Training-free Boost for Open-Vocabulary Object Detection with Confidence Aggregation

0
Sign in to get full access
Overview
- This paper presents a training-free method for improving open-vocabulary object detection models.
- The key innovation is a confidence aggregation technique that combines predictions from multiple object detection models to boost performance on unseen object classes.
- The method is shown to outperform state-of-the-art open-vocabulary object detection approaches on several benchmark datasets.
Plain English Explanation
Object detection is the task of identifying and locating objects in images. Traditionally, object detection models are trained on a fixed set of object classes, limiting their ability to recognize novel or unseen objects.
The Training-free Boost for Open-Vocabulary Object Detection with Confidence Aggregation paper proposes a new approach to address this challenge. Instead of training a single model, the method combines predictions from multiple object detection models to improve performance on unseen object classes.
The key idea is to aggregate the confidence scores from these different models, using a technique called "confidence aggregation." This allows the system to leverage the complementary strengths of the individual models, boosting the overall detection accuracy for unfamiliar objects.
The authors demonstrate that their training-free approach outperforms state-of-the-art open-vocabulary object detection methods on standard benchmark datasets. This is an important advancement, as it enables object detection models to be more flexible and adaptable to real-world scenarios where the set of objects to be detected may not be known in advance.
Technical Explanation
The Training-free Boost for Open-Vocabulary Object Detection with Confidence Aggregation paper introduces a novel technique for improving the performance of open-vocabulary object detection models.
The key innovation is a confidence aggregation method that combines predictions from multiple object detection models. The authors leverage pre-trained object detection models, each specialized in different object classes, and aggregate their confidence scores to boost performance on unseen object classes.
Specifically, the method works as follows:
- Model Selection: The authors select a set of pre-trained object detection models, each trained on a different dataset or with different architectural choices.
- Confidence Aggregation: For each input image, the system runs the selected object detection models and aggregates their confidence scores for each detected object. This is done using a weighted sum, where the weights are learned in a data-driven manner.
- Non-maximum Suppression and Thresholding: The aggregated confidence scores are then used to filter and refine the final object detections, with non-maximum suppression and confidence thresholding applied to produce the final output.
The authors evaluate their approach on several open-vocabulary object detection benchmarks, including COCO, Open Images, and Objectron. They show that their training-free confidence aggregation method outperforms state-of-the-art open-vocabulary object detection approaches, demonstrating the effectiveness of leveraging multiple pre-trained models to boost performance on unseen object classes.
Critical Analysis
The Training-free Boost for Open-Vocabulary Object Detection with Confidence Aggregation paper presents an innovative and practical approach to improving open-vocabulary object detection. The key strengths of the work include:
- Adaptability: By combining predictions from multiple pre-trained models, the method can adapt to a wide range of object classes without the need for resource-intensive retraining.
- Generalization: The authors demonstrate that their approach outperforms state-of-the-art open-vocabulary object detection methods on several benchmark datasets, indicating strong generalization capabilities.
- Simplicity: The confidence aggregation technique is relatively straightforward to implement and does not require complex training or architectural changes, making it easy to integrate into existing object detection pipelines.
However, the paper also has some potential limitations:
- Model Selection: The performance of the confidence aggregation method may be sensitive to the choice of pre-trained object detection models. The authors do not provide detailed guidance on how to select the most appropriate set of models.
- Computational Overhead: Running multiple object detection models on each input image may increase the computational cost and latency of the overall system, which could be a concern for real-time applications.
- Lack of Explainability: The paper does not provide much insight into how the confidence aggregation mechanism works or why it is effective. A more detailed analysis of the inner workings of the method could help users understand its strengths and limitations.
Overall, the Training-free Boost for Open-Vocabulary Object Detection with Confidence Aggregation paper represents a promising step towards more flexible and adaptable object detection systems. Further research could explore ways to address the identified limitations and provide a deeper understanding of the underlying mechanisms.
Conclusion
The Training-free Boost for Open-Vocabulary Object Detection with Confidence Aggregation paper presents a novel approach to improving open-vocabulary object detection performance. By leveraging multiple pre-trained object detection models and aggregating their confidence scores, the method can boost detection accuracy on unseen object classes without the need for resource-intensive retraining.
The authors demonstrate the effectiveness of their training-free confidence aggregation technique on several benchmark datasets, outperforming state-of-the-art open-vocabulary object detection methods. This is an important advancement, as it enables object detection systems to be more flexible and adaptable to real-world scenarios where the set of objects to be detected may not be known in advance.
