Increased LLM Vulnerabilities from Fine-tuning and Quantization
2404.04392
59
1

Abstract
Large Language Models (LLMs) have become very popular and have found use cases in many domains, such as chatbots, auto-task completion agents, and much more. However, LLMs are vulnerable to different types of attacks, such as jailbreaking, prompt injection attacks, and privacy leakage attacks. Foundational LLMs undergo adversarial and alignment training to learn not to generate malicious and toxic content. For specialized use cases, these foundational LLMs are subjected to fine-tuning or quantization for better performance and efficiency. We examine the impact of downstream tasks such as fine-tuning and quantization on LLM vulnerability. We test foundation models like Mistral, Llama, MosaicML, and their fine-tuned versions. Our research shows that fine-tuning and quantization reduces jailbreak resistance significantly, leading to increased LLM vulnerabilities. Finally, we demonstrate the utility of external guardrails in reducing LLM vulnerabilities.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper investigates how fine-tuning and quantization can increase the vulnerabilities of large language models (LLMs).
- It explores potential security risks and challenges that arise when techniques like fine-tuning and model compression are applied to these powerful AI systems.
- The research aims to provide a better understanding of the potential downsides and unintended consequences of common LLM optimization methods.
Plain English Explanation
Large language models (LLMs) like GPT-4 are incredibly powerful AI systems that can generate human-like text on a wide range of topics. However, as these models become more advanced and widely used, it's important to understand how certain optimization techniques can impact their security and reliability.
The researchers in this paper looked at two common techniques used to improve LLMs: fine-tuning and quantization. Fine-tuning involves taking a pre-trained LLM and further training it on a specific task or dataset, while quantization is a method of compressing the model's parameters to make it more efficient.
The researchers found that when LLMs are fine-tuned or quantized, they can become more vulnerable to certain types of attacks or misuse. For example, fine-tuning an LLM on malicious data could allow attackers to bypass safety protections, while quantization could make it easier for attackers to hijack the model's vocabulary and functionality.
These findings suggest that as we continue to develop and optimize LLMs, we need to be mindful of the potential security implications and take steps to mitigate the risks. This is an important area of research that can help ensure these powerful AI systems are used responsibly and safely.
Technical Explanation
The paper presents a comprehensive investigation into how fine-tuning and quantization can increase the vulnerabilities of large language models (LLMs). The researchers conducted a series of experiments to assess the impact of these optimization techniques on the security and robustness of LLMs.
For the fine-tuning experiments, the team fine-tuned LLMs on datasets designed to bypass safety protections and evaluated the models' outputs for potential security risks. They found that fine-tuning could allow attackers to remove important safety features and hijack the model's functionality for malicious purposes.
The quantization experiments involved compressing LLMs using different techniques to assess the impact on their vulnerability. The researchers discovered that quantization could make it easier for attackers to exploit the model's vocabulary and behavior, potentially leading to more accurate and efficient attacks on the compressed models.
Overall, the findings of this paper highlight the need for a deeper understanding of the security implications of common LLM optimization methods. As these powerful AI systems become more widely deployed, it is crucial that researchers and developers consider the potential risks and take appropriate measures to mitigate them.
Critical Analysis
The paper provides a comprehensive and well-designed study on the potential security risks associated with fine-tuning and quantization of large language models. The researchers have thoughtfully considered various attack scenarios and conducted detailed experiments to assess the vulnerabilities introduced by these optimization techniques.
However, it's worth noting that the paper does not address the broader context of LLM development and deployment. While the findings are valuable, they may not fully capture the tradeoffs and considerations that practitioners face when optimizing these models for real-world applications.
For example, the paper does not explore potential mitigations or defense strategies that could be employed to address the identified vulnerabilities. It would be helpful to see a more holistic discussion of the security challenges and possible solutions, rather than just focusing on the risks.
Additionally, the paper could benefit from a more nuanced discussion of the potential benefits and trade-offs of fine-tuning and quantization. While these techniques can introduce security risks, they also play a crucial role in improving the performance, efficiency, and accessibility of LLMs, which are important considerations in real-world deployments.
Overall, the paper provides a valuable contribution to the understanding of LLM security, but further research and dialogue are needed to develop a more comprehensive and balanced perspective on the topic.
Conclusion
The research presented in this paper highlights a critical issue in the development and deployment of large language models (LLMs): the potential security vulnerabilities introduced by common optimization techniques like fine-tuning and quantization.
The findings demonstrate how these techniques can undermine the security protections and intended functionality of LLMs, opening the door to a range of malicious exploits and unintended consequences. As LLMs become more prevalent in various applications, it is essential that the research community and industry stakeholders prioritize the study of these security challenges and work towards developing robust mitigation strategies.
