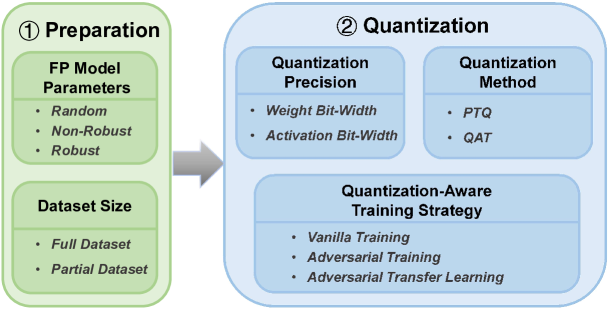
Investigating the Impact of Quantization on Adversarial Robustness

0
Sign in to get full access
Overview
- This paper investigates the impact of quantization, a technique for reducing the memory and computation requirements of neural networks, on the adversarial robustness of these models.
- The researchers explore how different quantization approaches affect a model's ability to withstand adversarial attacks, which are carefully crafted inputs designed to fool the model into making incorrect predictions.
- They conduct extensive experiments to understand the trade-offs between quantization and adversarial robustness, providing insights that can help improve the security and efficiency of deployed AI systems.
Plain English Explanation
Neural networks, the core components of many modern AI systems, can be incredibly powerful but also computationally expensive. Quantization is a technique used to reduce the memory and processing requirements of these models by representing the numerical values with fewer bits. This makes the models more efficient, but it can also affect their performance in unexpected ways.
One key concern is the impact of quantization on a model's adversarial robustness - its ability to withstand carefully crafted "adversarial" inputs designed to trick the model into making incorrect predictions. The researchers in this paper set out to better understand this relationship between quantization and adversarial robustness.
Through a series of experiments, they explored how different quantization approaches (e.g., uniform quantization, channel-wise quantization, etc.) affected the models' performance under various adversarial attacks. They found that the specific quantization method used can have a significant impact on a model's robustness, with some approaches providing better protection against adversarial examples than others.
These insights can help developers and researchers strike a better balance between the efficiency gains of quantization and the need to maintain robust and secure AI systems, particularly as these technologies become more widely deployed in real-world applications. By understanding the trade-offs, they can make more informed decisions about how to quantize their models while minimizing the risk of adversarial vulnerabilities.
Technical Explanation
The paper begins by providing an overview of the problem of adversarial robustness in the context of quantized neural networks (QNNs). The authors note that while quantization can offer significant efficiency improvements, it may also introduce vulnerabilities to adversarial attacks. They hypothesize that the specific quantization approach used can have a significant impact on a model's ability to withstand these attacks.
To test this hypothesis, the researchers conducted a series of experiments using different quantization methods, including uniform quantization, channel-wise quantization, and layer-wise quantization. They evaluated the models' performance on standard image classification tasks, as well as their robustness to a variety of adversarial attacks, such as FGSM, PGD, and CW.
The results showed that the choice of quantization approach had a significant impact on the models' adversarial robustness. Certain quantization methods, like channel-wise quantization, were able to maintain high levels of robustness even with aggressive quantization, while other approaches led to a more pronounced trade-off between model efficiency and adversarial resistance.
The paper also discusses the potential mechanisms underlying these findings, suggesting that the uneven distribution of quantization errors across different channels or layers may be a key factor in determining a model's vulnerability to adversarial perturbations. The authors provide further analysis and insights that can help guide the development of quantized models with improved security and efficiency.
Critical Analysis
The paper provides a thorough and well-designed investigation into the relationship between quantization and adversarial robustness. The experimental setup and analysis are rigorous, and the findings offer valuable insights for practitioners working on deploying efficient and secure AI systems.
One potential limitation of the study is that it focuses primarily on image classification tasks, which may not fully capture the complexities of adversarial attacks in other domains, such as natural language processing or reinforcement learning. It would be interesting to see if the researchers' findings hold true in a broader range of applications.
Additionally, the paper does not delve deeply into the underlying mechanisms driving the observed trade-offs between quantization and adversarial robustness. While the authors provide some hypotheses, further research may be needed to fully understand the causal relationships at play.
Nonetheless, the paper makes a significant contribution to the field by highlighting the importance of considering adversarial robustness when designing and deploying quantized neural networks. The insights provided can help guide the development of more secure and efficient AI models, which will be crucial as these technologies become increasingly integral to our daily lives.
Conclusion
This paper presents a comprehensive investigation into the impact of quantization on the adversarial robustness of neural networks. The researchers found that the choice of quantization approach can have a significant influence on a model's ability to withstand carefully crafted adversarial attacks, with some methods preserving robustness better than others.
These findings are particularly relevant as neural networks become more widely deployed in real-world applications, where both efficiency and security are paramount. By understanding the trade-offs between quantization and adversarial robustness, developers and researchers can make more informed decisions about how to optimize their models while minimizing the risk of vulnerabilities.
