Inverse Neural Rendering for Explainable Multi-Object Tracking

0

Sign in to get full access
Overview
- This paper introduces a novel inverse neural rendering approach for explainable multi-object tracking.
- The method combines neural rendering and 3D object detection to provide a more interpretable and transparent tracking system.
- The approach allows for better understanding of the tracking process and the factors influencing it.
Plain English Explanation
The paper describes a new way to track multiple objects in a video, such as cars or people, that is more transparent and easy to understand. Traditional object tracking systems can be like black boxes - it's hard to see how they're making their decisions. This new method, called inverse neural rendering, combines two key techniques: neural rendering and 3D object detection.
Neural rendering is a way to generate realistic images from abstract 3D models. By reversing this process, the system can start with the actual video frames and reconstruct the 3D models of the objects being tracked. This provides a clearer, more interpretable view of what the tracker is doing.
The 3D object detection component identifies the locations and shapes of the objects in each frame. Putting this together with the neural rendering, the system can show the user the 3D models of the objects being tracked and how they move over time. This makes the tracking process much more transparent and explainable, compared to a simple 2D bounding box approach.
The key innovation is that this inverse neural rendering method gives the user a better understanding of how the tracker is working, rather than just presenting the final results. This could be very valuable in applications where transparency and trust in the system are important, like self-driving cars or surveillance systems.
Technical Explanation
The paper proposes an "Inverse Neural Rendering for Explainable Multi-Object Tracking" approach, which combines neural rendering and 3D object detection to provide a more interpretable and transparent multi-object tracking system.
The core idea is to leverage neural rendering to reconstruct the 3D scene and object models from the video frames, rather than just outputting 2D bounding boxes. This inverse neural rendering process allows the system to explicitly model the 3D structure of the scene and the tracked objects.
The method first uses a 3D object detection module to identify the locations and shapes of objects in each frame. It then employs a neural rendering pipeline to generate photo-realistic renderings of the scene based on the 3D object models. By comparing the rendered images to the original frames, the system can refine the 3D object representations and track their movements over time.
Crucially, this approach provides the user with an interpretable 3D representation of the tracked objects, rather than just opaque 2D detections. The authors demonstrate that this leads to better understanding of the tracking process and the factors influencing it, compared to traditional tracking-by-detection methods.
The paper evaluates the inverse neural rendering tracker on several multi-object tracking benchmarks, showing competitive performance against state-of-the-art methods. The authors also conduct ablation studies to analyze the contributions of the key components of their approach.
Critical Analysis
The inverse neural rendering approach presented in this paper offers a promising direction for making multi-object tracking systems more transparent and explainable. By reconstructing 3D object models from the video, the method provides users with a clearer view of the tracking process, which could be valuable in safety-critical applications.
However, the paper does not fully address the computational complexity and efficiency of the inverse rendering pipeline, which could be a limitation for real-time deployment. The authors mention that the current implementation is not yet real-time, and further optimization may be required.
Additionally, the paper does not explore the potential biases or failure modes of the 3D object detection and neural rendering components, which could influence the reliability and robustness of the overall tracking system. Deeper analysis of these aspects would be helpful to understand the limitations and potential pitfalls of the approach.
Finally, the paper focuses primarily on the technical aspects of the method and its performance, but does not delve into the broader implications for the use of such transparent tracking systems in real-world applications. Further discussion on the ethical considerations, privacy concerns, and societal impacts would be valuable for the reader to fully assess the significance of this research.
Conclusion
This paper presents a novel inverse neural rendering approach for explainable multi-object tracking. By combining 3D object detection and neural rendering, the method is able to provide users with a more interpretable and transparent view of the tracking process, compared to traditional 2D bounding box-based techniques.
The key innovation is the ability to reconstruct 3D scene and object models from the video frames, which can lead to better understanding of the factors influencing the tracking performance. While the current implementation has some limitations in terms of computational efficiency, the overall approach offers a promising direction for developing more trustworthy and explainable multi-object tracking systems.
