Investigating Robustness of Open-Vocabulary Foundation Object Detectors under Distribution Shifts
2405.14874
0
0
👁️
Abstract
The challenge of Out-Of-Distribution (OOD) robustness remains a critical hurdle towards deploying deep vision models. Open-vocabulary object detection extends the capabilities of traditional object detection frameworks to recognize and classify objects beyond predefined categories. Investigating OOD robustness in open-vocabulary object detection is essential to increase the trustworthiness of these models. This study presents a comprehensive robustness evaluation of zero-shot capabilities of three recent open-vocabulary foundation object detection models, namely OWL-ViT, YOLO World, and Grounding DINO. Experiments carried out on the COCO-O and COCO-C benchmarks encompassing distribution shifts highlight the challenges of the models' robustness. Source code shall be made available to the research community on GitHub.
Create account to get full access
Overview
- The paper explores the challenge of Out-of-Distribution (OOD) robustness, which is a critical hurdle in deploying deep vision models.
- It investigates the OOD robustness of three recent open-vocabulary object detection models: OWL-ViT, YOLO World, and Grounding DINO.
- The experiments are conducted on the COCO-O and COCO-C benchmarks, which encompass distribution shifts, to highlight the challenges of the models' robustness.
- The source code will be made available on GitHub for the research community.
Plain English Explanation
Object detection is a crucial task in computer vision, where AI models can identify and classify objects in images. However, these models often struggle when faced with objects that are outside of their predefined training categories, a problem known as Out-of-Distribution (OOD) robustness.
To address this challenge, researchers have developed open-vocabulary object detection models, which can recognize and classify objects beyond the traditional fixed categories. These models have the potential to be more versatile and adaptable, but their OOD robustness remains a concern.
This study takes a closer look at the OOD robustness of three recent open-vocabulary object detection models: OWL-ViT, YOLO World, and Grounding DINO. The researchers tested these models on the COCO-O and COCO-C benchmarks, which are designed to simulate real-world distribution shifts that the models might encounter.
The results of these experiments highlight the challenges these models face when it comes to OOD robustness. Understanding these challenges is crucial for improving the trustworthiness and reliability of open-vocabulary object detection systems, which could have significant implications for various applications, such as autonomous vehicles and medical imaging.
Technical Explanation
The paper presents a comprehensive robustness comparison of the zero-shot capabilities of three recent open-vocabulary foundation object detection models: OWL-ViT, YOLO World, and Grounding DINO. These models are designed to extend the capabilities of traditional object detection frameworks by recognizing and classifying objects beyond predefined categories.
The researchers conducted experiments on the COCO-O and COCO-C benchmarks, which introduce various distribution shifts, such as image corruptions and perturbations, to assess the OOD robustness of the models. The COCO-O benchmark focuses on evaluating open-vocabulary object detection performance, while the COCO-C benchmark tests the models' ability to handle common image corruptions.
By evaluating the models' performance on these benchmarks, the researchers were able to identify the challenges and limitations of the current state-of-the-art open-vocabulary object detection systems. The findings from this study can inform the development of more robust and trustworthy models, which is essential for deploying these systems in real-world applications.
Critical Analysis
The paper provides a valuable contribution to the field of open-vocabulary object detection by highlighting the challenges of OOD robustness. The researchers have chosen a comprehensive set of benchmarks that simulate real-world distribution shifts, which is a crucial step towards realistic OOD evaluation.
However, the paper does not delve into the potential reasons for the models' lack of OOD robustness. A deeper analysis of the underlying architectural choices, training strategies, or data biases that may be contributing to the observed performance gaps would have provided more insights for improving these models.
Additionally, the paper could have discussed the potential trade-offs between open-vocabulary capabilities and OOD robustness. It is possible that the models' ability to recognize a broader range of objects may come at the cost of reduced robustness to distribution shifts. Exploring this balance could inform the design of more robust and versatile object detection systems.
Conclusion
This study presents a comprehensive evaluation of the OOD robustness of three recent open-vocabulary object detection models: OWL-ViT, YOLO World, and Grounding DINO. The experiments on the COCO-O and COCO-C benchmarks highlight the challenges these models face in maintaining their zero-shot capabilities under distribution shifts.
