Aligning Large Language Models from Self-Reference AI Feedback with one General Principle
2406.11190
0
0
Abstract
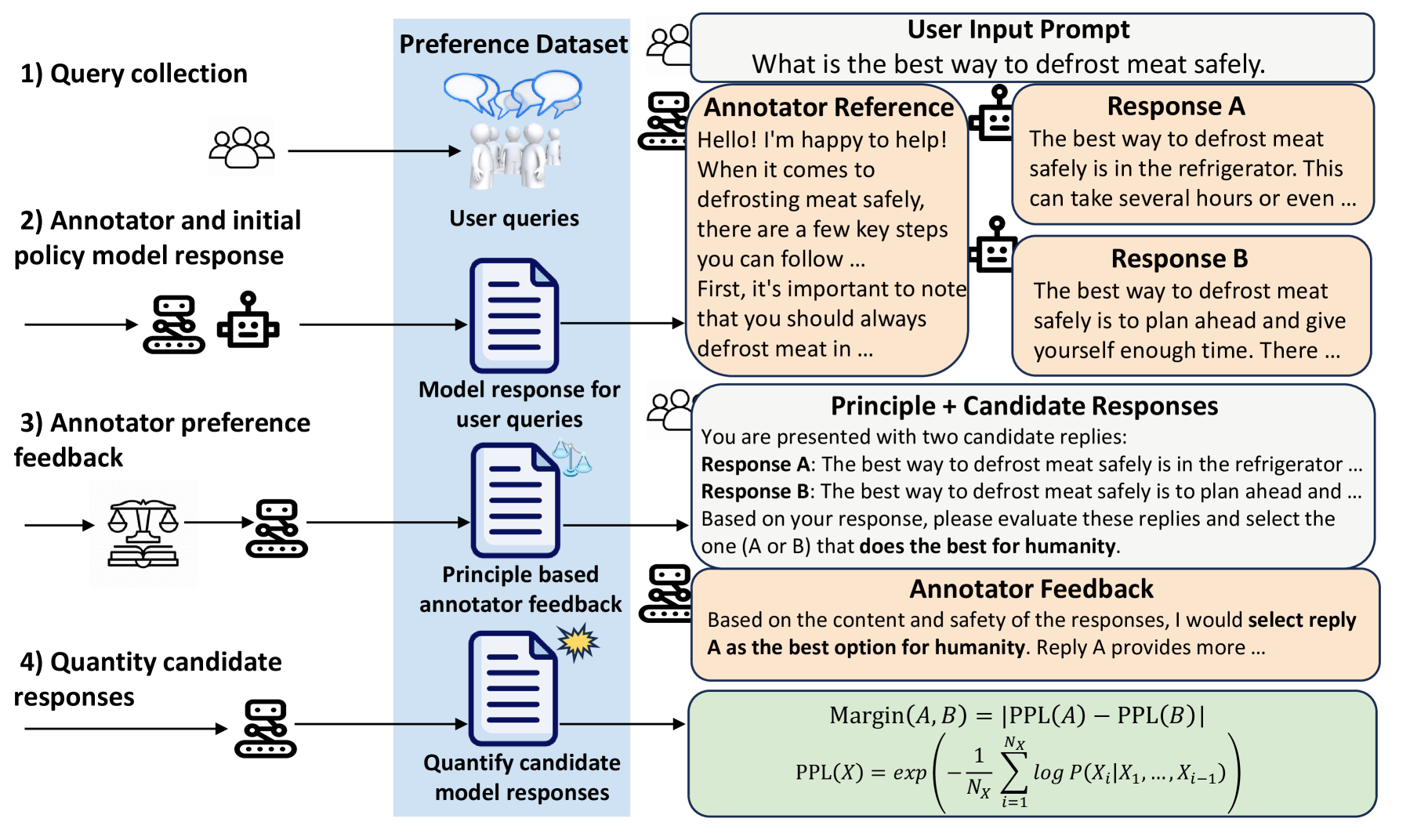
In aligning large language models (LLMs), utilizing feedback from existing advanced AI rather than humans is an important method to scale supervisory signals. However, it is highly challenging for AI to understand human intentions and societal values, and provide accurate preference feedback based on these. Current AI feedback methods rely on powerful LLMs, carefully designed specific principles to describe human intentions, and are easily influenced by position bias. To address these issues, we propose a self-reference-based AI feedback framework that enables a 13B Llama2-Chat to provide high-quality feedback under simple and general principles such as best for humanity. Specifically, we allow the AI to first respond to the user's instructions, then generate criticism of other answers based on its own response as a reference, and finally determine which answer better fits human preferences according to the criticism. Additionally, we use a self-consistency method to further reduce the impact of position bias, and employ semantic perplexity to calculate the preference strength differences between different answers. Experimental results show that our method enables 13B and 70B Llama2-Chat annotators to provide high-quality preference feedback, and the policy models trained based on these preference data achieve significant advantages in benchmark datasets through reinforcement learning.