Further research is needed to address the technical challenges and explore the broader implications of such transparent tracking methods, but this work represents an important step towards more interpretable and accountable computer vision systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Inverse Neural Rendering for Explainable Multi-Object Tracking
Julian Ost, Tanushree Banerjee, Mario Bijelic, Felix Heide
Today, most methods for image understanding tasks rely on feed-forward neural networks. While this approach has allowed for empirical accuracy, efficiency, and task adaptation via fine-tuning, it also comes with fundamental disadvantages. Existing networks often struggle to generalize across different datasets, even on the same task. By design, these networks ultimately reason about high-dimensional scene features, which are challenging to analyze. This is true especially when attempting to predict 3D information based on 2D images. We propose to recast 3D multi-object tracking from RGB cameras as an emph{Inverse Rendering (IR)} problem, by optimizing via a differentiable rendering pipeline over the latent space of pre-trained 3D object representations and retrieve the latents that best represent object instances in a given input image. To this end, we optimize an image loss over generative latent spaces that inherently disentangle shape and appearance properties. We investigate not only an alternate take on tracking but our method also enables examining the generated objects, reasoning about failure situations, and resolving ambiguous cases. We validate the generalization and scaling capabilities of our method by learning the generative prior exclusively from synthetic data and assessing camera-based 3D tracking on the nuScenes and Waymo datasets. Both these datasets are completely unseen to our method and do not require fine-tuning. Videos and code are available at https://light.princeton.edu/inverse-rendering-tracking/.
Read more4/19/2024

0
Photorealistic Object Insertion with Diffusion-Guided Inverse Rendering
Ruofan Liang, Zan Gojcic, Merlin Nimier-David, David Acuna, Nandita Vijaykumar, Sanja Fidler, Zian Wang
The correct insertion of virtual objects in images of real-world scenes requires a deep understanding of the scene's lighting, geometry and materials, as well as the image formation process. While recent large-scale diffusion models have shown strong generative and inpainting capabilities, we find that current models do not sufficiently understand the scene shown in a single picture to generate consistent lighting effects (shadows, bright reflections, etc.) while preserving the identity and details of the composited object. We propose using a personalized large diffusion model as guidance to a physically based inverse rendering process. Our method recovers scene lighting and tone-mapping parameters, allowing the photorealistic composition of arbitrary virtual objects in single frames or videos of indoor or outdoor scenes. Our physically based pipeline further enables automatic materials and tone-mapping refinement.
Read more8/20/2024

0
IllumiNeRF: 3D Relighting without Inverse Rendering
Xiaoming Zhao, Pratul P. Srinivasan, Dor Verbin, Keunhong Park, Ricardo Martin Brualla, Philipp Henzler
Existing methods for relightable view synthesis -- using a set of images of an object under unknown lighting to recover a 3D representation that can be rendered from novel viewpoints under a target illumination -- are based on inverse rendering, and attempt to disentangle the object geometry, materials, and lighting that explain the input images. Furthermore, this typically involves optimization through differentiable Monte Carlo rendering, which is brittle and computationally-expensive. In this work, we propose a simpler approach: we first relight each input image using an image diffusion model conditioned on lighting and then reconstruct a Neural Radiance Field (NeRF) with these relit images, from which we render novel views under the target lighting. We demonstrate that this strategy is surprisingly competitive and achieves state-of-the-art results on multiple relighting benchmarks. Please see our project page at https://illuminerf.github.io/.
