows us to ascertain if the model is making its decisions based on information germane to the problem or identifies extraneous patterns within the data.
4/15/2024
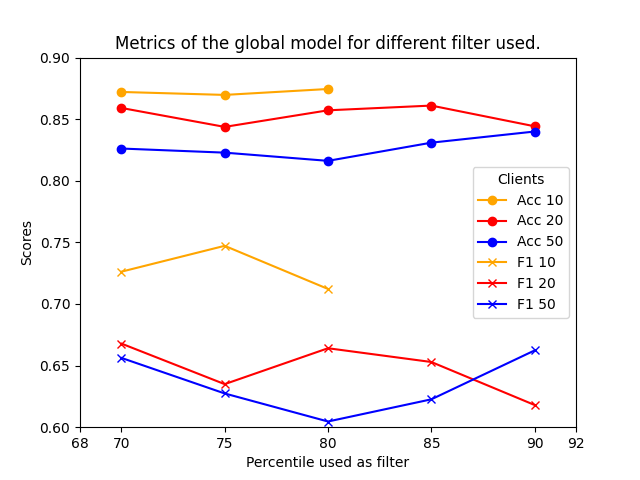
An Interpretable Client Decision Tree Aggregation process for Federated Learning
Alberto Argente-Garrido, Cristina Zuheros, M. Victoria Luz'on, Francisco Herrera
0
0
Trustworthy Artificial Intelligence solutions are essential in today's data-driven applications, prioritizing principles such as robustness, safety, transparency, explainability, and privacy among others. This has led to the emergence of Federated Learning as a solution for privacy and distributed machine learning. While decision trees, as self-explanatory models, are ideal for collaborative model training across multiple devices in resource-constrained environments such as federated learning environments for injecting interpretability in these models. Decision tree structure makes the aggregation in a federated learning environment not trivial. They require techniques that can merge their decision paths without introducing bias or overfitting while keeping the aggregated decision trees robust and generalizable. In this paper, we propose an Interpretable Client Decision Tree Aggregation process for Federated Learning scenarios that keeps the interpretability and the precision of the base decision trees used for the aggregation. This model is based on aggregating multiple decision paths of the decision trees and can be used on different decision tree types, such as ID3 and CART. We carry out the experiments within four datasets, and the analysis shows that the tree built with the model improves the local models, and outperforms the state-of-the-art.
4/4/2024