Create account to get full access
Overview
- This paper explores a new approach to aligning large language models with human preferences using a single general principle called "self-reference AI feedback."
- The researchers develop a training method that encourages the language model to optimize for its own future performance on self-generated tasks, rather than simply maximizing the likelihood of its training data.
- This approach is proposed as a way to create language models that are more aligned with human values and preferences, without the need for complex reward modeling or extensive fine-tuning.
Plain English Explanation
The researchers in this paper are trying to find a better way to make large language models, like the ones used in chatbots and virtual assistants, behave in a way that is more aligned with human values and preferences. Typical training methods for these models often lead to undesirable or even harmful outputs, as the models simply try to maximize the likelihood of their training data without a deep understanding of human preferences.
The key insight in this paper is to train the language model to optimize for its own future performance on self-generated tasks, rather than just predicting the next word in a sequence. This approach, called "self-reference AI feedback," is proposed as a way to create models that are more inherently aligned with human values, without the need for complex reward modeling or extensive fine-tuning.
The researchers develop a training procedure where the model is rewarded for generating sequences that it can then accurately predict or "understand" itself. This encourages the model to develop an understanding of its own capabilities and limitations, and to generate outputs that are coherent and meaningful, rather than just statistically likely.
Technical Explanation
The core technical contribution of this paper is a training procedure for large language models that leverages "self-reference AI feedback." The key steps are:
- Train the language model on a standard corpus of textual data using maximum likelihood estimation, as is typical for these models.
- Introduce a second "self-reference" task, where the model is asked to generate a sequence of text and then predict or "understand" that same sequence.
- During training, the model is rewarded not only for accurately predicting the next word in the sequence (as in standard language modeling), but also for accurately predicting its own generated sequence.
This encourages the model to develop an internal understanding of its own capabilities and limitations, and to generate outputs that are coherent and meaningful, rather than just statistically likely. The authors demonstrate that this approach can lead to language models that are more aligned with human preferences, as measured by various evaluation tasks.
[The self-reference training procedure is inspired by work on learning reward functions for robotic skills and aligning language models with human preferences, but applies it to the specific context of large language models.]
Critical Analysis
The self-reference AI feedback approach proposed in this paper is a promising step towards creating language models that are more aligned with human values and preferences. By encouraging the model to develop an internal understanding of its own capabilities and limitations, the authors argue that it can produce more coherent and meaningful outputs.
However, the paper does not address several important limitations and caveats. For example, it is unclear how well this approach would scale to larger, more complex language models, or how it would perform on tasks that require a deep understanding of the world beyond just self-reference. Additionally, the paper does not explore the potential for unintended consequences or failure modes, such as the model becoming overly focused on its own self-evaluation at the expense of other important objectives.
Further research is needed to fully understand the strengths and weaknesses of this approach, and to explore ways to combine it with other techniques for aligning language models with human values, such as fine-grained control of model outputs or learning reward functions from human feedback. Ultimately, creating language models that are truly aligned with human values remains a significant challenge, and this paper represents an interesting step in that direction.
Conclusion
This paper presents a novel approach to aligning large language models with human preferences, using a training procedure based on "self-reference AI feedback." By encouraging the model to optimize for its own future performance on self-generated tasks, the authors argue that it can develop a more coherent and meaningful internal representation, leading to outputs that are better aligned with human values.
While this approach shows promise, the paper also highlights the significant challenges involved in creating language models that are truly aligned with human preferences. Further research is needed to better understand the strengths, limitations, and potential unintended consequences of this approach, and to explore ways to combine it with other techniques for aligning language models with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Aligning Large Language Models with Self-generated Preference Data