The findings from this research are crucial for increasing the trustworthiness and reliability of open-vocabulary object detection systems, which could have significant implications for various applications, such as autonomous vehicles, medical imaging, and beyond. By making the source code available to the research community, the authors have paved the way for further advancements in this important field of computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
The devil is in the fine-grained details: Evaluating open-vocabulary object detectors for fine-grained understanding
Lorenzo Bianchi, Fabio Carrara, Nicola Messina, Claudio Gennaro, Fabrizio Falchi
0
0
Recent advancements in large vision-language models enabled visual object detection in open-vocabulary scenarios, where object classes are defined in free-text formats during inference. In this paper, we aim to probe the state-of-the-art methods for open-vocabulary object detection to determine to what extent they understand fine-grained properties of objects and their parts. To this end, we introduce an evaluation protocol based on dynamic vocabulary generation to test whether models detect, discern, and assign the correct fine-grained description to objects in the presence of hard-negative classes. We contribute with a benchmark suite of increasing difficulty and probing different properties like color, pattern, and material. We further enhance our investigation by evaluating several state-of-the-art open-vocabulary object detectors using the proposed protocol and find that most existing solutions, which shine in standard open-vocabulary benchmarks, struggle to accurately capture and distinguish finer object details. We conclude the paper by highlighting the limitations of current methodologies and exploring promising research directions to overcome the discovered drawbacks. Data and code are available at https://lorebianchi98.github.io/FG-OVD/.
4/9/2024
🌀
Unexplored Faces of Robustness and Out-of-Distribution: Covariate Shifts in Environment and Sensor Domains
Eunsu Baek, Keondo Park, Jiyoon Kim, Hyung-Sin Kim
0
0
Computer vision applications predict on digital images acquired by a camera from physical scenes through light. However, conventional robustness benchmarks rely on perturbations in digitized images, diverging from distribution shifts occurring in the image acquisition process. To bridge this gap, we introduce a new distribution shift dataset, ImageNet-ES, comprising variations in environmental and camera sensor factors by directly capturing 202k images with a real camera in a controllable testbed. With the new dataset, we evaluate out-of-distribution (OOD) detection and model robustness. We find that existing OOD detection methods do not cope with the covariate shifts in ImageNet-ES, implying that the definition and detection of OOD should be revisited to embrace real-world distribution shifts. We also observe that the model becomes more robust in both ImageNet-C and -ES by learning environment and sensor variations in addition to existing digital augmentations. Lastly, our results suggest that effective shift mitigation via camera sensor control can significantly improve performance without increasing model size. With these findings, our benchmark may aid future research on robustness, OOD, and camera sensor control for computer vision. Our code and dataset are available at https://github.com/Edw2n/ImageNet-ES.
