Bayesian Inverse Graphics for Few-Shot Concept Learning

0
Sign in to get full access
Overview
- This paper explores a Bayesian approach to inverse graphics for few-shot concept learning.
- The goal is to enable AI systems to learn new concepts from just a handful of examples.
- The researchers propose a framework that combines generative modeling of visual concepts with Bayesian inference to rapidly acquire new knowledge.
Plain English Explanation
The paper presents a novel approach to few-shot concept learning, which is the ability of AI systems to learn new concepts from just a small number of examples. The key idea is to use a Bayesian inverse graphics framework, which means modeling the process of generating visual concepts and then using Bayesian inference to quickly learn those concepts from limited data.
The researchers argue that this approach has several advantages over more standard machine learning techniques for few-shot learning. By explicitly modeling the underlying generative process, the system can better extract the essential features of a concept and generalize to new examples. The Bayesian inference also allows the system to rapidly update its understanding as it sees more examples, without forgetting what it has already learned.
In practical terms, this could enable AI assistants to quickly learn new skills or concepts from just a few demonstrations by a user, rather than requiring extensive training on large datasets. It could also help AI systems become more flexible and adaptive, able to continuously expand their knowledge as they encounter new information in the world.
Technical Explanation
The paper proposes a Bayesian inverse graphics framework for few-shot concept learning. The key components are:
-
A generative model that can synthesize visual examples of a concept based on a set of latent parameters. This allows the system to reason about the underlying structure of the concept.
-
An inference procedure that uses Bayesian updating to rapidly learn the latent parameters of a new concept from just a few examples. This lets the system quickly grasp the essential features of the concept.
-
A meta-learning approach that allows the system to learn how to perform this Bayesian inference efficiently, by extracting useful inductive biases from a diverse set of training concepts.
The researchers evaluate their framework on several minimal-data benchmarks, showing that it can outperform standard few-shot learning techniques. They also demonstrate how the learned concepts can be flexibly combined and composed to solve more complex tasks.
Critical Analysis
The paper makes a compelling case for the advantages of the Bayesian inverse graphics approach over more standard few-shot learning methods. By explicitly modeling the generative process, the system can better extract the core features of a concept and generalize to new examples.
However, the framework does rely on having a sufficiently powerful generative model that can faithfully capture the structure of the visual concepts. The researchers note that scaling this to more complex, high-dimensional concepts remains an open challenge.
Additionally, the meta-learning component, while powerful, requires substantial upfront training on a diverse set of concepts. This may limit the real-world applicability in scenarios where the space of possible concepts is highly constrained or rapidly evolving.
Further research is needed to explore ways to make the Bayesian inference more efficient and scalable, as well as to better understand the types of concepts and tasks that this approach is best suited for. Integrating it with other few-shot learning techniques could also lead to promising hybrid approaches.
Conclusion
This paper presents an innovative Bayesian inverse graphics framework for few-shot concept learning, which holds promise for enabling more flexible and adaptive AI systems. By modeling the generative process and using Bayesian inference, the approach can quickly learn new concepts from limited data and flexibly compose them to solve more complex tasks.
