Interpreting the Weight Space of Customized Diffusion Models

0
Sign in to get full access
Overview
- The paper explores interpreting the weight space of customized diffusion models, which are powerful generative models used for tasks like image synthesis.
- It aims to provide insights into how these models learn and represent information, which can help improve their performance and interpretability.
- The research involves analyzing the weight space of diffusion models to understand what aspects of the data they capture and how this knowledge can be leveraged.
Plain English Explanation
Diffusion models are a type of artificial intelligence that can generate new images from scratch. They work by learning patterns in a large dataset of images, and then using that knowledge to create entirely new images that look similar to the ones in the dataset.
However, it's not always clear how these diffusion models are actually learning and representing the information in the images. This paper aims to shed light on this by closely examining the "weight space" of the diffusion model - that is, the internal parameters and structures that allow the model to produce new images.
By analyzing the weight space, the researchers hope to gain insights into what aspects of the image data the diffusion model is focusing on and prioritizing. This could then help improve the performance and interpretability of these powerful generative models, making them even more useful for tasks like synthetic face generation or discovering new semantic directions in the latent space.
Technical Explanation
The paper presents a detailed analysis of the weight space of customized diffusion models. The researchers trained several diffusion models on various image datasets, then examined the learned weights and parameters to understand how the models were representing the data.
Key experiments and insights include:
- Visualizing and analyzing the distribution of weights in the diffusion model's neural networks, revealing patterns and structures that correspond to different image features.
- Probing the sensitivity of the model's outputs to changes in specific weights, allowing them to identify which parts of the weight space are most influential for generating certain types of images.
- Exploring the latent space of the diffusion models and how it relates to the weight space, providing clues about how the models are learning to represent the underlying image data.
- Investigating the geometric and hyperbolic properties of the weight space, which can shed light on the inductive biases and learned representations of the diffusion models.
Overall, this work offers a novel approach to interpreting the inner workings of complex generative models like diffusion, with the goal of making them more transparent and controllable for a variety of applications.
Critical Analysis
The paper presents a thorough and rigorous analysis of the weight space of customized diffusion models, providing valuable insights into how these models learn and represent image data. However, the authors acknowledge that their findings are limited to the specific models and datasets they examined, and that further research is needed to generalize the conclusions.
Additionally, while the analysis uncovers interesting patterns and structures in the weight space, the practical implications for improving diffusion model performance or interpretability are not yet fully clear. The authors suggest potential avenues for future work, such as leveraging the weight space insights to guide model architecture design or enable more fine-grained control over generation, but these ideas require further exploration and validation.
Another potential limitation is that the weight space analysis is inherently complex and may be difficult for non-expert readers to fully comprehend. The authors make a commendable effort to present the findings in an accessible way, but the technical nature of the work may still pose a barrier for some audiences.
Overall, this paper represents a valuable contribution to the understanding of diffusion models, and the proposed techniques could serve as a foundation for future research aimed at making these powerful generative models more interpretable and controllable.
Conclusion
The paper "Interpreting the Weight Space of Customized Diffusion Models" presents a detailed analysis of the internal structure and representations learned by diffusion models, a class of powerful generative AI systems. By closely examining the weight space of these models, the researchers uncover insights into how they learn to capture and reproduce the patterns in image data.
This work offers a novel approach to interpreting the inner workings of complex generative models, which could lead to improved performance, transparency, and control over their outputs. While the findings are limited to the specific models and datasets studied, the techniques and insights presented in this paper lay the groundwork for future research aimed at making diffusion models and other generative AI systems more accessible, interpretable, and beneficial for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Interpreting the Weight Space of Customized Diffusion Models
Amil Dravid, Yossi Gandelsman, Kuan-Chieh Wang, Rameen Abdal, Gordon Wetzstein, Alexei A. Efros, Kfir Aberman
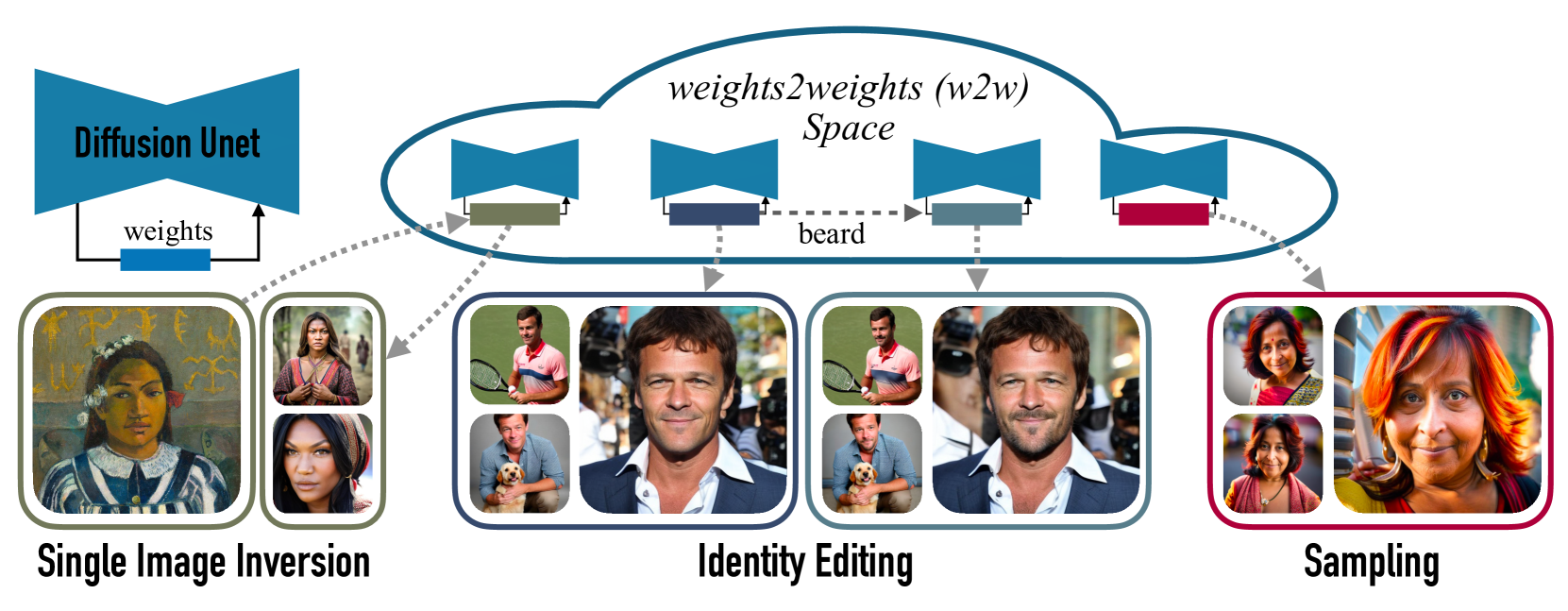
We investigate the space of weights spanned by a large collection of customized diffusion models. We populate this space by creating a dataset of over 60,000 models, each of which is a base model fine-tuned to insert a different person's visual identity. We model the underlying manifold of these weights as a subspace, which we term weights2weights. We demonstrate three immediate applications of this space -- sampling, editing, and inversion. First, as each point in the space corresponds to an identity, sampling a set of weights from it results in a model encoding a novel identity. Next, we find linear directions in this space corresponding to semantic edits of the identity (e.g., adding a beard). These edits persist in appearance across generated samples. Finally, we show that inverting a single image into this space reconstructs a realistic identity, even if the input image is out of distribution (e.g., a painting). Our results indicate that the weight space of fine-tuned diffusion models behaves as an interpretable latent space of identities.
Read more7/19/2024