4/26/2024
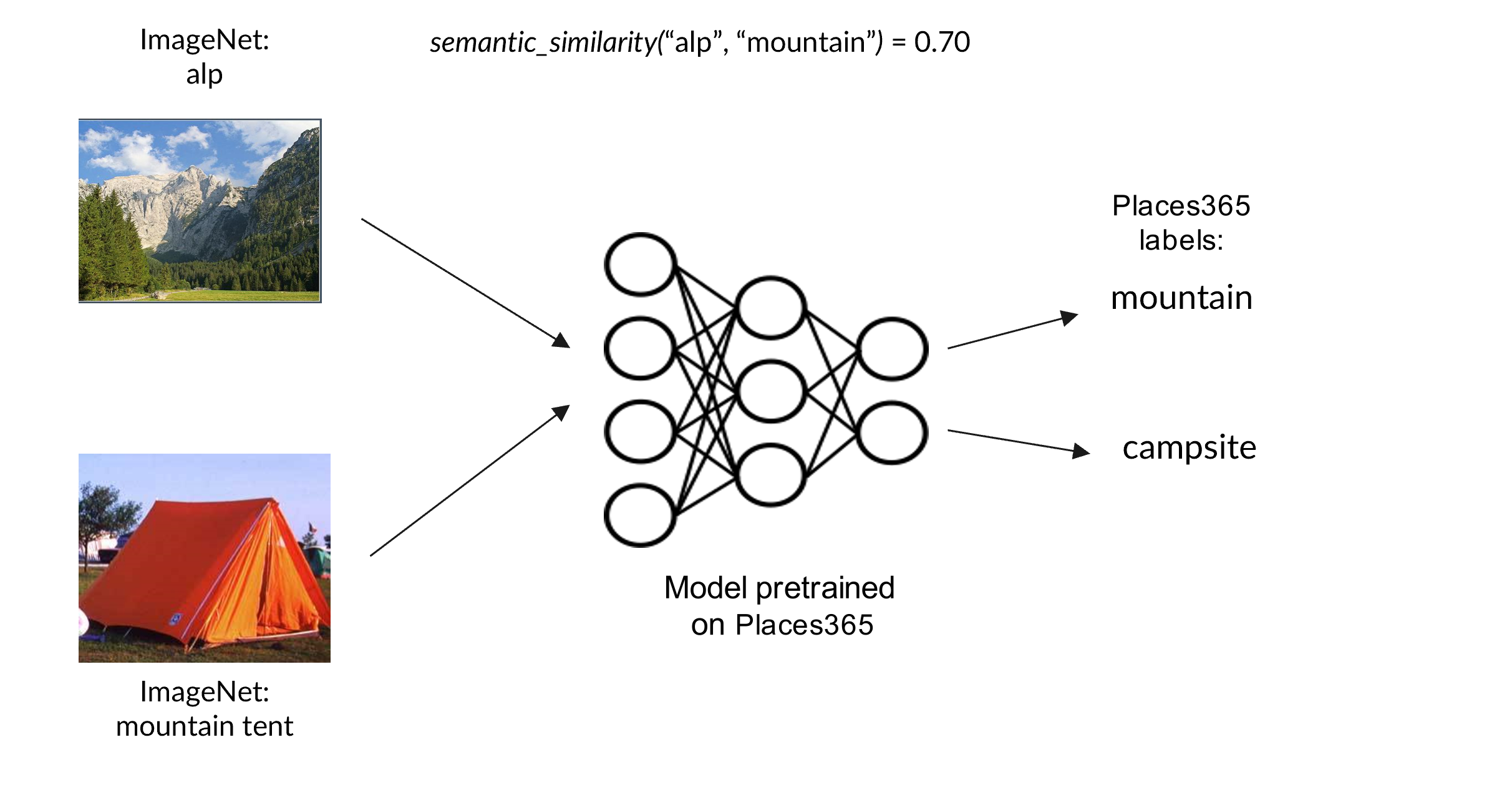
Toward a Realistic Benchmark for Out-of-Distribution Detection
Pietro Recalcati, Fabio Garcea, Luca Piano, Fabrizio Lamberti, Lia Morra
0
0
Deep neural networks are increasingly used in a wide range of technologies and services, but remain highly susceptible to out-of-distribution (OOD) samples, that is, drawn from a different distribution than the original training set. A common approach to address this issue is to endow deep neural networks with the ability to detect OOD samples. Several benchmarks have been proposed to design and validate OOD detection techniques. However, many of them are based on far-OOD samples drawn from very different distributions, and thus lack the complexity needed to capture the nuances of real-world scenarios. In this work, we introduce a comprehensive benchmark for OOD detection, based on ImageNet and Places365, that assigns individual classes as in-distribution or out-of-distribution depending on the semantic similarity with the training set. Several techniques can be used to determine which classes should be considered in-distribution, yielding benchmarks with varying properties. Experimental results on different OOD detection techniques show how their measured efficacy depends on the selected benchmark and how confidence-based techniques may outperform classifier-based ones on near-OOD samples.
4/17/2024

OV-DQUO: Open-Vocabulary DETR with Denoising Text Query Training and Open-World Unknown Objects Supervision
Junjie Wang, Bin Chen, Bin Kang, Yulin Li, YiChi Chen, Weizhi Xian, Huifeng Chang
0
0
Open-Vocabulary Detection (OVD) aims to detect objects from novel categories beyond the base categories on which the detector is trained. However, existing open-vocabulary detectors trained on known category data tend to assign higher confidence to trained categories and confuse novel categories with background. To resolve this, we propose OV-DQUO, an textbf{O}pen-textbf{V}ocabulary DETR with textbf{D}enoising text textbf{Q}uery training and open-world textbf{U}nknown textbf{O}bjects supervision. Specifically, we introduce a wildcard matching method that enables the detector to learn from pairs of unknown objects recognized by the open-world detector and text embeddings with general semantics, mitigating the confidence bias between base and novel categories. Additionally, we propose a denoising text query training strategy that synthesizes additional noisy query-box pairs from open-world unknown objects to trains the detector through contrastive learning, enhancing its ability to distinguish novel objects from the background. We conducted extensive experiments on the challenging OV-COCO and OV-LVIS benchmarks, achieving new state-of-the-art results of 45.6 AP50 and 39.3 mAP on novel categories respectively, without the need for additional training data. Models and code are released at https://github.com/xiaomoguhz/OV-DQUO
5/29/2024