Inverse Constitutional AI: Compressing Preferences into Principles

0

Sign in to get full access
Overview
- This paper introduces the concept of "Inverse Constitutional AI," which aims to compress complex preferences into a set of guiding principles.
- The authors propose a method to extract these principles from human preferences, allowing for the development of AI systems that align with human values.
- The paper explores the challenges and potential solutions in the inverse constitutional AI problem, highlighting the importance of aligning AI systems with human preferences.
Plain English Explanation
The paper discusses a new approach called "Inverse Constitutional AI" that tries to take complex human preferences and distill them down into a set of guiding principles. The idea is that if we can capture the core values and principles that underlie human preferences, we can then use those to design AI systems that are better aligned with what humans actually want.
The challenge is that human preferences can be messy, inconsistent, and hard to precisely define. The authors propose a method to extract these underlying principles from the preferences. This could allow us to create AI systems that don't just blindly follow instructions, but instead have a deeper understanding of human values and can make decisions that are truly aligned with what we care about.
This is an important problem because as AI systems become more advanced, it's critical that they behave in ways that are beneficial to humanity. [Linking to https://aimodels.fyi/papers/arxiv/whose-preferences-differences-fairness-preferences-their-impact] If the AI's goals and decision-making don't match up with human preferences, it could lead to unintended and potentially harmful consequences. [Linking to https://aimodels.fyi/papers/arxiv/social-choice-should-guide-ai-alignment-dealing]
By figuring out how to extract the fundamental principles behind human preferences, the authors hope to pave the way for a new generation of AI systems that are truly aligned with what we value as humans. [Linking to https://aimodels.fyi/papers/arxiv/understanding-evaluating-human-preferences-ai-generated-images, https://aimodels.fyi/papers/arxiv/aligning-large-language-models-self-generated-preference, https://aimodels.fyi/papers/arxiv/aligning-llm-agents-by-learning-latent-preference]
Technical Explanation
The paper introduces the "Inverse Constitutional AI" problem, which seeks to extract a set of guiding principles from complex human preferences. The authors propose a method to achieve this by framing it as an optimization problem, where the goal is to find the set of principles that best captures the underlying preferences.
The key insight is that human preferences can be thought of as a "constitution" - a set of high-level rules or guidelines that should govern the behavior of an AI system. Just as a country's constitution lays out the fundamental principles that shape its laws and policies, the authors aim to discover the constitutional principles that should guide an AI's decision-making.
To do this, the paper introduces a novel architecture that learns these principles from examples of human preferences. The architecture includes a preference modeling component that captures the nuances of the preferences, and a principle extraction component that distills this information into a concise set of guiding principles.
The authors test their approach on a range of simulated preference domains, demonstrating that the extracted principles can effectively capture the essence of the original preferences. They also discuss the challenges involved, such as dealing with inconsistencies or ambiguities in the preference data, and propose potential solutions.
Critical Analysis
The authors' approach to Inverse Constitutional AI is an intriguing and ambitious attempt to tackle the fundamental challenge of aligning AI systems with human values. By focusing on extracting guiding principles rather than just mimicking preferences, the method holds promise for creating AI that is more robust and adaptable.
However, the paper also acknowledges several key limitations and areas for further research. For example, the proposed architecture has only been tested on simulated preference domains, and it remains to be seen how well it would scale to the full complexity of real-world human preferences. [Linking to https://aimodels.fyi/papers/arxiv/whose-preferences-differences-fairness-preferences-their-impact]
Additionally, the paper does not address the thorny issue of how to resolve conflicts or trade-offs between different extracted principles. In practice, human values can be highly context-dependent and sometimes contradictory, so developing a rigorous framework for principle-based decision-making will be crucial. [Linking to https://aimodels.fyi/papers/arxiv/social-choice-should-guide-ai-alignment-dealing]
Further research is also needed to understand the potential biases and blindspots that could arise in the principle extraction process. If the underlying preference data is skewed or incomplete, the resulting principles may not fully capture the breadth of human values. [Linking to https://aimodels.fyi/papers/arxiv/understanding-evaluating-human-preferences-ai-generated-images]
Despite these challenges, the Inverse Constitutional AI approach represents an important step towards the long-term goal of aligning advanced AI systems with human preferences. By focusing on the deeper principles that shape our values, rather than just the surface-level preferences, the authors have opened up a promising new avenue for AI alignment research.
