Investigating Gender Bias in Turkish Language Models
2404.11726
0
0
Abstract
Language models are trained mostly on Web data, which often contains social stereotypes and biases that the models can inherit. This has potentially negative consequences, as models can amplify these biases in downstream tasks or applications. However, prior research has primarily focused on the English language, especially in the context of gender bias. In particular, grammatically gender-neutral languages such as Turkish are underexplored despite representing different linguistic properties to language models with possibly different effects on biases. In this paper, we fill this research gap and investigate the significance of gender bias in Turkish language models. We build upon existing bias evaluation frameworks and extend them to the Turkish language by translating existing English tests and creating new ones designed to measure gender bias in the context of Turkiye. Specifically, we also evaluate Turkish language models for their embedded ethnic bias toward Kurdish people. Based on the experimental results, we attribute possible biases to different model characteristics such as the model size, their multilingualism, and the training corpora. We make the Turkish gender bias dataset publicly available.
Create account to get full access
Overview
- The paper investigates gender bias in Turkish language models, exploring the types of gender stereotypes these models pick up on and common patterns of errors they make.
- The researchers analyze the language models' outputs to uncover biased associations between gender and certain traits, occupations, or activities.
- The goal is to better understand the nature of gender bias in Turkish natural language processing and inform the development of more inclusive and equitable AI systems.
Plain English Explanation
In this study, the researchers looked at how Turkish language models What is Your Favorite Gender? MLM Gender reflect and perpetuate gender stereotypes. They wanted to see what kinds of biased ideas the models have picked up on and the common mistakes they make when it comes to gender.
The researchers analyzed the outputs of these language models to find associations between gender and certain characteristics, jobs, or behaviors. For example, the models might associate women more with caregiving roles and men more with leadership positions. Investigating Markers and Drivers of Gender Bias in Machine Translations
By understanding the nature of this gender bias, the researchers hope to help develop Turkish AI systems that are more inclusive and fair, not perpetuating harmful stereotypes. Data Bias According to BiPoL: Men Are... This kind of work is important for ensuring that AI technology benefits people of all genders equally. IndiBias: A Benchmark Dataset to Measure Social Biases
Technical Explanation
