Investigating Markers and Drivers of Gender Bias in Machine Translations
2403.11896
0
0
Abstract
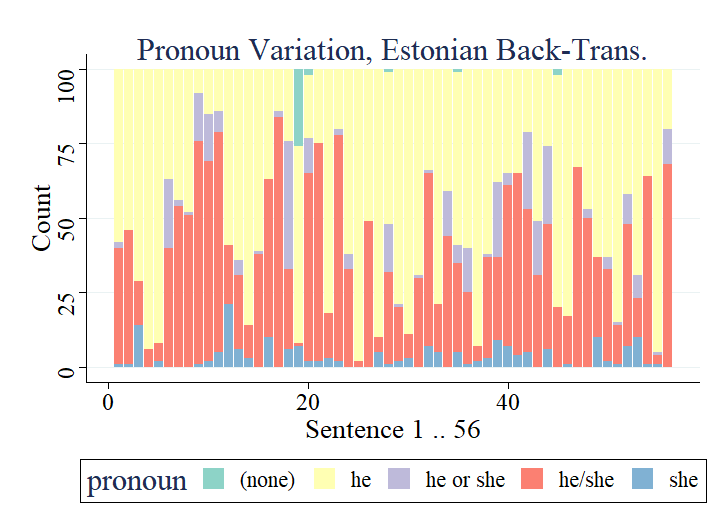
Implicit gender bias in Large Language Models (LLMs) is a well-documented problem, and implications of gender introduced into automatic translations can perpetuate real-world biases. However, some LLMs use heuristics or post-processing to mask such bias, making investigation difficult. Here, we examine bias in LLMss via back-translation, using the DeepL translation API to investigate the bias evinced when repeatedly translating a set of 56 Software Engineering tasks used in a previous study. Each statement starts with 'she', and is translated first into a 'genderless' intermediate language then back into English; we then examine pronoun-choice in the back-translated texts. We expand prior research in the following ways: (1) by comparing results across five intermediate languages, namely Finnish, Indonesian, Estonian, Turkish and Hungarian; (2) by proposing a novel metric for assessing the variation in gender implied in the repeated translations, avoiding the over-interpretation of individual pronouns, apparent in earlier work; (3) by investigating sentence features that drive bias; (4) and by comparing results from three time-lapsed datasets to establish the reproducibility of the approach. We found that some languages display similar patterns of pronoun use, falling into three loose groups, but that patterns vary between groups; this underlines the need to work with multiple languages. We also identify the main verb appearing in a sentence as a likely significant driver of implied gender in the translations. Moreover, we see a good level of replicability in the results, and establish that our variation metric proves robust despite an obvious change in the behaviour of the DeepL translation API during the course of the study. These results show that the back-translation method can provide further insights into bias in language models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper investigates gender bias in machine translations, aiming to identify markers and drivers of such bias.
- The research explores how machine translation models trained on large language datasets can perpetuate and amplify societal gender stereotypes.
- The study examines the impact of back-translation, a common technique used to improve machine translations, on gender bias.
Plain English Explanation
Machine translation models are software systems that can automatically translate text from one language to another. These models are trained on massive datasets of text from the internet and other sources.
However, the data used to train these models often reflects societal biases, including gender stereotypes. As a result, the translated text produced by machine translation models can also exhibit gender bias. For example, the model may consistently translate gender-neutral terms using masculine pronouns, reinforcing the idea that certain roles or professions are "male-dominated."
The researchers in this paper wanted to better understand the nature and causes of gender bias in machine translations. They focused on a technique called "back-translation," where the model first translates text from one language to another, and then translates it back to the original language. This back-and-forth process is meant to improve the quality of the final translation.
The researchers examined how the back-translation process affects the level of gender bias in the translated text. They also looked for specific linguistic markers or patterns that indicate the presence of gender bias. By understanding the drivers of bias in machine translation, the researchers hope to develop techniques to mitigate this problem and create more equitable and inclusive translation systems.
Technical Explanation
The researchers conducted a series of experiments using large language models trained on diverse datasets to perform machine translations. They focused on translations between English and five other languages: German, French, Spanish, Italian, and Russian.
To assess gender bias, the researchers used a set of gender-neutral words and phrases (e.g., "doctor," "scientist," "leader") and examined how the machine translation models rendered these terms in the target languages. They looked for the consistent use of masculine or feminine pronouns or other gendered language, which would indicate the presence of gender stereotypes.