Conclusion
The paper on "Inverse Constitutional AI" introduces a novel approach to the challenge of aligning AI systems with human values. By framing the problem as one of extracting a set of guiding principles from complex preferences, the authors propose a method that could lead to more robust and adaptable AI that truly reflects what humans care about.
While the proposed architecture has limitations and requires further research, the core idea of Inverse Constitutional AI represents an important step forward in the field of AI alignment. As AI systems continue to grow in capability and influence, developing principled methods for imbuing them with human values will be crucial to ensuring that they have a positive impact on the world. [Linking to https://aimodels.fyi/papers/arxiv/aligning-large-language-models-self-generated-preference, https://aimodels.fyi/papers/arxiv/aligning-llm-agents-by-learning-latent-preference]
The authors' work opens up new avenues for exploring how to create AI that is not just obedient, but truly aligned with the deeper principles that define the human experience. By continuing to build on this foundation, the research community can work towards the development of AI systems that are beneficial, trustworthy, and aligned with our shared values as a society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Inverse Constitutional AI: Compressing Preferences into Principles
Arduin Findeis, Timo Kaufmann, Eyke Hullermeier, Samuel Albanie, Robert Mullins
Feedback data plays an important role in fine-tuning and evaluating state-of-the-art AI models. Often pairwise text preferences are used: given two texts, human (or AI) annotators select the better one. Such feedback data is widely used to align models to human preferences (e.g., reinforcement learning from human feedback), or to rank models according to human preferences (e.g., Chatbot Arena). Despite its wide-spread use, prior work has demonstrated that human-annotated pairwise text preference data often exhibits unintended biases. For example, human annotators have been shown to prefer assertive over truthful texts in certain contexts. Models trained or evaluated on this data may implicitly encode these biases in a manner hard to identify. In this paper, we formulate the interpretation of existing pairwise text preference data as a compression task: the Inverse Constitutional AI (ICAI) problem. In constitutional AI, a set of principles (or constitution) is used to provide feedback and fine-tune AI models. The ICAI problem inverts this process: given a dataset of feedback, we aim to extract a constitution that best enables a large