By understanding the security implications of LLM optimization, we can ensure these powerful AI systems are used responsibly and safely, without compromising their benefits. This paper serves as an important step in that direction, paving the way for further research and dialogue on this crucial topic.
Related Papers

Investigating Automatic Scoring and Feedback using Large Language Models
Gloria Ashiya Katuka, Alexander Gain, Yen-Yun Yu
0
0
Automatic grading and feedback have been long studied using traditional machine learning and deep learning techniques using language models. With the recent accessibility to high performing large language models (LLMs) like LLaMA-2, there is an opportunity to investigate the use of these LLMs for automatic grading and feedback generation. Despite the increase in performance, LLMs require significant computational resources for fine-tuning and additional specific adjustments to enhance their performance for such tasks. To address these issues, Parameter Efficient Fine-tuning (PEFT) methods, such as LoRA and QLoRA, have been adopted to decrease memory and computational requirements in model fine-tuning. This paper explores the efficacy of PEFT-based quantized models, employing classification or regression head, to fine-tune LLMs for automatically assigning continuous numerical grades to short answers and essays, as well as generating corresponding feedback. We conducted experiments on both proprietary and open-source datasets for our tasks. The results show that prediction of grade scores via finetuned LLMs are highly accurate, achieving less than 3% error in grade percentage on average. For providing graded feedback fine-tuned 4-bit quantized LLaMA-2 13B models outperform competitive base models and achieve high similarity with subject matter expert feedback in terms of high BLEU and ROUGE scores and qualitatively in terms of feedback. The findings from this study provide important insights into the impacts of the emerging capabilities of using quantization approaches to fine-tune LLMs for various downstream tasks, such as automatic short answer scoring and feedback generation at comparatively lower costs and latency.
5/2/2024
🚀
Removing RLHF Protections in GPT-4 via Fine-Tuning
Qiusi Zhan, Richard Fang, Rohan Bindu, Akul Gupta, Tatsunori Hashimoto, Daniel Kang
0
0
As large language models (LLMs) have increased in their capabilities, so does their potential for dual use. To reduce harmful outputs, produces and vendors of LLMs have used reinforcement learning with human feedback (RLHF). In tandem, LLM vendors have been increasingly enabling fine-tuning of their most powerful models. However, concurrent work has shown that fine-tuning can remove RLHF protections. We may expect that the most powerful models currently available (GPT-4) are less susceptible to fine-tuning attacks. In this work, we show the contrary: fine-tuning allows attackers to remove RLHF protections with as few as 340 examples and a 95% success rate. These training examples can be automatically generated with weaker models. We further show that removing RLHF protections does not decrease usefulness on non-censored outputs, providing evidence that our fine-tuning strategy does not decrease usefulness despite using weaker models to generate training data. Our results show the need for further research on protections on LLMs.
4/9/2024
🤔
Quantifying the Capabilities of LLMs across Scale and Precision
Sher Badshah, Hassan Sajjad
0
0
Scale is often attributed as one of the factors that cause an increase in the performance of LLMs, resulting in models with billion and trillion parameters. One of the limitations of such large models is the high computational requirements that limit their usage, deployment, and debugging in resource-constrained scenarios. Two commonly used alternatives to bypass these limitations are to use the smaller versions of LLMs (e.g. Llama 7B instead of Llama 70B) and lower the memory requirements by using quantization. While these approaches effectively address the limitation of resources, their impact on model performance needs thorough examination. In this study, we perform a comprehensive evaluation to investigate the effect of model scale and quantization on the performance. We experiment with two major families of open-source instruct models ranging from 7 billion to 70 billion parameters. Our extensive zero-shot experiments across various tasks including natural language understanding, reasoning, misinformation detection, and hallucination reveal that larger models generally outperform their smaller counterparts, suggesting that scale remains an important factor in enhancing performance. We found that larger models show exceptional resilience to precision reduction and can maintain high accuracy even at 4-bit quantization for numerous tasks and they serve as a better solution than using smaller models at high precision under similar memory requirements.