While there are still some challenges to overcome, the core ideas of this work represent an important step forward in the field of few-shot learning and could have significant implications for the development of more capable and versatile AI assistants and agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Bayesian Inverse Graphics for Few-Shot Concept Learning
Octavio Arriaga, Jichen Guo, Rebecca Adam, Sebastian Houben, Frank Kirchner
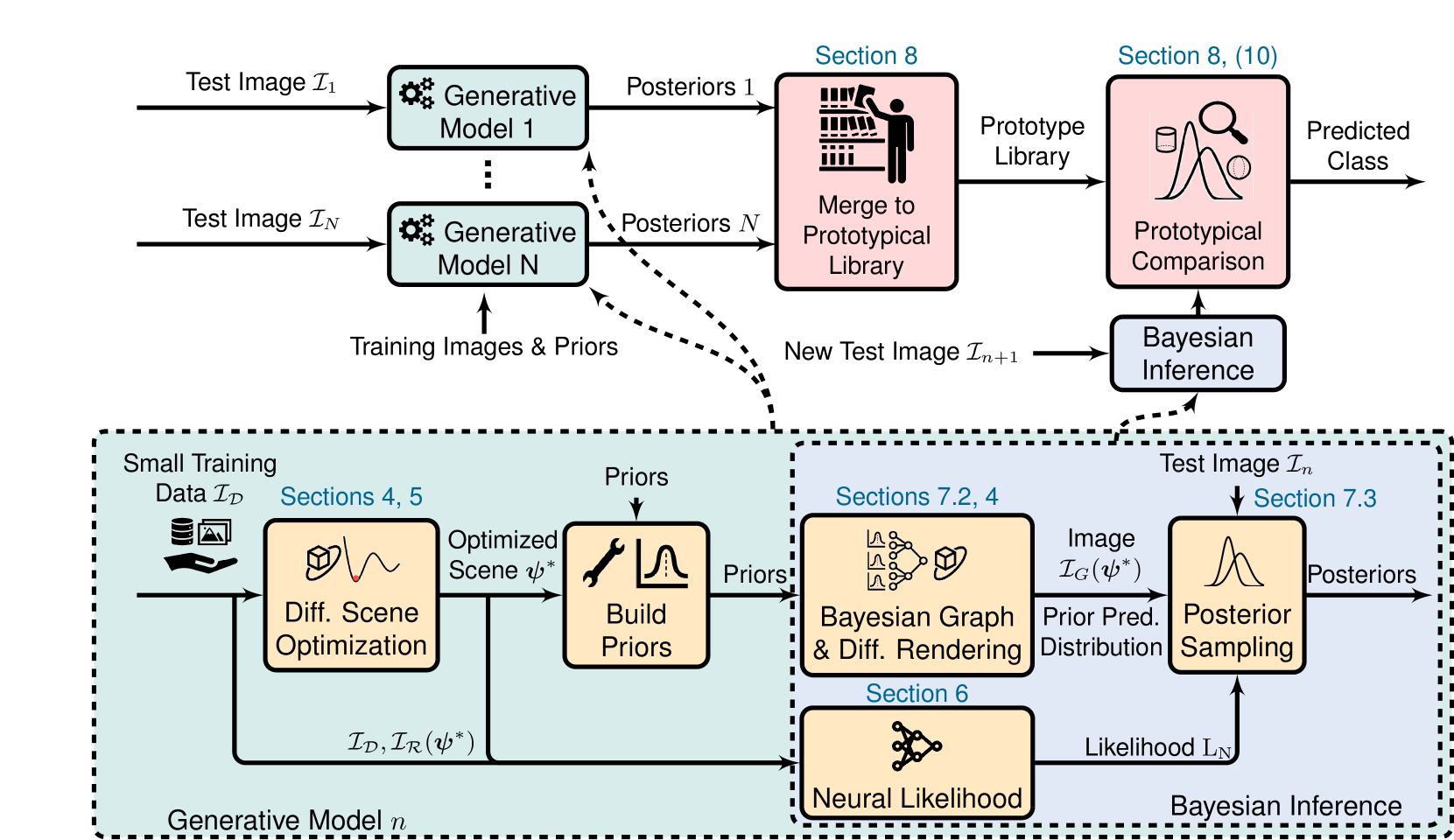
Humans excel at building generalizations of new concepts from just one single example. Contrary to this, current computer vision models typically require large amount of training samples to achieve a comparable accuracy. In this work we present a Bayesian model of perception that learns using only minimal data, a prototypical probabilistic program of an object. Specifically, we propose a generative inverse graphics model of primitive shapes, to infer posterior distributions over physically consistent parameters from one or several images. We show how this representation can be used for downstream tasks such as few-shot classification and pose estimation. Our model outperforms existing few-shot neural-only classification algorithms and demonstrates generalization across varying lighting conditions, backgrounds, and out-of-distribution shapes. By design, our model is uncertainty-aware and uses our new differentiable renderer for optimizing global scene parameters through gradient descent, sampling posterior distributions over object parameters with Markov Chain Monte Carlo (MCMC), and using a neural based likelihood function.