language model (LLM) to reconstruct the original annotations. We propose a corresponding initial ICAI algorithm and validate its generated constitutions quantitatively based on reconstructed annotations. Generated constitutions have many potential use-cases -- they may help identify undesirable biases, scale feedback to unseen data or assist with adapting LLMs to individual user preferences. We demonstrate our approach on a variety of datasets: (a) synthetic feedback datasets with known underlying principles; (b) the AlpacaEval dataset of cross-annotated human feedback; and (c) the crowdsourced Chatbot Arena data set. We release the code for our algorithm and experiments at https://github.com/rdnfn/icai .
Read more6/12/2024
0
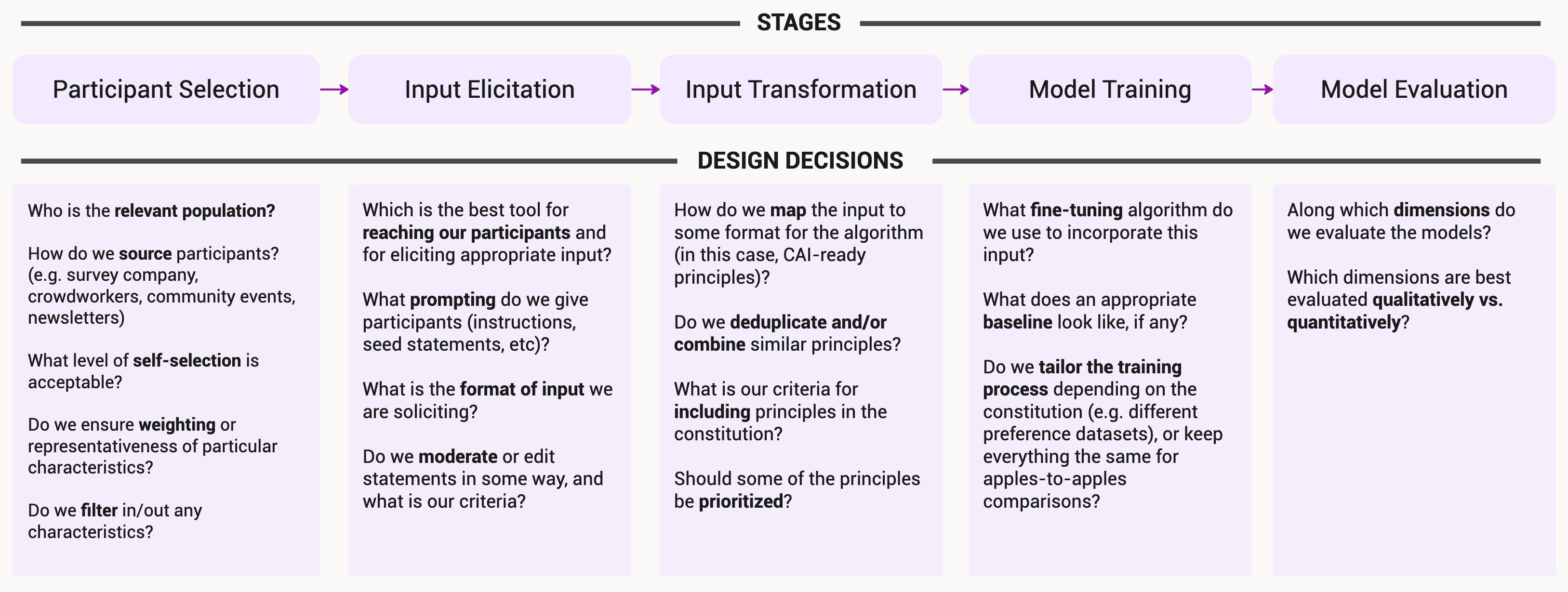
Collective Constitutional AI: Aligning a Language Model with Public Input
Saffron Huang, Divya Siddarth, Liane Lovitt, Thomas I. Liao, Esin Durmus, Alex Tamkin, Deep Ganguli
There is growing consensus that language model (LM) developers should not be the sole deciders of LM behavior, creating a need for methods that enable the broader public to collectively shape the behavior of LM systems that affect them. To address this need, we present Collective Constitutional AI (CCAI): a multi-stage process for sourcing and integrating public input into LMs-from identifying a target population to sourcing principles to training and evaluating a model. We demonstrate the real-world practicality of this approach by creating what is, to our knowledge, the first LM fine-tuned with collectively sourced public input and evaluating this model against a baseline model trained with established principles from a LM developer. Our quantitative evaluations demonstrate several benefits of our approach: the CCAI-trained model shows lower bias across nine social dimensions compared to the baseline model, while maintaining equivalent performance on language, math, and helpful-harmless evaluations. Qualitative comparisons of the models suggest that the models differ on the basis of their respective constitutions, e.g., when prompted with contentious topics, the CCAI-trained model tends to generate responses that reframe the matter positively instead of a refusal. These results demonstrate a promising, tractable pathway toward publicly informed development of language models.
Read more6/13/2024
0
Aligning Large Language Models from Self-Reference AI Feedback with one General Principle
Rong Bao, Rui Zheng, Shihan Dou, Xiao Wang, Enyu Zhou, Bo Wang, Qi Zhang, Liang Ding, Dacheng Tao
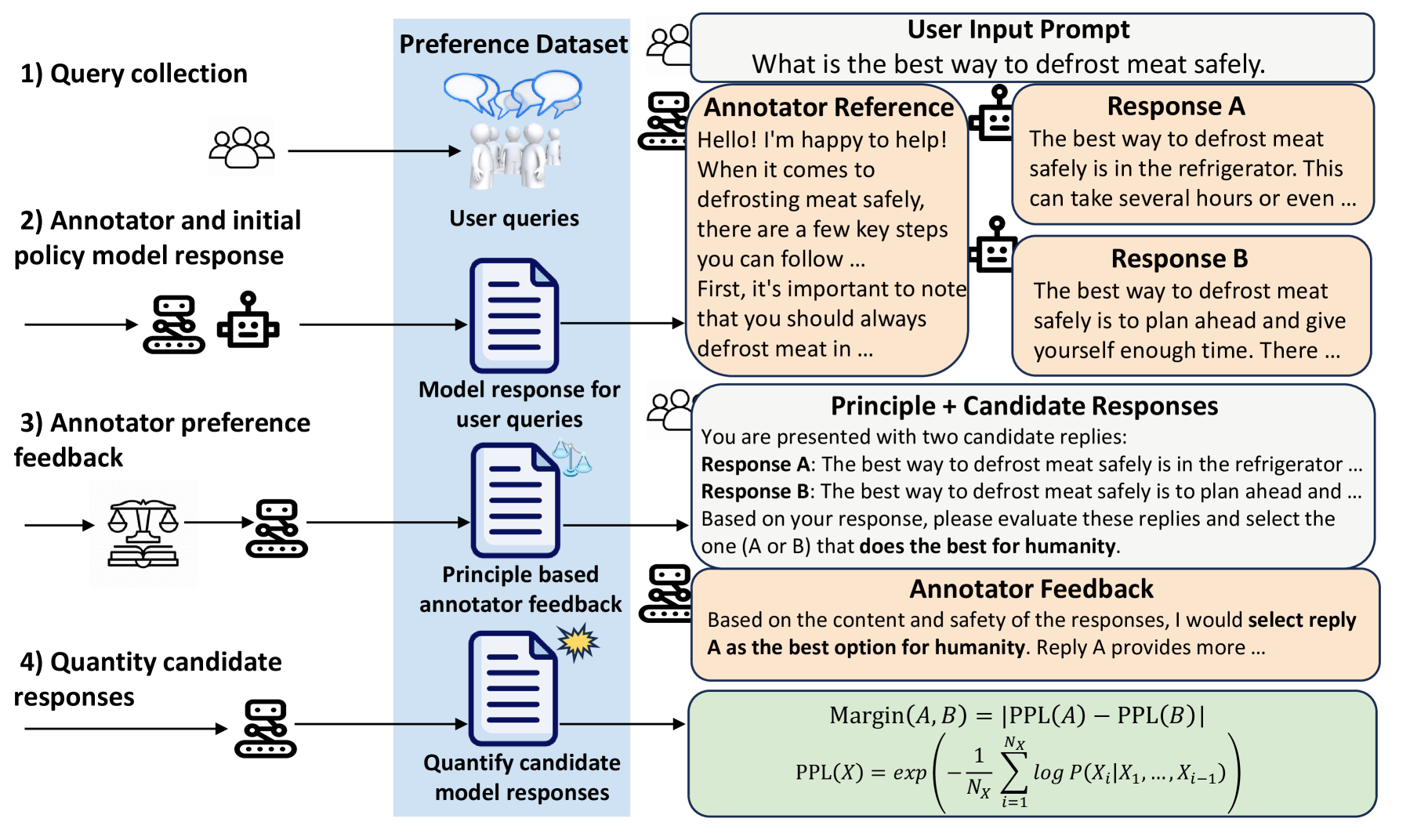