Read more6/11/2024
0
New!Bayesian Inverse Graphics for Few-Shot Concept Learning
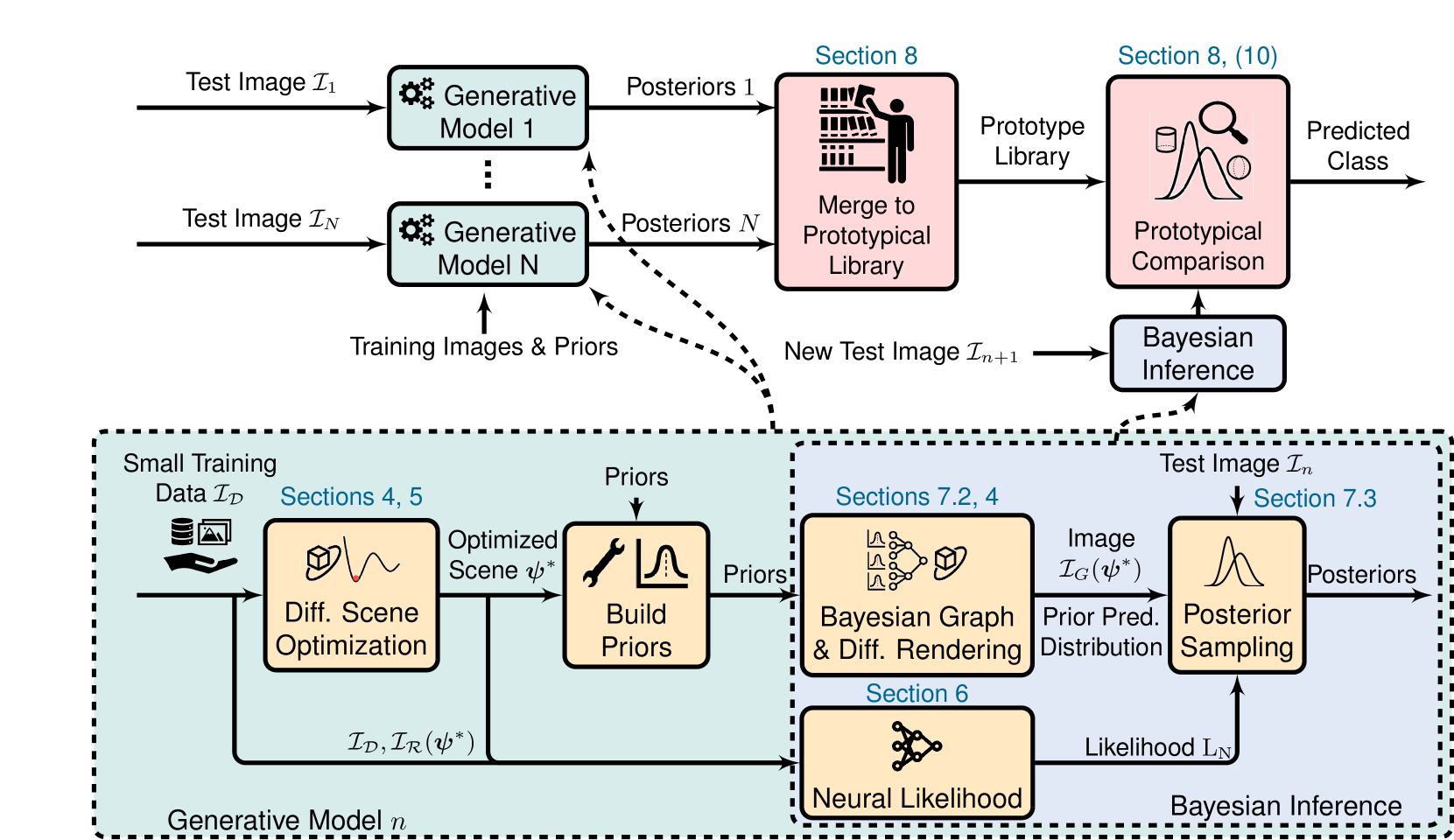
Octavio Arriaga, Jichen Guo, Rebecca Adam, Sebastian Houben, Frank Kirchner
Humans excel at building generalizations of new concepts from just one single example. Contrary to this, current computer vision models typically require large amount of training samples to achieve a comparable accuracy. In this work we present a Bayesian model of perception that learns using only minimal data, a prototypical probabilistic program of an object. Specifically, we propose a generative inverse graphics model of primitive shapes, to infer posterior distributions over physically consistent parameters from one or several images. We show how this representation can be used for downstream tasks such as few-shot classification and pose estimation. Our model outperforms existing few-shot neural-only classification algorithms and demonstrates generalization across varying lighting conditions, backgrounds, and out-of-distribution shapes. By design, our model is uncertainty-aware and uses our new differentiable renderer for optimizing global scene parameters through gradient descent, sampling posterior distributions over object parameters with Markov Chain Monte Carlo (MCMC), and using a neural based likelihood function.
Read more9/16/2024