Read more9/16/2024
🏷️
0
Learning from One and Only One Shot
Haizi Yu, Igor Mineyev, Lav R. Varshney, James A. Evans
Humans can generalize from only a few examples and from little pretraining on similar tasks. Yet, machine learning (ML) typically requires large data to learn or pre-learn to transfer. Motivated by nativism and artificial general intelligence, we directly model human-innate priors in abstract visual tasks such as character and doodle recognition. This yields a white-box model that learns general-appearance similarity by mimicking how humans naturally ``distort'' an object at first sight. Using just nearest-neighbor classification on this cognitively-inspired similarity space, we achieve human-level recognition with only $1$--$10$ examples per class and no pretraining. This differs from few-shot learning that uses massive pretraining. In the tiny-data regime of MNIST, EMNIST, Omniglot, and QuickDraw benchmarks, we outperform both modern neural networks and classical ML. For unsupervised learning, by learning the non-Euclidean, general-appearance similarity space in a $k$-means style, we achieve multifarious visual realizations of abstract concepts by generating human-intuitive archetypes as cluster centroids.
Read more5/22/2024

0
Abstracted Gaussian Prototypes for One-Shot Concept Learning
Chelsea Zou, Kenneth J. Kurtz
We introduce a cluster-based generative image segmentation framework to encode higher-level representations of visual concepts based on one-shot learning inspired by the Omniglot Challenge. The inferred parameters of each component of a Gaussian Mixture Model (GMM) represent a distinct topological subpart of a visual concept. Sampling new data from these parameters generates augmented subparts to build a more robust prototype for each concept, i.e., the Abstracted Gaussian Prototype (AGP). This framework addresses one-shot classification tasks using a cognitively-inspired similarity metric and addresses one-shot generative tasks through a novel AGP-VAE pipeline employing variational autoencoders (VAEs) to generate new class variants. Results from human judges reveal that the generative pipeline produces novel examples and classes of visual concepts that are broadly indistinguishable from those made by humans. The proposed framework leads to impressive but not state-of-the-art classification accuracy; thus, the contribution is two-fold: 1) the system is uniquely low in theoretical and computational complexity and operates in a completely standalone manner compared while existing approaches draw heavily on pre-training or knowledge engineering; and 2) in contrast with competing neural network models, the AGP approach addresses the importance of breadth of task capability emphasized in the Omniglot challenge (i.e., successful performance on generative tasks). These two points are critical as we advance toward an understanding of how learning/reasoning systems can produce viable, robust, and flexible concepts based on literally nothing more than a single example.
Read more9/2/2024
💬
1
Re-Thinking Inverse Graphics With Large Language Models
Peter Kulits, Haiwen Feng, Weiyang Liu, Victoria Abrevaya, Michael J. Black
Inverse graphics -- the task of inverting an image into physical variables that, when rendered, enable reproduction of the observed scene -- is a fundamental challenge in computer vision and graphics. Successfully disentangling an image into its constituent elements, such as the shape, color, and material properties of the objects of the 3D scene that produced it, requires a comprehensive understanding of the environment. This complexity limits the ability of existing carefully engineered approaches to generalize across domains. Inspired by the zero-shot ability of large language models (LLMs) to generalize to novel contexts, we investigate the possibility of leveraging the broad world knowledge encoded in such models to solve inverse-graphics problems. To this end, we propose the Inverse-Graphics Large Language Model (IG-LLM), an inverse-graphics framework centered around an LLM, that autoregressively decodes a visual embedding into a structured, compositional 3D-scene representation. We incorporate a frozen pre-trained visual encoder and a continuous numeric head to enable end-to-end training. Through our investigation, we demonstrate the potential of LLMs to facilitate inverse graphics through next-token prediction, without the application of image-space supervision. Our analysis enables new possibilities for precise spatial reasoning about images that exploit the visual knowledge of LLMs. We release our code and data at https://ig-llm.is.tue.mpg.de/ to ensure the reproducibility of our investigation and to facilitate future research.
Read more8/27/2024