In aligning large language models (LLMs), utilizing feedback from existing advanced AI rather than humans is an important method to scale supervisory signals. However, it is highly challenging for AI to understand human intentions and societal values, and provide accurate preference feedback based on these. Current AI feedback methods rely on powerful LLMs, carefully designed specific principles to describe human intentions, and are easily influenced by position bias. To address these issues, we propose a self-reference-based AI feedback framework that enables a 13B Llama2-Chat to provide high-quality feedback under simple and general principles such as ``best for humanity``. Specifically, we allow the AI to first respond to the user's instructions, then generate criticism of other answers based on its own response as a reference, and finally determine which answer better fits human preferences according to the criticism. Additionally, we use a self-consistency method to further reduce the impact of position bias, and employ semantic perplexity to calculate the preference strength differences between different answers. Experimental results show that our method enables 13B and 70B Llama2-Chat annotators to provide high-quality preference feedback, and the policy models trained based on these preference data achieve significant advantages in benchmark datasets through reinforcement learning.
Read more6/18/2024

0
Whose Preferences? Differences in Fairness Preferences and Their Impact on the Fairness of AI Utilizing Human Feedback
Emilia Agis Lerner, Florian E. Dorner, Elliott Ash, Naman Goel
There is a growing body of work on learning from human feedback to align various aspects of machine learning systems with human values and preferences. We consider the setting of fairness in content moderation, in which human feedback is used to determine how two comments -- referencing different sensitive attribute groups -- should be treated in comparison to one another. With a novel dataset collected from Prolific and MTurk, we find significant gaps in fairness preferences depending on the race, age, political stance, educational level, and LGBTQ+ identity of annotators. We also demonstrate that demographics mentioned in text have a strong influence on how users perceive individual fairness in moderation. Further, we find that differences also exist in downstream classifiers trained to predict human preferences. Finally, we observe that an ensemble, giving equal weight to classifiers trained on annotations from different demographics, performs better for different demographic intersections; compared to a single classifier that gives equal weight to each annotation.
Read more6/11/2024