The paper investigates gender bias in Turkish language models by analyzing their outputs for biased associations between gender and various attributes, occupations, and activities. Detecting Gender Bias in Course Evaluations
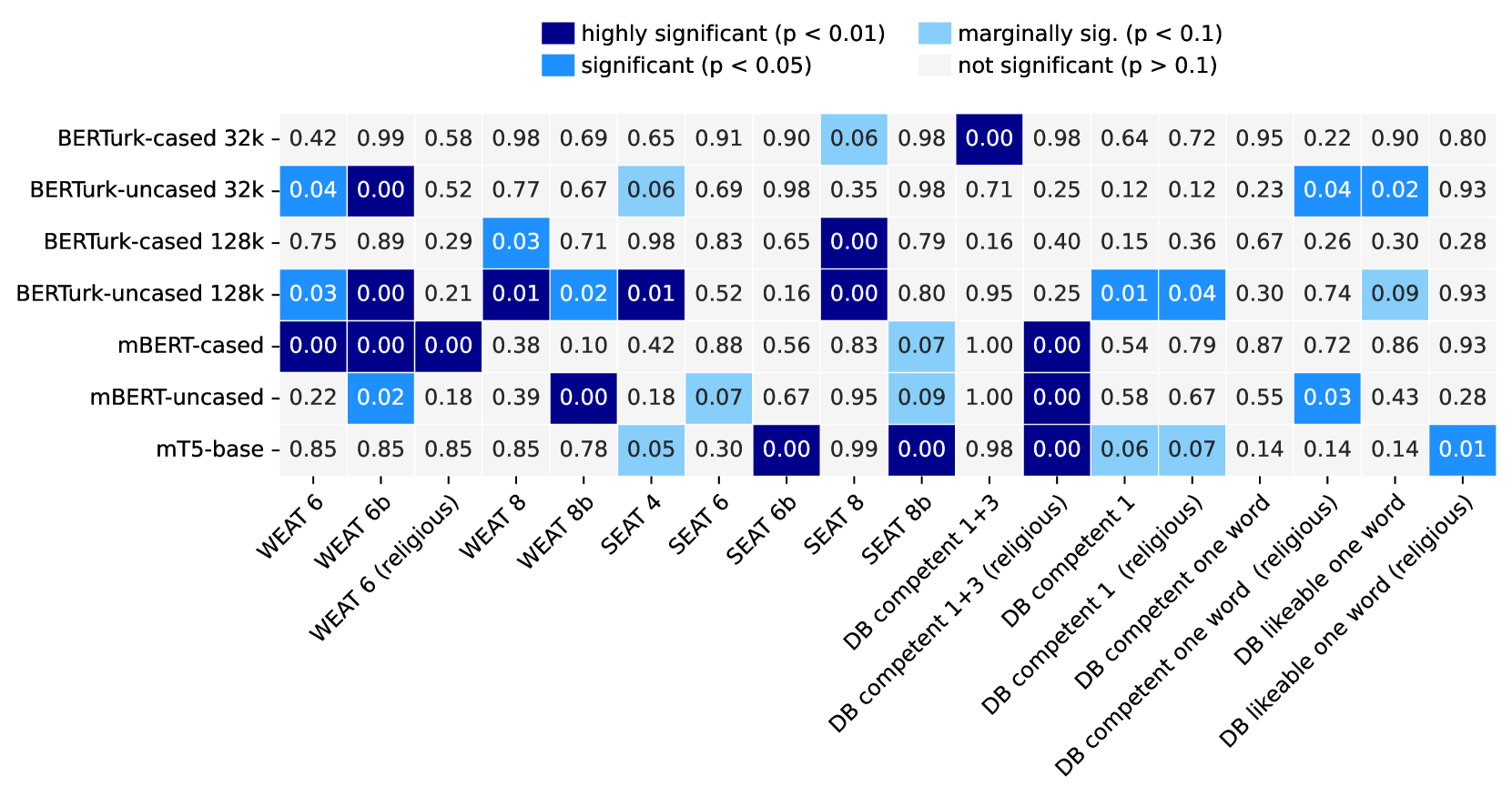
The researchers used several established techniques to measure gender bias, including the Word Embedding Association Test (WEAT) and the Relational Analogy Test (RAT). They applied these tests to popular Turkish language models, such as BERTurk and Multilin-gual BERT, to quantify the degree of gender bias present.
The analysis revealed that the language models exhibited significant gender stereotyping, associating women more strongly with nurturing and domestic roles, and men more strongly with leadership and professional positions. The models also made consistent errors in predicting gender-based word associations, further reinforcing these biases.
The paper discusses the implications of these findings for the development of more inclusive and equitable natural language processing systems in Turkish. The authors suggest that addressing gender bias in language models is a crucial step towards ensuring AI technology benefits all members of society equally.
Critical Analysis
The paper provides a thorough and rigorous investigation of gender bias in Turkish language models, using well-established evaluation techniques. The researchers' findings are concerning, as they demonstrate that these models have internalized harmful gender stereotypes that could perpetuate biases if deployed in real-world applications.
While the study is limited to the Turkish language, the issues it raises are likely to be relevant for language models in other languages as well. The authors acknowledge this and call for further research to explore gender bias in a more diverse range of natural language processing systems.
One potential limitation of the study is that it focuses primarily on quantitative measures of bias, without delving deeply into the qualitative nature of the biases observed. A more in-depth analysis of the specific types of stereotypes and errors made by the language models could provide additional insights to guide the development of debiasing strategies.
Additionally, the paper does not address the potential sources of the gender biases found in the language models, such as the biases present in the training data or the model architectures themselves. Investigating these underlying drivers of bias could help inform more targeted interventions to mitigate the problem.
Overall, this paper makes a valuable contribution to the growing body of research on gender bias in AI systems. The findings underscore the importance of rigorously evaluating language models for biases and proactively addressing them to ensure the development of fair and inclusive AI technologies.