The key part of the study involved the use of back-translation. The researchers compared the gender bias observed in the initial translations with the bias present in the back-translations. This allowed them to understand how the back-translation process, a common technique to improve translation quality, might be influencing or amplifying gender bias.
The researchers also analyzed the linguistic features of the translations, such as the types of words used and their frequencies, to identify potential markers of gender bias. This provided insights into the specific mechanisms by which the machine translation models were propagating gender stereotypes.
Critical Analysis
The paper provides a thorough and rigorous investigation of gender bias in machine translations, examining the issue from multiple angles. The use of back-translation as a focal point is a clever and insightful approach, as it allows the researchers to uncover how a common technique in the field can inadvertently exacerbate the problem of gender bias.
One potential limitation of the study is that it focuses primarily on examining the outputs of the machine translation models, without delving deeply into the underlying training data and model architectures. While the linguistic analysis provides valuable insights, a more comprehensive examination of the model internals could yield additional clues about the drivers of gender bias.
Additionally, the paper does not explore potential solutions or mitigation strategies beyond the identification of bias markers and drivers. Further research could investigate techniques to debias the training data, fine-tune the models to be more gender-inclusive, or develop novel architectures that are inherently less susceptible to gender bias.
Overall, this paper makes an important contribution to the understanding of gender bias in machine translation, a critical issue as these technologies become increasingly ubiquitous in our daily lives. The insights gained from this work can inform the development of more equitable and inclusive natural language processing systems.
Conclusion
This research paper provides a detailed investigation into the markers and drivers of gender bias in machine translations. The study examines how the back-translation process, a common technique used to improve translation quality, can inadvertently amplify existing gender stereotypes in the translated text.
By analyzing the linguistic features of machine translations across multiple languages, the researchers identify specific patterns and indicators of gender bias. This understanding of the underlying mechanisms can inform the development of more equitable and inclusive natural language processing systems, helping to address the perpetuation of societal biases in these rapidly advancing technologies.
As machine translation models become increasingly ubiquitous, it is crucial to address the issue of gender bias to ensure these tools are fair and accessible to all users, regardless of their gender identity. The insights from this research represent an important step towards building more inclusive and representative machine translation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Investigating Gender Bias in Turkish Language Models
Orhun Caglidil, Malte Ostendorff, Georg Rehm
0
0
Language models are trained mostly on Web data, which often contains social stereotypes and biases that the models can inherit. This has potentially negative consequences, as models can amplify these biases in downstream tasks or applications. However, prior research has primarily focused on the English language, especially in the context of gender bias. In particular, grammatically gender-neutral languages such as Turkish are underexplored despite representing different linguistic properties to language models with possibly different effects on biases. In this paper, we fill this research gap and investigate the significance of gender bias in Turkish language models. We build upon existing bias evaluation frameworks and extend them to the Turkish language by translating existing English tests and creating new ones designed to measure gender bias in the context of Turkiye. Specifically, we also evaluate Turkish language models for their embedded ethnic bias toward Kurdish people. Based on the experimental results, we attribute possible biases to different model characteristics such as the model size, their multilingualism, and the training corpora. We make the Turkish gender bias dataset publicly available.
4/19/2024

Towards detecting unanticipated bias in Large Language Models
Anna Kruspe
0
0
Over the last year, Large Language Models (LLMs) like ChatGPT have become widely available and have exhibited fairness issues similar to those in previous machine learning systems. Current research is primarily focused on analyzing and quantifying these biases in training data and their impact on the decisions of these models, alongside developing mitigation strategies. This research largely targets well-known biases related to gender, race, ethnicity, and language. However, it is clear that LLMs are also affected by other, less obvious implicit biases. The complex and often opaque nature of these models makes detecting such biases challenging, yet this is crucial due to their potential negative impact in various applications. In this paper, we explore new avenues for detecting these unanticipated biases in LLMs, focusing specifically on Uncertainty Quantification and Explainable AI methods. These approaches aim to assess the certainty of model decisions and to make the internal decision-making processes of LLMs more transparent, thereby identifying and understanding biases that are not immediately apparent. Through this research, we aim to contribute to the development of fairer and more transparent AI systems.