0
Exploring Low-Dimensional Subspaces in Diffusion Models for Controllable Image Editing
Siyi Chen, Huijie Zhang, Minzhe Guo, Yifu Lu, Peng Wang, Qing Qu
Recently, diffusion models have emerged as a powerful class of generative models. Despite their success, there is still limited understanding of their semantic spaces. This makes it challenging to achieve precise and disentangled image generation without additional training, especially in an unsupervised way. In this work, we improve the understanding of their semantic spaces from intriguing observations: among a certain range of noise levels, (1) the learned posterior mean predictor (PMP) in the diffusion model is locally linear, and (2) the singular vectors of its Jacobian lie in low-dimensional semantic subspaces. We provide a solid theoretical basis to justify the linearity and low-rankness in the PMP. These insights allow us to propose an unsupervised, single-step, training-free LOw-rank COntrollable image editing (LOCO Edit) method for precise local editing in diffusion models. LOCO Edit identified editing directions with nice properties: homogeneity, transferability, composability, and linearity. These properties of LOCO Edit benefit greatly from the low-dimensional semantic subspace. Our method can further be extended to unsupervised or text-supervised editing in various text-to-image diffusion models (T-LOCO Edit). Finally, extensive empirical experiments demonstrate the effectiveness and efficiency of LOCO Edit. The codes will be released at https://github.com/ChicyChen/LOCO-Edit.
Read more9/12/2024
🎯
0
Generalised Diffusion Probabilistic Scale-Spaces
Pascal Peter
Diffusion probabilistic models excel at sampling new images from learned distributions. Originally motivated by drift-diffusion concepts from physics, they apply image perturbations such as noise and blur in a forward process that results in a tractable probability distribution. A corresponding learned reverse process generates images and can be conditioned on side information, which leads to a wide variety of practical applications. Most of the research focus currently lies on practice-oriented extensions. In contrast, the theoretical background remains largely unexplored, in particular the relations to drift-diffusion. In order to shed light on these connections to classical image filtering, we propose a generalised scale-space theory for diffusion probabilistic models. Moreover, we show conceptual and empirical connections to diffusion and osmosis filters.
Read more6/7/2024

0
Diffusion Models Learn Low-Dimensional Distributions via Subspace Clustering
Peng Wang, Huijie Zhang, Zekai Zhang, Siyi Chen, Yi Ma, Qing Qu
Recent empirical studies have demonstrated that diffusion models can effectively learn the image distribution and generate new samples. Remarkably, these models can achieve this even with a small number of training samples despite a large image dimension, circumventing the curse of dimensionality. In this work, we provide theoretical insights into this phenomenon by leveraging key empirical observations: (i) the low intrinsic dimensionality of image data, (ii) a union of manifold structure of image data, and (iii) the low-rank property of the denoising autoencoder in trained diffusion models. These observations motivate us to assume the underlying data distribution of image data as a mixture of low-rank Gaussians and to parameterize the denoising autoencoder as a low-rank model according to the score function of the assumed distribution. With these setups, we rigorously show that optimizing the training loss of diffusion models is equivalent to solving the canonical subspace clustering problem over the training samples. Based on this equivalence, we further show that the minimal number of samples required to learn the underlying distribution scales linearly with the intrinsic dimensions under the above data and model assumptions. This insight sheds light on why diffusion models can break the curse of dimensionality and exhibit the phase transition in learning distributions. Moreover, we empirically establish a correspondence between the subspaces and the semantic representations of image data, facilitating image editing. We validate these results with corroborated experimental results on both simulated distributions and image datasets.
Read more9/5/2024