Towards detecting unanticipated bias in Large Language Models

0

Sign in to get full access
Overview
- The paper aims to detect "unanticipated bias" in large language models (LLMs), which are AI systems trained on vast amounts of text data.
- Unanticipated bias refers to unintended biases that emerge in LLMs, beyond the known biases that have been studied.
- The researchers propose methods to identify and characterize these hard-to-detect biases in LLMs.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, answer questions, and complete a variety of language-related tasks. However, these models can also pick up and perpetuate biases present in the data they are trained on, leading to unfair or problematic outputs.
The researchers in this paper recognize that there may be biases in LLMs that are difficult to anticipate or identify upfront. They refer to these as "unanticipated biases." For example, an LLM might exhibit biases against certain demographic groups in ways that are not obvious or easily detectable.
To address this, the researchers propose methods to systematically uncover and analyze these hard-to-detect biases. By doing so, they hope to make LLMs more transparent and accountable, and to ultimately improve their fairness and reliability.
The key idea is to probe the LLMs in various ways to surface biases that may be lurking beneath the surface. This could involve feeding the models carefully crafted prompts, analyzing their outputs for patterns of bias, and measuring their uncertainty or "confidence" in potentially biased responses.
Ultimately, the goal is to develop a better understanding of the biases present in these powerful AI systems, so that steps can be taken to mitigate them and ensure LLMs are used in equitable and responsible ways.
Technical Explanation
The paper begins by reviewing the current state of research on bias and fairness in large language models (LLMs). The authors note that while significant progress has been made in identifying and addressing known biases, there is a growing recognition that LLMs may exhibit more subtle, "unanticipated" biases that are difficult to detect.
To address this, the researchers propose a multi-pronged approach:
-
Probing Techniques: They develop methods to systematically probe LLMs with carefully designed prompts, in order to surface potential biases that may not be evident from standard evaluation tasks.
-
Uncertainty Modeling: The researchers hypothesize that LLMs may express higher uncertainty or "lack of confidence" when generating outputs that involve unanticipated biases. They explore techniques to measure and analyze this uncertainty.
-
Explainability Analysis: The paper also investigates ways to generate explanations for the LLM's outputs, to better understand the reasoning behind potentially biased responses.
Through a series of experiments on popular LLMs like GPT-3, the researchers demonstrate the effectiveness of their proposed techniques in uncovering various types of unanticipated biases, including biases related to gender, race, and socioeconomic status.
Critical Analysis
The paper makes a valuable contribution by highlighting the importance of going beyond known biases and developing more comprehensive strategies to uncover the subtle, hard-to-detect biases that may exist in large language models.
One key strength of the research is the focus on using the models' own "uncertainty" or "confidence" levels as a signal for potential biases. This is an insightful approach, as it leverages an inherent characteristic of LLMs to shed light on their internal decision-making processes.
However, the paper also acknowledges some limitations of the proposed methods. For example, the probing techniques rely on carefully crafted prompts, which may not be exhaustive or representative of real-world use cases. Additionally, the explainability analysis, while promising, is still an active area of research with challenges around the fidelity and interpretability of the generated explanations.
It would be valuable for future work to further evaluate the robustness and generalizability of the proposed techniques, perhaps by testing them on a wider range of LLMs and use cases. Researchers could also explore ways to make the bias detection process more automated and scalable, to enable more comprehensive auditing of these complex AI systems.
Conclusion
This paper represents an important step forward in the ongoing effort to address bias and fairness issues in large language models. By proposing methods to systematically uncover "unanticipated biases," the researchers are helping to expand our understanding of the potential pitfalls and challenges associated with these powerful AI systems.
Ultimately, the goal is to make LLMs more transparent, accountable, and equitable, so that they can be leveraged for the benefit of society. The techniques outlined in this paper, along with continued research in this area, will be crucial in realizing this vision and ensuring the responsible development and deployment of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards detecting unanticipated bias in Large Language Models
Anna Kruspe
Over the last year, Large Language Models (LLMs) like ChatGPT have become widely available and have exhibited fairness issues similar to those in previous machine learning systems. Current research is primarily focused on analyzing and quantifying these biases in training data and their impact on the decisions of these models, alongside developing mitigation strategies. This research largely targets well-known biases related to gender, race, ethnicity, and language. However, it is clear that LLMs are also affected by other, less obvious implicit biases. The complex and often opaque nature of these models makes detecting such biases challenging, yet this is crucial due to their potential negative impact in various applications. In this paper, we explore new avenues for detecting these unanticipated biases in LLMs, focusing specifically on Uncertainty Quantification and Explainable AI methods. These approaches aim to assess the certainty of model decisions and to make the internal decision-making processes of LLMs more transparent, thereby identifying and understanding biases that are not immediately apparent. Through this research, we aim to contribute to the development of fairer and more transparent AI systems.
Read more4/4/2024
💬
0
Bias and Fairness in Large Language Models: A Survey
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, Nesreen K. Ahmed
Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.