Dongyoung Kim, Kimin Lee, Jinwoo Shin, Jaehyung Kim
0
0
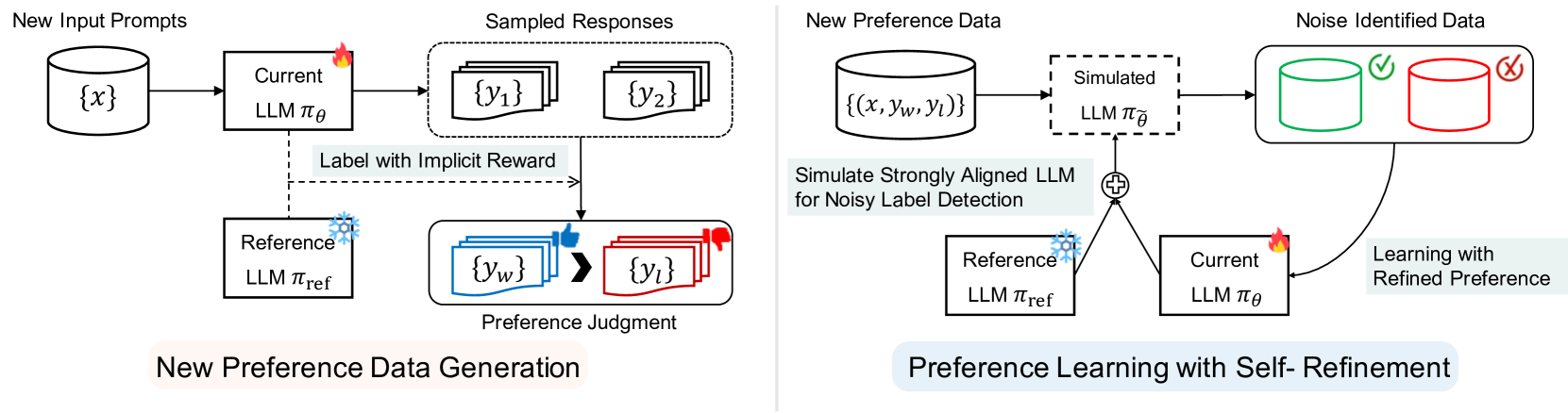
Aligning large language models (LLMs) with human preferences becomes a key component to obtaining state-of-the-art performance, but it yields a huge cost to construct a large human-annotated preference dataset. To tackle this problem, we propose a new framework that boosts the alignment of LLMs through Self-generated Preference data (Selfie) using only a very small amount of human-annotated preference data. Our key idea is leveraging the human prior knowledge within the small (seed) data and progressively improving the alignment of LLM, by iteratively generating the responses and learning from them with the self-annotated preference data. To be specific, we propose to derive the preference label from the logits of LLM to explicitly extract the model's inherent preference. Compared to the previous approaches using external reward models or implicit in-context learning, we observe that the proposed approach is significantly more effective. In addition, we introduce a noise-aware preference learning algorithm to mitigate the risk of low quality within generated preference data. Our experimental results demonstrate that the proposed framework significantly boosts the alignment of LLMs. For example, we achieve superior alignment performance on AlpacaEval 2.0 with only 3.3% of the ground-truth preference labels in the Ultrafeedback data compared to the cases using the entire data or state-of-the-art baselines.
6/10/2024
📈
Pride and Prejudice: LLM Amplifies Self-Bias in Self-Refinement
Wenda Xu, Guanglei Zhu, Xuandong Zhao, Liangming Pan, Lei Li, William Yang Wang
0
0
Recent studies show that large language models (LLMs) improve their performance through self-feedback on certain tasks while degrade on others. We discovered that such a contrary is due to LLM's bias in evaluating their own output. In this paper, we formally define LLM's self-bias - the tendency to favor its own generation - using two statistics. We analyze six LLMs (GPT-4, GPT-3.5, Gemini, LLaMA2, Mixtral and DeepSeek) on translation, constrained text generation, and mathematical reasoning tasks. We find that self-bias is prevalent in all examined LLMs across multiple languages and tasks. Our analysis reveals that while the self-refine pipeline improves the fluency and understandability of model outputs, it further amplifies self-bias. To mitigate such biases, we discover that larger model size and external feedback with accurate assessment can significantly reduce bias in the self-refine pipeline, leading to actual performance improvement in downstream tasks. The code and data are released at https://github.com/xu1998hz/llm_self_bias.
6/19/2024

Understanding the Learning Dynamics of Alignment with Human Feedback
Shawn Im, Yixuan Li
0
0
Aligning large language models (LLMs) with human intentions has become a critical task for safely deploying models in real-world systems. While existing alignment approaches have seen empirical success, theoretically understanding how these methods affect model behavior remains an open question. Our work provides an initial attempt to theoretically analyze the learning dynamics of human preference alignment. We formally show how the distribution of preference datasets influences the rate of model updates and provide rigorous guarantees on the training accuracy. Our theory also reveals an intricate phenomenon where the optimization is prone to prioritizing certain behaviors with higher preference distinguishability. We empirically validate our findings on contemporary LLMs and alignment tasks, reinforcing our theoretical insights and shedding light on considerations for future alignment approaches. Disclaimer: This paper contains potentially offensive text; reader discretion is advised.
4/17/2024

Aligning Large Language Models via Fine-grained Supervision
Dehong Xu, Liang Qiu, Minseok Kim, Faisal Ladhak, Jaeyoung Do
0
0
Pre-trained large-scale language models (LLMs) excel at producing coherent articles, yet their outputs may be untruthful, toxic, or fail to align with user expectations. Current approaches focus on using reinforcement learning with human feedback (RLHF) to improve model alignment, which works by transforming coarse human preferences of LLM outputs into a feedback signal that guides the model learning process. However, because this approach operates on sequence-level feedback, it lacks the precision to identify the exact parts of the output affecting user preferences. To address this gap, we propose a method to enhance LLM alignment through fine-grained token-level supervision. Specifically, we ask annotators to minimally edit less preferred responses within the standard reward modeling dataset to make them more favorable, ensuring changes are made only where necessary while retaining most of the original content. The refined dataset is used to train a token-level reward model, which is then used for training our fine-grained Proximal Policy Optimization (PPO) model. Our experiment results demonstrate that this approach can achieve up to an absolute improvement of $5.1%$ in LLM performance, in terms of win rate against the reference model, compared with the traditional PPO model.
6/6/2024