Overall, this paper contributes valuable insights that can help advance the development of robust and efficient AI systems, paving the way for more trustworthy and secure deployment of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Investigating the Impact of Quantization on Adversarial Robustness
Qun Li, Yuan Meng, Chen Tang, Jiacheng Jiang, Zhi Wang
Quantization is a promising technique for reducing the bit-width of deep models to improve their runtime performance and storage efficiency, and thus becomes a fundamental step for deployment. In real-world scenarios, quantized models are often faced with adversarial attacks which cause the model to make incorrect inferences by introducing slight perturbations. However, recent studies have paid less attention to the impact of quantization on the model robustness. More surprisingly, existing studies on this topic even present inconsistent conclusions, which prompted our in-depth investigation. In this paper, we conduct a first-time analysis of the impact of the quantization pipeline components that can incorporate robust optimization under the settings of Post-Training Quantization and Quantization-Aware Training. Through our detailed analysis, we discovered that this inconsistency arises from the use of different pipelines in different studies, specifically regarding whether robust optimization is performed and at which quantization stage it occurs. Our research findings contribute insights into deploying more secure and robust quantized networks, assisting practitioners in reference for scenarios with high-security requirements and limited resources.
Read more4/9/2024
❗
0
Exploiting LLM Quantization
Kazuki Egashira, Mark Vero, Robin Staab, Jingxuan He, Martin Vechev
Quantization leverages lower-precision weights to reduce the memory usage of large language models (LLMs) and is a key technique for enabling their deployment on commodity hardware. While LLM quantization's impact on utility has been extensively explored, this work for the first time studies its adverse effects from a security perspective. We reveal that widely used quantization methods can be exploited to produce a harmful quantized LLM, even though the full-precision counterpart appears benign, potentially tricking users into deploying the malicious quantized model. We demonstrate this threat using a three-staged attack framework: (i) first, we obtain a malicious LLM through fine-tuning on an adversarial task; (ii) next, we quantize the malicious model and calculate constraints that characterize all full-precision models that map to the same quantized model; (iii) finally, using projected gradient descent, we tune out the poisoned behavior from the full-precision model while ensuring that its weights satisfy the constraints computed in step (ii). This procedure results in an LLM that exhibits benign behavior in full precision but when quantized, it follows the adversarial behavior injected in step (i). We experimentally demonstrate the feasibility and severity of such an attack across three diverse scenarios: vulnerable code generation, content injection, and over-refusal attack. In practice, the adversary could host the resulting full-precision model on an LLM community hub such as Hugging Face, exposing millions of users to the threat of deploying its malicious quantized version on their devices.
Read more5/29/2024
0
David and Goliath: An Empirical Evaluation of Attacks and Defenses for QNNs at the Deep Edge
Miguel Costa, Sandro Pinto
ML is shifting from the cloud to the edge. Edge computing reduces the surface exposing private data and enables reliable throughput guarantees in real-time applications. Of the panoply of devices deployed at the edge, resource-constrained MCUs, e.g., Arm Cortex-M, are more prevalent, orders of magnitude cheaper, and less power-hungry than application processors or GPUs. Thus, enabling intelligence at the deep edge is the zeitgeist, with researchers focusing on unveiling novel approaches to deploy ANNs on these constrained devices. Quantization is a well-established technique that has proved effective in enabling the deployment of neural networks on MCUs; however, it is still an open question to understand the robustness of QNNs in the face of adversarial examples. To fill this gap, we empirically evaluate the effectiveness of attacks and defenses from (full-precision) ANNs on (constrained) QNNs. Our evaluation includes three QNNs targeting TinyML applications, ten attacks, and six defenses. With this study, we draw a set of interesting findings. First, quantization increases the point distance to the decision boundary and leads the gradient estimated by some attacks to explode or vanish. Second, quantization can act as a noise attenuator or amplifier, depending on the noise magnitude, and causes gradient misalignment. Regarding adversarial defenses, we conclude that input pre-processing defenses show impressive results on small perturbations; however, they fall short as the perturbation increases. At the same time, train-based defenses increase the average point distance to the decision boundary, which holds after quantization. However, we argue that train-based defenses still need to smooth the quantization-shift and gradient misalignment phenomenons to counteract adversarial example transferability to QNNs. All artifacts are open-sourced to enable independent validation of results.
Read more5/6/2024

0
A Comprehensive Evaluation of Quantization Strategies for Large Language Models
Renren Jin, Jiangcun Du, Wuwei Huang, Wei Liu, Jian Luan, Bin Wang, Deyi Xiong
Increasing the number of parameters in large language models (LLMs) usually improves performance in downstream tasks but raises compute and memory costs, making deployment difficult in resource-limited settings. Quantization techniques, which reduce the bits needed for model weights or activations with minimal performance loss, have become popular due to the rise of LLMs. However, most quantization studies use pre-trained LLMs, and the impact of quantization on instruction-tuned LLMs and the relationship between perplexity and benchmark performance of quantized LLMs are not well understood. Evaluation of quantized LLMs is often limited to language modeling and a few classification tasks, leaving their performance on other benchmarks unclear. To address these gaps, we propose a structured evaluation framework consisting of three critical dimensions: (1) knowledge & capacity, (2) alignment, and (3) efficiency, and conduct extensive experiments across ten diverse benchmarks. Our experimental results indicate that LLMs with 4-bit quantization can retain performance comparable to their non-quantized counterparts, and perplexity can serve as a proxy metric for quantized LLMs on most benchmarks. Furthermore, quantized LLMs with larger parameter scales can outperform smaller LLMs. Despite the memory savings achieved through quantization, it can also slow down the inference speed of LLMs. Consequently, substantial engineering efforts and hardware support are imperative to achieve a balanced optimization of decoding speed and memory consumption in the context of quantized LLMs.
Read more6/7/2024