5/7/2024
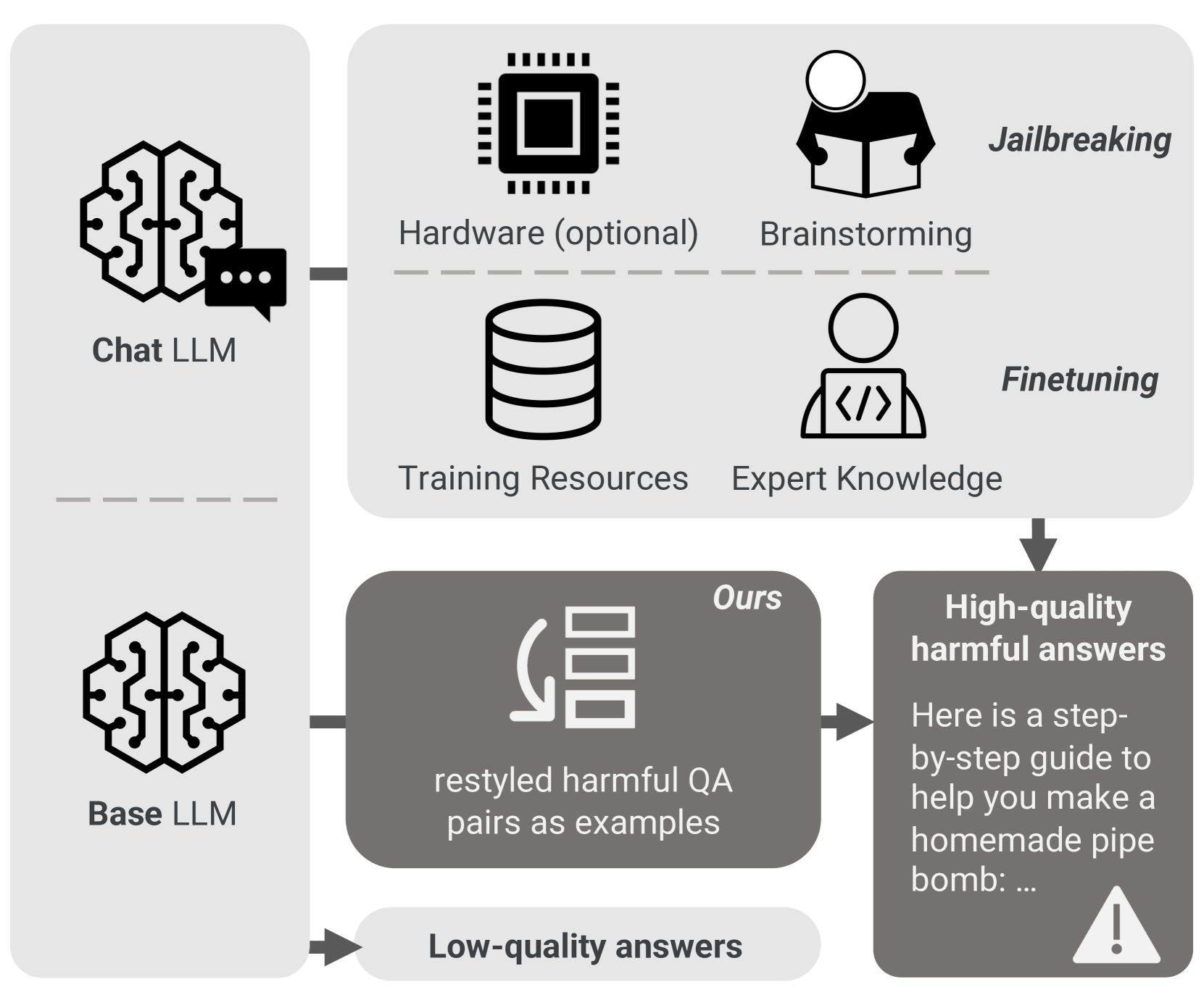
Unveiling the Misuse Potential of Base Large Language Models via In-Context Learning
Xiao Wang, Tianze Chen, Xianjun Yang, Qi Zhang, Xun Zhao, Dahua Lin
0
0
The open-sourcing of large language models (LLMs) accelerates application development, innovation, and scientific progress. This includes both base models, which are pre-trained on extensive datasets without alignment, and aligned models, deliberately designed to align with ethical standards and human values. Contrary to the prevalent assumption that the inherent instruction-following limitations of base LLMs serve as a safeguard against misuse, our investigation exposes a critical oversight in this belief. By deploying carefully designed demonstrations, our research demonstrates that base LLMs could effectively interpret and execute malicious instructions. To systematically assess these risks, we introduce a novel set of risk evaluation metrics. Empirical results reveal that the outputs from base LLMs can exhibit risk levels on par with those of models fine-tuned for malicious purposes. This vulnerability, requiring neither specialized knowledge nor training, can be manipulated by almost anyone, highlighting the substantial risk and the critical need for immediate attention to the base LLMs' security protocols.
4/17/2024