While the paper has some potential limitations, such as the sensitivity to model selection and computational overhead, the core idea of combining the strengths of multiple pre-trained models is a promising direction for further research. Continued work in this area could lead to even more robust and versatile object detection systems, with broad applications in fields like autonomous driving, robotics, and visual understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Training-free Boost for Open-Vocabulary Object Detection with Confidence Aggregation
Yanhao Zheng, Kai Liu
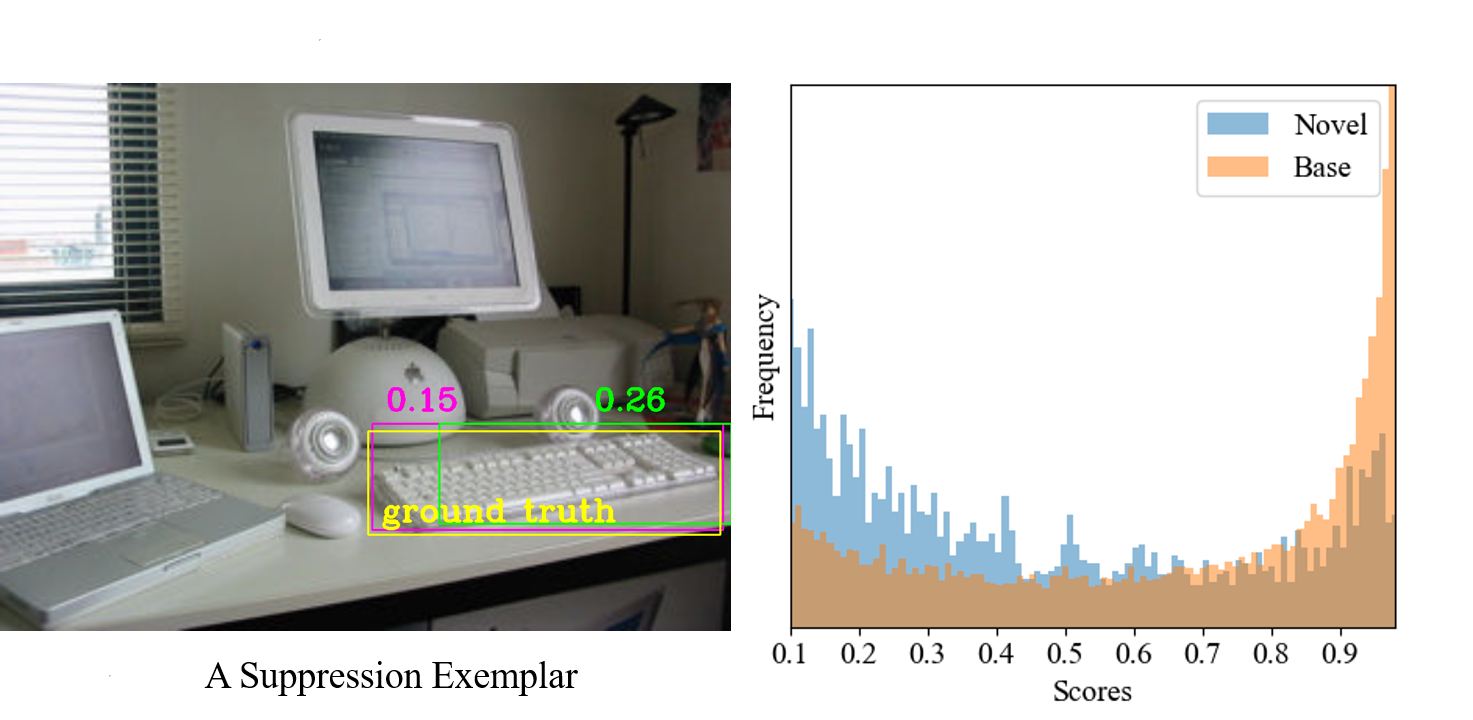
Open-vocabulary object detection (OVOD) aims at localizing and recognizing visual objects from novel classes unseen at the training time. Whereas, empirical studies reveal that advanced detectors generally assign lower scores to those novel instances, which are inadvertently suppressed during inference by commonly adopted greedy strategies like Non-Maximum Suppression (NMS), leading to sub-optimal detection performance for novel classes. This paper systematically investigates this problem with the commonly-adopted two-stage OVOD paradigm. Specifically, in the region-proposal stage, proposals that contain novel instances showcase lower objectness scores, since they are treated as background proposals during the training phase. Meanwhile, in the object-classification stage, novel objects share lower region-text similarities (i.e., classification scores) due to the biased visual-language alignment by seen training samples. To alleviate this problem, this paper introduces two advanced measures to adjust confidence scores and conserve erroneously dismissed objects: (1) a class-agnostic localization quality estimate via overlap degree of region/object proposals, and (2) a text-guided visual similarity estimate with proxy prototypes for novel classes. Integrated with adjusting techniques specifically designed for the region-proposal and object-classification stages, this paper derives the aggregated confidence estimate for the open-vocabulary object detection paradigm (AggDet). Our AggDet is a generic and training-free post-processing scheme, which consistently bolsters open-vocabulary detectors across model scales and architecture designs. For instance, AggDet receives 3.3% and 1.5% gains on OV-COCO and OV-LVIS benchmarks respectively, without any training cost.