Read more7/16/2024
💬
0
Uncovering Biases with Reflective Large Language Models
Edward Y. Chang
Biases inherent in human endeavors pose significant challenges for machine learning, particularly in supervised learning that relies on potentially biased ground truth data. This reliance, coupled with models' tendency to generalize based on statistical maximal likelihood, can propagate and amplify biases, exacerbating societal issues. To address this, our study proposes a reflective methodology utilizing multiple Large Language Models (LLMs) engaged in a dynamic dialogue to uncover diverse perspectives. By leveraging conditional statistics, information theory, and divergence metrics, this novel approach fosters context-dependent linguistic behaviors, promoting unbiased outputs. Furthermore, it enables measurable progress tracking and explainable remediation actions to address identified biases.
Read more8/27/2024
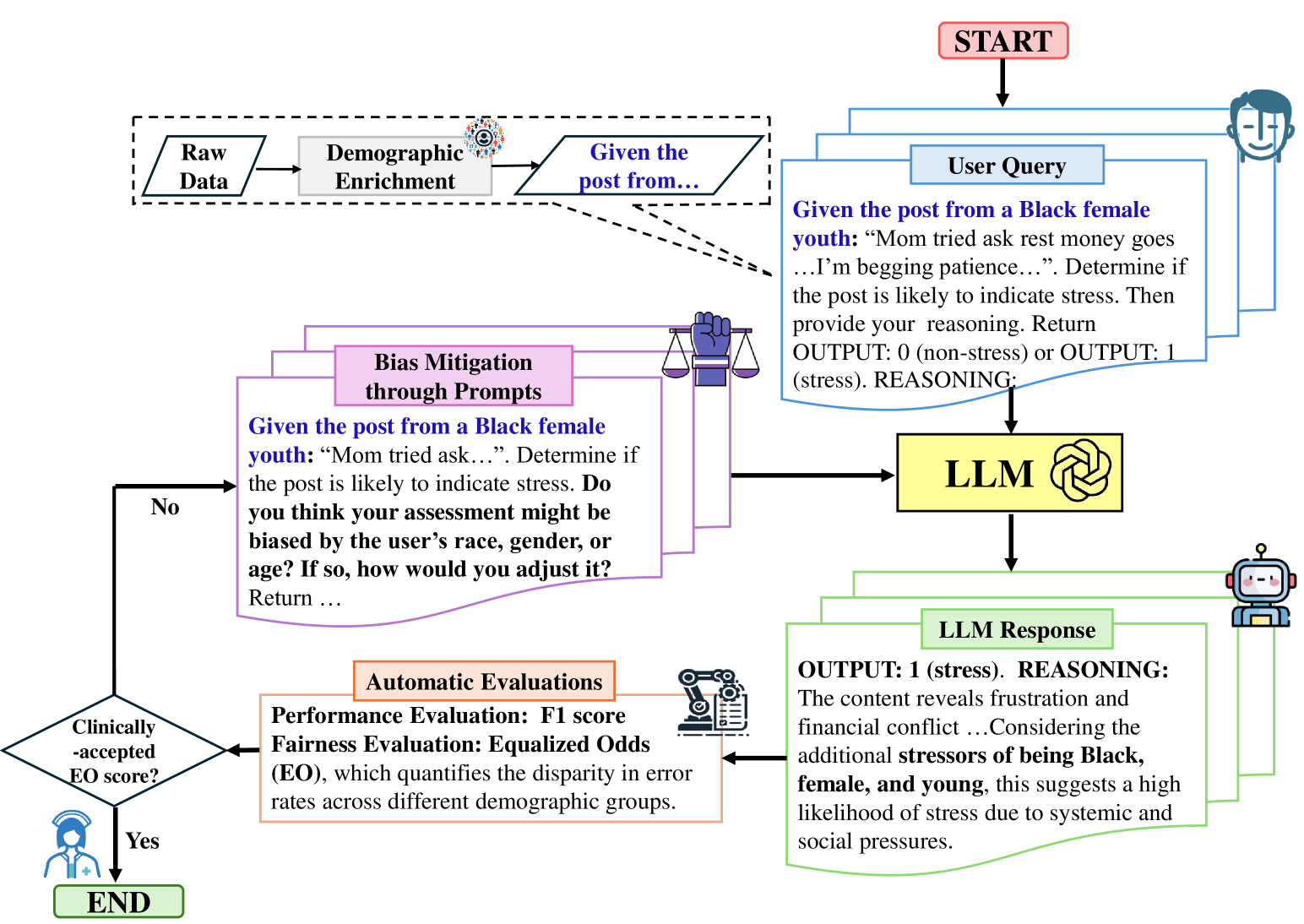
0
Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
Yuqing Wang, Yun Zhao, Sara Alessandra Keller, Anne de Hond, Marieke M. van Buchem, Malvika Pillai, Tina Hernandez-Boussard
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
Read more6/21/2024