4/4/2024
What is Your Favorite Gender, MLM? Gender Bias Evaluation in Multilingual Masked Language Models
Jeongrok Yu, Seong Ug Kim, Jacob Choi, Jinho D. Choi
0
0
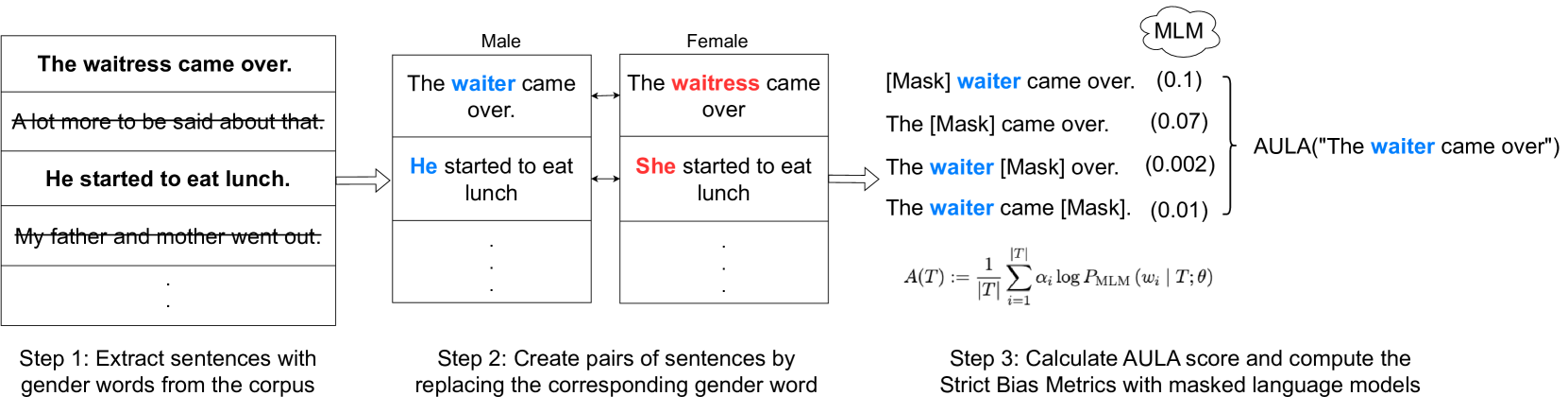
Bias is a disproportionate prejudice in favor of one side against another. Due to the success of transformer-based Masked Language Models (MLMs) and their impact on many NLP tasks, a systematic evaluation of bias in these models is needed more than ever. While many studies have evaluated gender bias in English MLMs, only a few works have been conducted for the task in other languages. This paper proposes a multilingual approach to estimate gender bias in MLMs from 5 languages: Chinese, English, German, Portuguese, and Spanish. Unlike previous work, our approach does not depend on parallel corpora coupled with English to detect gender bias in other languages using multilingual lexicons. Moreover, a novel model-based method is presented to generate sentence pairs for a more robust analysis of gender bias, compared to the traditional lexicon-based method. For each language, both the lexicon-based and model-based methods are applied to create two datasets respectively, which are used to evaluate gender bias in an MLM specifically trained for that language using one existing and 3 new scoring metrics. Our results show that the previous approach is data-sensitive and not stable as it does not remove contextual dependencies irrelevant to gender. In fact, the results often flip when different scoring metrics are used on the same dataset, suggesting that gender bias should be studied on a large dataset using multiple evaluation metrics for best practice.
4/11/2024
🛸
Multilingual Text-to-Image Generation Magnifies Gender Stereotypes and Prompt Engineering May Not Help You
Felix Friedrich, Katharina Hammerl, Patrick Schramowski, Manuel Brack, Jindrich Libovicky, Kristian Kersting, Alexander Fraser
0
0
Text-to-image generation models have recently achieved astonishing results in image quality, flexibility, and text alignment, and are consequently employed in a fast-growing number of applications. Through improvements in multilingual abilities, a larger community now has access to this technology. However, our results show that multilingual models suffer from significant gender biases just as monolingual models do. Furthermore, the natural expectation that multilingual models will provide similar results across languages does not hold up. Instead, there are important differences between languages. We propose a novel benchmark, MAGBIG, intended to foster research on gender bias in multilingual models. We use MAGBIG to investigate the effect of multilingualism on gender bias in T2I models. To this end, we construct multilingual prompts requesting portraits of people with a certain occupation or trait. Our results show that not only do models exhibit strong gender biases but they also behave differently across languages. Furthermore, we investigate prompt engineering strategies, such as indirect, neutral formulations, to mitigate these biases. Unfortunately, these approaches have limited success and result in worse text-to-image alignment. Consequently, we call for more research into diverse representations across languages in image generators, as well as into steerability to address biased model behavior.
5/16/2024