Read more4/15/2024
🔎
0
LP-OVOD: Open-Vocabulary Object Detection by Linear Probing
Chau Pham, Truong Vu, Khoi Nguyen
This paper addresses the challenging problem of open-vocabulary object detection (OVOD) where an object detector must identify both seen and unseen classes in test images without labeled examples of the unseen classes in training. A typical approach for OVOD is to use joint text-image embeddings of CLIP to assign box proposals to their closest text label. However, this method has a critical issue: many low-quality boxes, such as over- and under-covered-object boxes, have the same similarity score as high-quality boxes since CLIP is not trained on exact object location information. To address this issue, we propose a novel method, LP-OVOD, that discards low-quality boxes by training a sigmoid linear classifier on pseudo labels retrieved from the top relevant region proposals to the novel text. Experimental results on COCO affirm the superior performance of our approach over the state of the art, achieving $textbf{40.5}$ in $text{AP}_{novel}$ using ResNet50 as the backbone and without external datasets or knowing novel classes during training. Our code will be available at https://github.com/VinAIResearch/LP-OVOD.
Read more6/4/2024

0
OV-DQUO: Open-Vocabulary DETR with Denoising Text Query Training and Open-World Unknown Objects Supervision
Junjie Wang, Bin Chen, Bin Kang, Yulin Li, YiChi Chen, Weizhi Xian, Huifeng Chang, Yong Xu
Open-vocabulary detection aims to detect objects from novel categories beyond the base categories on which the detector is trained. However, existing open-vocabulary detectors trained on base category data tend to assign higher confidence to trained categories and confuse novel categories with the background. To resolve this, we propose OV-DQUO, an textbf{O}pen-textbf{V}ocabulary DETR with textbf{D}enoising text textbf{Q}uery training and open-world textbf{U}nknown textbf{O}bjects supervision. Specifically, we introduce a wildcard matching method. This method enables the detector to learn from pairs of unknown objects recognized by the open-world detector and text embeddings with general semantics, mitigating the confidence bias between base and novel categories. Additionally, we propose a denoising text query training strategy. It synthesizes foreground and background query-box pairs from open-world unknown objects to train the detector through contrastive learning, enhancing its ability to distinguish novel objects from the background. We conducted extensive experiments on the challenging OV-COCO and OV-LVIS benchmarks, achieving new state-of-the-art results of 45.6 AP50 and 39.3 mAP on novel categories respectively, without the need for additional training data. Models and code are released at url{https://github.com/xiaomoguhz/OV-DQUO}
Read more8/22/2024
🔎
0
Toward Open Vocabulary Aerial Object Detection with CLIP-Activated Student-Teacher Learning
Yan Li, Weiwei Guo, Xue Yang, Ning Liao, Dunyun He, Jiaqi Zhou, Wenxian Yu
An increasingly massive number of remote-sensing images spurs the development of extensible object detectors that can detect objects beyond training categories without costly collecting new labeled data. In this paper, we aim to develop open-vocabulary object detection (OVD) technique in aerial images that scales up object vocabulary size beyond training data. The performance of OVD greatly relies on the quality of class-agnostic region proposals and pseudo-labels for novel object categories. To simultaneously generate high-quality proposals and pseudo-labels, we propose CastDet, a CLIP-activated student-teacher open-vocabulary object Detection framework. Our end-to-end framework following the student-teacher self-learning mechanism employs the RemoteCLIP model as an extra omniscient teacher with rich knowledge. By doing so, our approach boosts not only novel object proposals but also classification. Furthermore, we devise a dynamic label queue strategy to maintain high-quality pseudo labels during batch training. We conduct extensive experiments on multiple existing aerial object detection datasets, which are set up for the OVD task. Experimental results demonstrate our CastDet achieving superior open-vocabulary detection performance, e.g., reaching 46.5% mAP on VisDroneZSD novel categories, which outperforms the state-of-the-art open-vocabulary detectors by 21.0% mAP. To our best knowledge, this is the first work to apply and develop the open-vocabulary object detection technique for aerial images. The code is available at https://github.com/lizzy8587/CastDet.
Read more8/13/2024