Conclusion
The study on gender bias in Turkish language models highlights the concerning prevalence of gender stereotyping in these AI systems. The researchers' analysis reveals that popular Turkish language models exhibit strong associations between gender and certain traits, occupations, and activities, perpetuating harmful biases.
These findings have important implications for the development of natural language processing technologies in Turkey and beyond. Addressing gender bias in language models is crucial to ensure that AI systems benefit all members of society equally, regardless of their gender. Detecting Gender Bias in Course Evaluations
The authors call for further research to explore gender bias in a wider range of languages and to investigate the underlying drivers of these biases. By better understanding the nature and sources of gender stereotyping in language models, researchers and practitioners can work towards the creation of more inclusive and equitable AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Leveraging Large Language Models to Measure Gender Bias in Gendered Languages
Erik Derner, Sara Sansalvador de la Fuente, Yoan Guti'errez, Paloma Moreda, Nuria Oliver
0
0
Gender bias in text corpora used in various natural language processing (NLP) contexts, such as for training large language models (LLMs), can lead to the perpetuation and amplification of societal inequalities. This is particularly pronounced in gendered languages like Spanish or French, where grammatical structures inherently encode gender, making the bias analysis more challenging. Existing methods designed for English are inadequate for this task due to the intrinsic linguistic differences between English and gendered languages. This paper introduces a novel methodology that leverages the contextual understanding capabilities of LLMs to quantitatively analyze gender representation in Spanish corpora. By utilizing LLMs to identify and classify gendered nouns and pronouns in relation to their reference to human entities, our approach provides a nuanced analysis of gender biases. We empirically validate our method on four widely-used benchmark datasets, uncovering significant gender disparities with a male-to-female ratio ranging from 4:1 to 6:1. These findings demonstrate the value of our methodology for bias quantification in gendered languages and suggest its application in NLP, contributing to the development of more equitable language technologies.
6/21/2024

Are Models Biased on Text without Gender-related Language?
Catarina G Bel'em, Preethi Seshadri, Yasaman Razeghi, Sameer Singh
0
0
Gender bias research has been pivotal in revealing undesirable behaviors in large language models, exposing serious gender stereotypes associated with occupations, and emotions. A key observation in prior work is that models reinforce stereotypes as a consequence of the gendered correlations that are present in the training data. In this paper, we focus on bias where the effect from training data is unclear, and instead address the question: Do language models still exhibit gender bias in non-stereotypical settings? To do so, we introduce UnStereoEval (USE), a novel framework tailored for investigating gender bias in stereotype-free scenarios. USE defines a sentence-level score based on pretraining data statistics to determine if the sentence contain minimal word-gender associations. To systematically benchmark the fairness of popular language models in stereotype-free scenarios, we utilize USE to automatically generate benchmarks without any gender-related language. By leveraging USE's sentence-level score, we also repurpose prior gender bias benchmarks (Winobias and Winogender) for non-stereotypical evaluation. Surprisingly, we find low fairness across all 28 tested models. Concretely, models demonstrate fair behavior in only 9%-41% of stereotype-free sentences, suggesting that bias does not solely stem from the presence of gender-related words. These results raise important questions about where underlying model biases come from and highlight the need for more systematic and comprehensive bias evaluation. We release the full dataset and code at https://ucinlp.github.io/unstereo-eval.
5/2/2024

Evaluation of Large Language Models: STEM education and Gender Stereotypes
Smilla Due, Sneha Das, Marianne Andersen, Berta Plandolit L'opez, Sniff Andersen Nex{o}, Line Clemmensen
0
0
Large Language Models (LLMs) have an increasing impact on our lives with use cases such as chatbots, study support, coding support, ideation, writing assistance, and more. Previous studies have revealed linguistic biases in pronouns used to describe professions or adjectives used to describe men vs women. These issues have to some degree been addressed in updated LLM versions, at least to pass existing tests. However, biases may still be present in the models, and repeated use of gender stereotypical language may reinforce the underlying assumptions and are therefore important to examine further. This paper investigates gender biases in LLMs in relation to educational choices through an open-ended, true to user-case experimental design and a quantitative analysis. We investigate the biases in the context of four different cultures, languages, and educational systems (English/US/UK, Danish/DK, Catalan/ES, and Hindi/IN) for ages ranging from 10 to 16 years, corresponding to important educational transition points in the different countries. We find that there are significant and large differences in the ratio of STEM to non-STEM suggested education paths provided by chatGPT when using typical girl vs boy names to prompt lists of suggested things to become. There are generally fewer STEM suggestions in the Danish, Spanish, and Indian context compared to the English. We also find subtle differences in the suggested professions, which we categorise and report.
6/17/2024
What is Your Favorite Gender, MLM? Gender Bias Evaluation in Multilingual Masked Language Models
Jeongrok Yu, Seong Ug Kim, Jacob Choi, Jinho D. Choi
0
0
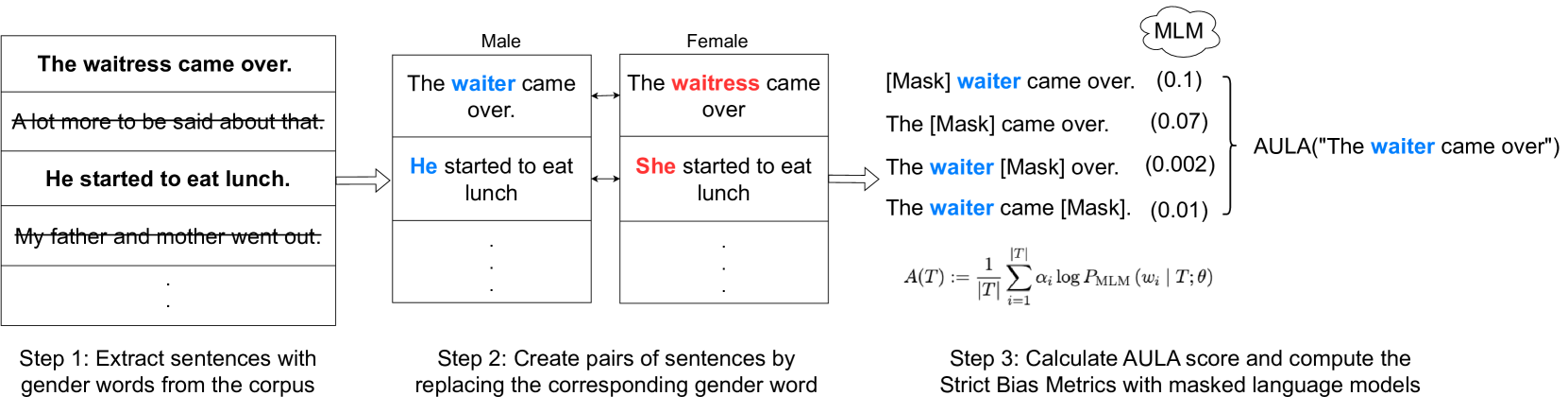
Bias is a disproportionate prejudice in favor of one side against another. Due to the success of transformer-based Masked Language Models (MLMs) and their impact on many NLP tasks, a systematic evaluation of bias in these models is needed more than ever. While many studies have evaluated gender bias in English MLMs, only a few works have been conducted for the task in other languages. This paper proposes a multilingual approach to estimate gender bias in MLMs from 5 languages: Chinese, English, German, Portuguese, and Spanish. Unlike previous work, our approach does not depend on parallel corpora coupled with English to detect gender bias in other languages using multilingual lexicons. Moreover, a novel model-based method is presented to generate sentence pairs for a more robust analysis of gender bias, compared to the traditional lexicon-based method. For each language, both the lexicon-based and model-based methods are applied to create two datasets respectively, which are used to evaluate gender bias in an MLM specifically trained for that language using one existing and 3 new scoring metrics. Our results show that the previous approach is data-sensitive and not stable as it does not remove contextual dependencies irrelevant to gender. In fact, the results often flip when different scoring metrics are used on the same dataset, suggesting that gender bias should be studied on a large dataset using multiple evaluation metrics for best practice.
4/11/2024